1. 引言
1.1. 研究背景与意义
科学技术不断在变革,也就带动着我国的工业化进程迅速发展。但福祸相依,我国的碳排放量随之也在不断上升,生态环境不断恶化,极端天气频发的现象也越来越常见。众所周知,碳排放量过高会给人类和环境带来难以挽回的巨大灾难,例如海平面上升、荒漠化以及极端天气频发等,倘若其持续不断增长不仅会威胁到国家的能源安全以及人民的生命财产安全,而且会危害到整个地球的生态,造成人类毁灭,因此保护生态环境这一任务已经刻不容缓。为顺应全球低碳发展趋势,中国作为全球最大的发展中国家,要发挥大国作用,主动承担起低碳减排的任务,展现中国政府的大国风范和国际担当。我国制定了“3060”双碳减排政策,开启了减污降碳的新阶段,不过由于我国各个省份发展情况各异,空间地理位置不同,资源分布不均匀,导致我国各地区的碳排放量存在明显的区域异质性,因此需要因地制宜,制定适合各地区的减少碳排放的政策。
此外,实现碳中和绝非易事,需要政府、社会以及公民各方面的助力,要进行技术创新,政府需要多颁布相关政策与法律进行管理与监督。因此,探究导致碳排放量过高的各个因素具有重要意义,如何更加深度地挖掘致使碳排放量过高的因素,并就如何有效控制二氧化碳排放量提出行之有效的相关建议,不仅可以优化我国的节能减排政策,也更有助于尽早实现我国“碳达峰,碳中和”的伟大目标。
1.2. 文献综述
为实现“2030年‘碳达峰’、2060年‘碳中和’”的目标,第一要务就是控制碳排放量。对于有可能影响碳排放量的因素,国内外学者已做了不少的研究。
在国外,Salman等(2019)基于面板分位数回归,研究东盟国家进出口对碳排放的影响,此外还发现人口规模增大和能源强度提高会增加碳排放量,技术创新可以通过提高能源效率减少碳排放量 [1] ;Nguyen等(2020)基于G20部分国家的面板数据,采用固定效应分位数回归对碳排放量影响因素进行研究,结果表明,主要因素有:能源价格、外国直接投资、技术、创新支出和贸易开放 [2] ;Khan等(2020)基于CS-ARDL回归研究得出,贸易、收入、环境创新和可再生能源消耗对G7国家碳排放量有影响 [3] ;Nguyen等(2021)基于国家层面,采用DOLS和FMOLS对面板数据进行分析,研究发现,经济增长、金融发展、贸易开放等因素对碳排放量具有影响 [4] 。
在国内,王勇等(2019)基于门限-STIRPAT模型,对国内被分类为超大城市的城市的碳排放量的影响因素进行研究,最终发现人口、人均GDP和能源强度是主要因素,人口这一因素的影响效果最强 [5] ;唐赛等(2021)基于我国部分典型城市的相关数据,通过构建STIRPAT模型,研究碳排放量影响因素,最终发现人均收入水平和城市人口对碳排放量影响显著,同时对于部分城市,能源强度也对碳排放量起到不小的影响 [6] ;王兆峰等(2022)利用城市夜间灯光数据来研究长江经济带总体和各等级城市碳排放的时空演变及其影响因素,发现不仅长江经济带总体,且按大、中、小型区分的各等级城市的碳排放量也都呈现出波动上升趋势,而人口增长等因素也对碳排放量具有一定的影响 [7] ;杜海波等(2021)选择GDP、年末常住人口、城市人口占总人口比重以及能源强度等7个因素,研究发现,经济发展水平、城镇化水平与人口规模对碳排放的驱动作用明显 [8] ;周一凡等(2022)基于县域角度,利用空间面板模型对来研究能够影响河北省农业碳排放的因素,发现主要的影响因素有:农业经济发展、产业结构以及农民收入等 [9] ;潘喜莲等(2021)基于空间计量经济模型(混合回归和固定效应模型),从全国和省级两个角度出发,研究人均二氧化碳排放量的影响因素,包括人均能源消费、能源结构等因素 [10] 。
