1. 引言
面孔吸引力是人在面孔知觉上的一种认知偏好,在我们的社会交往和人际互动中有着重要作用。社会学家,心理学家通过实验研究证明了富有吸引力的面孔往往会在社会认可、职业发展、人际关系上带来更多的好处与优势。因此,对这种机制的探索和研究具有实质上的意义。大量认知心理学的实验表明 [1],这种不同个体主观的感受具有一定的共性与规律。并且是可以通过机器去学习的 [2]。
面孔认知偏好分析与预测在人脸美化算法、医学美容指导、基于内容的图像检索、推荐系统等方向上具有重要的应用价值。但这个问题仍然具有挑战性,一方面它涉及到认知科学、心理学、等多学科的交叉领域,另一方面需要大量数据作为驱动,而目前这方面的数据集较少。
早期的研究方法主要是通过手工设计不同特征表述符 [3] [4],这些特征可以是基于几何、颜色、纹理,也可以是基于局部或整体尺度。随着深度学习的发展,许多学者将CNN结构的网络模型 [5] [6] [7] 应用到该领域上,采用深度网络的相比传统的机器学习可以提取到更深层、更抽象的特征。能更好地学习到贴近于人类的审美认知机制。近年来,视觉Transformer [8] 的出现打破了计算机视觉与自然语言处理的壁垒,相较于CNN模型,Transformer框架更具有更大的数据容量与相对更好的性能,能捕获图像的长距离依赖关系,具有全局性。但存在一些缺点,首先Transfomer处理视觉任务时缺乏CNN网络所具有的归纳偏置,需要在大规模的数据集上作训练,并且参数量较大,计算复杂度高(与token的平方相关)。由此,一些混合模型兼顾了卷积的归纳偏置和多头自注意力机制捕获长距离相互作用的能力,如BoTNet [9]、CoAtNet [10]、TranCNN [11],表明结合卷积层和注意层可以获得更好的泛化能力和容量,在较小的数据集上也能取得不错效果。
2. 任务流程及定义
2.1. 任务流程
面孔吸引力分析预测本质是一个多范式计算问题,可视作回归、分类、排序问题处理。其关键在于如何去学习人脸特征到评价统计量的映射关系。如图1所示,首先将原始的图像数据集引入评价系统,量化每位评价者的主观感受,对这种主观感受的量化指标做数据处理后生成具有代表性的统计量。统计量的不同代表处理这个问题的不同范式,如取样本均值可作为回归问题,取众数作为分类问题,取在不同评级上的分布率可作为一个标签分布问题 [12]。将这个统计量作为该图像对应的标签。另一方面是将数据集做预处理,比如剪切、旋转、对齐、归一化等方式转为便于机器处理的数据。一部分作为训练集和验证集输入到模型中进行训练和调优。传统的机器学习方法中,分为特征工程和输出算法模块(如高斯回归、支持向量机分类等),而深度学习模型则是一个由输入到输出端到端的整体架构。另一部分数据作为测试集测试检验模型的学习效果,对新的输入图像进行评估预测。另外,可以迁移到新的数据集上对其进行训练微调。
2.2. 任务定义
对给定的人脸图像集:
,n为数据集容量。其中对给定的人脸Fi,由k个评价者给出的指标集:
,在Pi上抽取出统计量Si。训练一个预测模型,对特定的人脸Fi,抽取特征
,并学习抽取的人脸特征到统计特征Si间的映射:
。
3. 网络结构
3.1. 结构总览
如图2所示,本文提出的模型可以大致分为三个阶段:特征图提取、视觉词向量嵌入、自注意力计算、表示特征回归
1) Backbone部分,由预训练过的Resnet-18的前四个阶段组成,Conv_1到Conv_4作为前置网络提取特征图。
2) 将提取的特征图在空间维度上展平并加上可学习的位置编码,再通过线性层映射到特定维度的嵌入空间,作为具有表征性的视觉词向量。
3) 利用多层的Transformer编码器模块,计算嵌入的词向量中各元素的自注意力。把握中不同视觉特征成分在全局上的相对关系。面部特征词嵌入中各元素间的复杂联系。
4) 最后的部分做一个全局平均池化后使用一个简单的全连接层计算回归输出。
3.2. Backbone模块
本文采用在MS-Celeb-1M人脸检测数据集上预训练过的Resnet-18 [13] 的部分网络层作为Backbone来提取图片特征,对给定的输入为224 × 224 × 3的RGB人脸图像,经过如表1所示四个的阶段后,抽取出人脸特征图
,其输出形状为[14, 14, 256]。

Table 1. Backbone structure of our model
表1. 特征提取网络结构
3.3. Transformer模块
Transformer [14] 是2017年提出的一个自然语言处理框架,包括词嵌入、位置编码、编码器与解码器四个模块。一般地视觉任务中会将解码器模块去掉。
在本文中由上一级的残差网络抽取的二维特征图组
,需要将其转化为一维的视觉词向量序列,这里将其展平为
后经由一个线性层E投射到
,在这里
,
。并加上一个一维的可学习位置嵌入向量Epos,由此得到视觉词嵌入向量序列:
(3.1)