上述文献基于不同的角度与方法研究影响碳排放量的因素,得出的结论也不尽相同。但总体上来说,人口数、人均GDP、能源结构、能源强度等都对碳排放量有不小的影响。因此,本文将在此基础上,再加入对外开放度、外商直接投资、产业结构、政策等因素,基于面板分位数回归,对我国30个省(除西藏自治区外) 2010~2019年碳排放量进行分析,再进一步采用随机森林探究各因素的重要性。本文的创新点在于:研究的变量较为全面,且加入了《环保税法》这一政策变量;采用了面板分位数回归,按照“低碳”、“中碳”和“高碳”将全国30个省划分为三类,以了解碳排放的影响因素;采用随机森林算法对因素重要性进行排序,以进一步了解各因素对碳排放量的影响程度。
2. 研究方法与模型构建
2.1. 研究方法
本文基于面板分位数回归探究了不同地区影响碳排放量的重要因素,将碳排放量按照不同的分位点(0.3, 0.5, 0.7)分别分成低碳、中碳、高碳地区,以了解变量在未来一段时期对不同地区碳排放量的影响。
传统的回归模型实质上是均值回归,其不足以全面展示因变量条件分布的状况,且在存在极端值的情况下,模型效果易受到影响。而分位数回归则解决了该问题,这一模型基于传统回归模型,融入分位数的概念,能够分析因变量处于不同的分位点时的条件分布情况,这样所得到的参数也能够更好地描绘模型,且具有稳健性。因此,本文基于面板数据,构建面板分位数回归模型进行分析。
随机森林一般是通过自助法抽样的方式建立多个决策树,从而对变量的重要性进行判别或分类的一种数据分析方法,根据目标变量类型的不同可以分为两类,一类是目标变量为分组变量时,用来预测其准确性,另一类则是预测其他变量对目标变量的重要性以及各个变量所起的作用。优点在于运行速度较快,能够有效处理非线性、交互作用、具有相关性的数据,也是一种降维的手段,可以处理数据当中的异常值和缺失值。其操作方法是当一个新的样本数据出现时,在分类时用我们所得到的每一颗决策树对其进行判断,用投票的方式决定其最终属于哪一类,而在回归时其结果则是我们所有决策树的平均值。
2.2. 模型构建
本文的变量选择方法基于STIRPAT模型,这一模型是传统IPAC模型的变形,IPAT模型的基本形式如公式(1)所示:
(1)
其中,I来代表环境压力,P、A、T分别表示人口规模、经济水平和技术水平,a表示模型系数,b、c、d是对应变量的弹性系数,e表示误差项。而York等人提出,在该模型之上取对数,更利于后续的检验与数据分析。在此基础上,本文还添加了结构因素和政策因素。将碳排放量作为环境压力;将总人口和城镇化率包含在人口规模中;经济水平包括人均GDP、对外开放度和FDI;技术水平包括能源强度;结构因素又分为产业结构和能源结构;政策因素表示《环保税法》(具体变量解释见表1),拓展的模型如下所示:
(2)
本文利用面板数据与分位数回归模型相结合,可以更好地利用面板数据的优势,有效地控制不同个体之间的异质性,又可以较好地研究自变量对处于不同分位点的因变量的影响,分位数回归的一般形式(τ为对应的分位点)为:
(3)
其中,
,i表示第i个个体,t表示第t时期。
在对面板数据完成进一步的检验后,发现模型具有固定效应,再结合STIRPAT模型与分位数回归,得到最终模型如下:
(4)
2.3. 数据来源
本文选取了2010年至2019年全国30个省、市、自治区(除西藏自治区)的数据。从CEADs碳排放数据库中收录了碳排放量数据。能源消费总量、煤炭消费量等数据从《中国能源统计年鉴》及各省的《能源统计年鉴》(2011~2020)中收录。总人口、GDP、第二产业增加值等数据收集自《中国统计年鉴》(2011~2020);由于原始数据中部分年份的进出口总额单位为万美元,因此利用同年人民币对美元的平均汇率对该值进行了折算。FDI数据来源于各省《统计年鉴》。同时,将《环保税法》设置成0~1虚拟变量,2010~2016年为0,2017~2019年为1。此外,吉林省缺失了2019年FDI数据,本文运用插值法对缺失数据进行了处理。
3. 描述性统计分析
全球碳排放量呈上升趋势,做到低碳排放以保护地球,已成为世界多数国家的共识。而从全国层面来看,40多年来,中国经济一直在飞速发展,但与此同时,随着我国工业化的加速,不可避免地使得我国二氧化碳排放量呈现出持续上升的趋势。2017年,在十九大报告中习近平同志指出,要坚持人与自然和谐共生。2021年通过的第十四个五年规划(以下简称“十四五规划”)更将绿色经济看作重中之重,第十一章、三十七章、三十八章和三十九章都提到了这一议题。控制碳排放量,已经是我国一个刻不容缓的议题。
本文从2010~2019年间全国30个省份的碳排放总量概况分布(如图1)可以直观地发现,山西省在这十年间的总碳排放量是全国各省中最高的,而山东省位列第二,这主要是由于两个省份都是我国的能源生产和消费省,煤炭资源富足,并且经济发展也离不开以煤炭为主的重工业,但不置可否,重工业会导致二氧化碳排放量加剧,这也就使得这些省份的碳排放量高居不下。内蒙古自治区的碳排放量也不容小觑,这不仅是因为其储量丰富的煤炭和低廉的电价,内蒙古是我国畜牧业较为发达的省份之一,2020年牛肉产量高达66.3万吨,位居全国第一。而牛在反刍过程中释放出大量的甲烷和二氧化碳,也在无形中加剧了二氧化碳的排放。江苏、河北等省份碳排放量次之。
再对2010年和2019年全国各省碳排放量绘制莫兰散点图(图2、图3)。从图2和图3可以了解从2010年到2019年,各省份的碳排放量呈现出聚集性和地区差异性,即相邻省份的碳排放量具有相似性,但各地区(东部、西部、中部)的碳排放量不同。其中,东部和东南部地区碳排放量在2010及2019年均处于较高的水平,而西部和西南部地区碳排放量均处于较低的水平。
总的来说,碳排放量较多的省份集中在东部与东南部地区,而西部与西南部地区碳排放量相对较低。
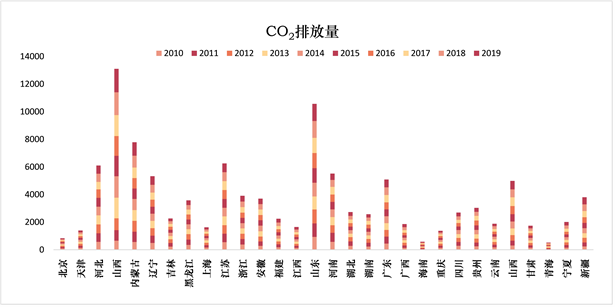
Figure 1. Overall carbon emission chart (Unit: 10,000 tons)
图1. 总体碳排放量图(单位:万吨)
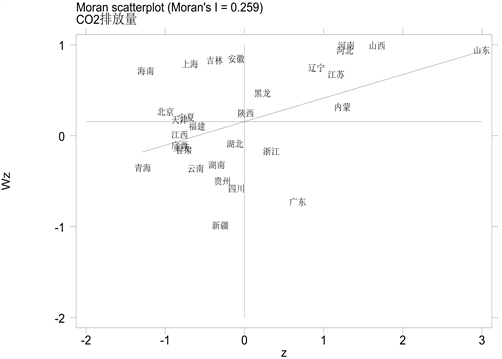
Figure 2. Moran scatter chart of national carbon emissions by provinces in 2010
图2. 2010年全国各省碳排放量莫兰散点图
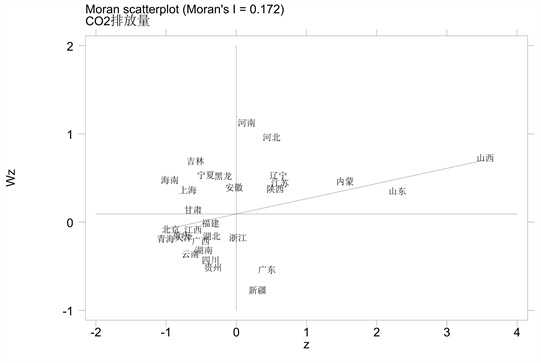
Figure 3. Moran scatter chart of national carbon emissions by provinces in 2019
图3. 2019年全国各省碳排放量莫兰散点图
4. 实证分析
4.1. 面板单位根检验