位置向量Epos学习嵌入向量在每一个位置上的信息,最后生成的Z0则代表了对位置敏感的特征序列,为了把握面部特征词嵌入中各元素间的复杂联系,将Z0作为多层标准的Transformer编码器结构的输入。Transformer编码器通过多头注意力模块(MSHA)来计算嵌入向量的权重,包含可学习的三个矩阵:查询矩阵Q、键矩阵K和值矩阵V,其中每一个注意力头的注意力计算表达式如式 :
(3.2)
相较于单个注意力头的情况,多头注意力计算的实现采用多个查询矩阵、键矩阵、值矩阵将Z0投影到Nh个不同的表示子空间:
(3.3)
其中的
,
,
,Nh表示不同注意力头的个数,每个头的d等
于信道数除以头数
。最后通过拼接操作(Concat)将不同注意力头的输出整合成一个矩阵,整个注意力计算过程如图3所示。每个Transformer编码器由多个多头自注意力模块堆叠而成,这里
,超参数Nl表示堆叠的个数。该结构输出如式 、 :

Figure 3. Diagram of the practical teaching system of automation major
图3. 自注意力计算模块
(3.4)
(3.5)
其中,
,
表示在第j层中的中间输出与最终输出。LN代表层正则化(Layer Normalization)。每个模块最后MLP层由两个前馈层和一个GELU非线性激活函数。输入层与输出层大小相同均为384,隐藏层是输入层的四倍,这里设置为1536。
对最后的输出ZNl进行一个全局池化操作后,再输入到一个隐藏层为5输出层为1的全连接层,其设置目的是为了更好地归纳5个类级的权重,最终得到输出结果。
4. 实验与分析
4.1. 数据集及预处理
本文的实验数据集来源于华南理工大学2018年制作的SCUT-FBP5500数据集 [15],这是一个多属性多范式的数据集,包含有5500张中性表情的正脸图像,共分为四个子集:亚洲男性、亚洲女性图像各2000张,高加索男性、高加索女性图像各750张。每张图片都对应有60个志愿者的评分,评分范围为{1, 2, 3, 4, 5}。其中5表示吸引力最高的指标,其余依次递减。图4为数据集上的标签分布情况。
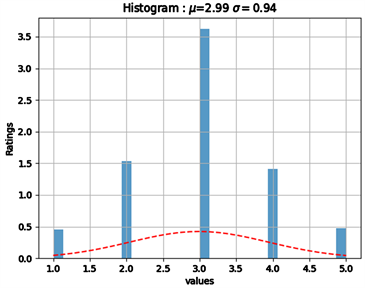
Figure 4. Label distribution on SCUT-FBP5500
图4. 数据集上的标签分布
本文以每张图像的所有评分的均值作为其对应标签。其分布情况如图4。基于SCUT-FBP5500数据库中包含有每张图像上标注的86个面部特征点数据,这里采用第44号,第52号(左右眼中点)和第75号点(上唇中点)的坐标作对齐处理,归一化至224 × 224大小。将训练集、验证集、测试集按60%、20%、20%的比例做随机划分。由于数据集样本量较小,为了避免的过拟合,采用左右翻转的方式将训练集、测试集、验证集扩充一倍。
4.2. 评价指标
本文将面孔吸引力评估预测视作回归问题,采用三个回归模型评价指标:皮尔逊相关系数(PC),平均绝对值误差(MAE),均方根误差(RSME)。皮尔逊相关系数是用以刻画真实值与预测值的相关程度的指标,其取值范围为[−1, 1],越接近于1表示相关性越强。而平均绝对值误差,均方根误差表预测值与真实值的接近程度,用以刻画模型的拟合质量,它们的值越接近于零效果越好。其计算公式如下:
(4.1)
(4.2)
(4.3)
4.3. 实验设置
本次实验所用环境为谷歌实验室Colar,显卡为Nvidia TeslaK80,显存11 G,深度学习框架为Pytorch1.5 + cuda10.1,优化器选用Adam,学习率初始时设置为5 × 10−4,batch_size设置为50,通过在验证集上的实验筛选出合适的超参数.前10轮训练中冻结特征提取网络的参数,后面轮次的训练对整个网络的参数进行微调。
4.4. 实验结果与分析
经过实验验证,最终选定超参数Nl = 3,Nh = 8,Nl会显著地提升参数量,过高会导致过拟合,Nh较小则表现较差,因为没有足够的子空间来学习潜在的特征信息。为了验证本文模型的有效性,与该数据集上的其它模型作对比,本文深度学习模型在皮尔逊相关系数、平均绝对值误差、均方根误差三个指标上均取得到了提升。如表2所示。其中Psychological inspired CNN [6] 是一种采用级联微调的方法优化,将输入的图像提取色彩、纹理、几何成分融合输出的模型,ResNeXt-50 based R3CNN [7] 是一种通过排序信息引导的CNN网络。
Table 2. Experiment results comparison
表2. 实验结果对比
5. 总结
本文将多头自注意力模块应用在面部属性感知分析的面孔吸引力预测方向,提出了一种结合了残差网络结构与Transformer编码器结构的混合模型。该模型先使用残差网络作为Backbone提取特征图,再将特征图转化为视觉词嵌入向量,通过多头自注意力机制模块计算各元素间位置信息的长依赖关系,从全局的建模方式来把握各层特征的相对联系。最后通过一个池化层与全连接层来获得回归输出。为了验证了该混合模型的可行性与有效性,在SCUT-FBP5500数据集上进行实验,取得了较好的效果。