首先对各变量进行了描述性统计分析,如表2所示。在构建回归模型之前,为避免非平稳序列数据中存在的伪回归问题,需要对各变量进行面板单位根检验。本文所使用的是短面板数据集,即数据的时间维度小于其横截面维度,因此利用HT检验来进行单位根检验。由于政策变量是虚拟变量,无需进行单位根检验,因此利用Stata软件对其余变量做单位根检验。结果如表3所示,所有变量在未差分时都是不平稳的,因此需要对这些变量做差分处理,而经过二阶差分后,变量序列均是平稳的。

Table 2. Descriptive statistics of each variable
表2. 各变量描述性统计
Table 3. Panel unit root test results
表3. 面板单位根检验结果
4.2. 协整检验
根据上述结果,由于所有变量在二阶差分后达到平稳,也就是二阶单整,进一步利用协整检验来判断上述变量之间的长期均衡关系。本文基于三种方法进行协整检验,结果如表4所示。根据协整检验的结果,可以得出碳排放量、总人口、城镇化、产业结构、能源结构、能源强度、对外贸易等变量之间存在协整关系,则说明基于此变量构建的模型将不存在伪回归的问题。
Table 4. Cointegration test results
表4. 协整检验结果
4.3. 回归模型选取
通过单位根检验和协整检验,自变量与因变量之间的协整关系得到了证实,说明基于此数据构建的模型不是伪回归模型。接下来将构建回归模型对碳排放量影响因素进行探究。首先,建立传统的面板回归模型,一般可通过F检验、BP检验和Hausman检验来进行模型的选取。利用F检验来验证固定效应模型和混合回归模型的性能,通过BP检验来对比随机效应模型和混合回归模型的好坏,而Hausman检验可用于比较固定效应模型与随机效应模型。本文采用Stata软件进行以上三种检验,结果如表5所示。可以看出,三种检验的p值均为0,则均拒绝原假设。综合分析,最终选取固定效应模型。
Table 5. Selection results of regression model
表5. 回归模型选取结果
其次,构建面板分位数回归模型,模型如公式(4)所示。其中,将分位点设置为0.3、0.5、0.7,以描述三种不同程度(低、中、高)的碳排放量。
4.4. 回归结果分析
本文采用Stata软件对固定效应模型和面板分位数回归模型进行参数估计,结果如表6所示。在两种模型中均显著的变量有:总人口、能源结构、能源强度、人均GDP和对外开放度。此外,产业结构仅在分位数回归中显著,城镇化率和政策变量仅在0.3分位点对应的模型中是显著的,FDI仅在0.7分位点对应的模型中是显著的。接下来将依次对变量的回归结果进行详细的解释说明。
Table 6. Comparison of results of regression models
表6. 回归模型结果对比
总人口
注:括号内为t统计量,*p<0.05,**p<0.01,***p<0.001。
由上表可知,总人口数在两种模型中均是显著的,并且从两种模型都能看出,总人口数与碳排放量呈正向相关关系,即总人口数增加会促使碳排放量的增加。接着通过处于不同分位点的回归系数进行分析,处于不同碳排放量区间的情况下,总人口数的影响效果逐渐减弱,说明总人口对其虽有正向影响,但其在碳排放量较低的情况下,影响更为明显。究其原因,可能是因为在高碳排放量的情况,有其他更为显著的因素影响碳排放量,在此基础下,总人口数的影响相对来说较弱。
产业结构在两种回归中结果不一样。首先是在固定效应回归中,它对碳排放量有正向影响;但在分位数回归中,它对碳排放有负向显著影响,且随着碳排放量的增加,该影响逐渐减弱。结合两者可以看出,产业结构对碳排放量是有影响的,但在碳排放量达到一定水平后,该因素的影响效果变得不够明显。主要是因为产业结构中运用到了第二产业的占比,而第二产业主要包括工业和建筑业,包括能源工业、煤炭工业和石油工业等。碳排放量主要源自各种能源、煤炭的消耗,而当前第二产业增加值占比较多,导致碳排放量相对来说也较多。但在我国对产业结构进行调整的情况下,第二产业增加对碳排放的影响逐渐减弱。
能源结构在两种回归中都是显著的,且系数均为正,在不同分位点下的回归系数可以看出,能源结构在一定的水平下对碳排放影响效果程度较大,但随着碳排放量的增加,效果会逐渐减弱,而煤炭消费量越多,必然会导致碳排放量的增加。随着碳排放量的增加,我国陆续提出各种减排政策及相关措施,也对能源结构为碳排放量带来的影响起到了一定的抑制作用。能源强度在两个模型中都十分显著,且从分位数回归结果可以看出,随着碳排放量的增加,能源强度的影响程度逐渐增大。这是因为能源消费总量中包括各类能源(煤炭、原油、天然气等)的消费,而这些能源的消费必然会导致二氧化碳排放量的增加。
城镇化率仅在0.3分位点对应的回归模型中是显著的,而且其对碳排放量的影响是负向的,说明在碳排放量较低的情况下,城镇人口比重增加,碳排放量会减少。究其原因,这可能是因为碳排放量较低,但同时也能说明我国经济正处在发展初期,可提供的能源消费较少,且人均可支配收入也不够充足,居民相对来说更愿意在非能源方面进行消费,因此此时城镇人口增加并不会明显促使碳排放量的增加,反而会产生负向影响。
人均GDP在上述两个不同的模型中对自变量都是呈现出显著正相关的影响。人均GDP增加,说明经济水平提高,能源供给较为充足,此时居民消费能力也增强,对于各类能源的需求也不断发展,进而引起碳排放量的增加。
对外开放度在两个模型中均属于显著变量。但处于不同分位点,也就是不同的碳排放量下,其影响程度也有所不同。由回归结果可以发现,对外开放度对碳排放量的影响呈现出先升后降的情况。这主要是因为对外开放度包含了进出口贸易总额,对外开放度增加,代表着经济水平提高,因此会导致碳排放量的增加。但在碳排放量达到一定程度时,对外开放度的影响效果有所减弱。
FDI仅在0.7分位点对应是显著的。说明在碳排放量较低的情况下,实际利用外资总额对碳排放的影响不大。而在高碳排放量的情况下,实际利用外资总额增加,侧面说明我国经济规模增大,经济发展较好,因此会导致碳排放量的增加。
政策代表着《环保税法》。其仅在0.3分位点对应的回归模型中是显著的,这可能是由于在低碳排放量情况下,人均可支配收入较少,环保税法对消费者在能源等方面的消费能力进行了适当的限制,有助于减少碳排放量。而在中、高碳排放量情况下,该因素是不显著的,这主要是由于此时居民人均可支配收入较为充足,相对来说,环保税法对居民消费能力的影响也有所减弱,因此对碳排放量的影响也不明显。
4.5. 基于随机森林的变量重要性排序
通过面板分位数回归了解到各因素对碳排放量的影响程度,下文将根据随机森林算法对各因素重要性进行排序。本文以碳排放量作为因变量,其余变量作为自变量构建随机森林回归模型,利用R软件绘制出因素重要性图(见图4),其中采用的数据是碳排放量及各因素的原始数据。图4描述了基于两种不同的评判方法的变量重要性图,其中各变量对应的数值越大表示其越重要。总体上看,两种方法的结果大致类似,但再基于上文中分位数回归的结果,即总人口、能源结构、人均GDP等因素是显著的,因此接下来将采用IncMSE法的结果进行分析。由图可看出,能源结构、总人口数、对外开放度的重要性位列前三,人均GDP和FDI等次之,政策变量重要性最低。其中在人口因素方面,总人口数的重要性高于城镇化率(人口结构),这意味着人口数量对碳排放量的影响较人口结构来说更为明显;在经济水平方面,对外开放度的重要性略高于FDI和人均GDP;在技术水平方面,能源强度的重要性也并不低;在结构因素方面,能源结构的重要性远高于产业结构;政策因素的重要性最低,说明其对碳排放的影响不够明显。
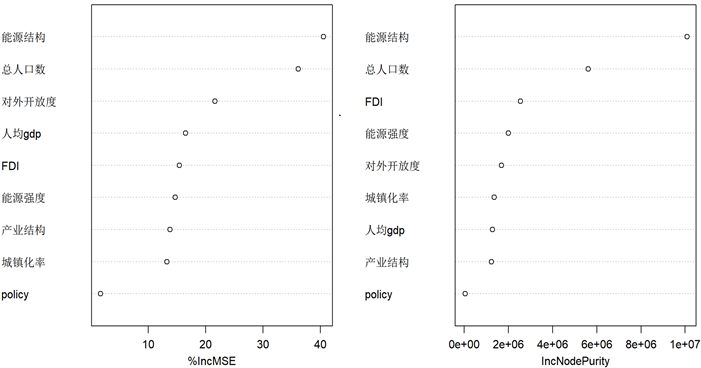
Figure 4. Importance ranking diagram of each variable
图4. 各变量重要性排序图
5. 结论与建议
5.1. 结论
本文利用2010~2019年中国30个省(除西藏自治区外)的面板数据,先对数据进行基本描述性分析,接着在采用拓展的STIRPAT模型进行变量选取的基础上,构建面板分位数回归模型探究碳排放量的影响因素,并与固定效应模型进行对比,再进一步基于随机森林算法对各变量进行重要性排序,结果显示,我国的二氧化碳排放量呈现出西部及西南部较低,而东部及东南部地区较高的情况;总人口、能源结构、能源强度、人均GDP、对外开放度与碳排放量是呈正相关关系,但在不同分位数的情况下,它们对碳排放量的影响程度变化不一样。
产业结构只在面板分位数回归中是显著的,但随着分位数的增加,该因素的影响越来越弱;而城镇化率和政策变量仅在分位数为0.3的模型中是显著的,但在低碳排放量的情况下,城镇化率与其具有负相关性,此时城镇人口比重增加,碳排放量会减少;FDI仅在分位数为0.7的模型中是显著的,FDI在高碳排放量的情况下,会促使碳排放量的增加;但在碳排放量较低的情况下,环保税法的颁布又有助于减少碳排放量。此外,本文基于随机森林对各变量进行重要性排序,发现能源结构、总人口数的重要性最高,其次是对外开放度、FDI、人均GDP、能源强度、产业结构、城镇化率,最后才是政策变量。
5.2. 建议
根据上述研究结论,发现能源结构、总人口数、对外开放度等因素对碳排放量具有显著影响。因此,本文将着重于能源结构、产业结构、经济水平、政策等方面,提出以下几点建议。
首先,要有效调整能源结构与产业结构。在能源结构方面,需要多引进可再生能源,加强能源转化效率,同时要减少煤炭及化石燃料消费,提倡以电能、风能等绿色能源消费代替煤炭消费。在产业结构方面,要注重发展低碳产业,推进产业转型,提高生产效率的同时,注重绿色发展,生产方面注重使用无污染能源。
其次,要科学地制定相关碳排放政策,朝着“碳达峰,碳中和”目标进军,充分考虑我国国情,针对我国各省份之间的差异,要因地制宜地制定不同的策略来应对,制定能够满足地区之间的差异并且切实可行的“双碳”减排政策。对于不同的省份,碳排放量不同,影响碳排放量的因素也并不完全一样。因此,不能一刀切,而是要有针对性地解决不同省份碳排放量高的问题。政府也应当鼓励居民做到低碳生活,要使低碳生活落实到每一位公民身上,从自身做起,从小事做起,为建立低碳生活做贡献。
最后,要推进低碳经济发展。在经济持续发展的情况下,碳排放量也在持续增加,两者之间存在相互影响。为保证经济增长不会受限的同时,实现绿色发展,需要从技术创新方面考虑。具体包括:推进科技发展,提高技术水平以实现资源可持续性利用,加强生产转化效率,建立循环经济发展体系。