1. 引言
数据挖掘是目前人工智能和数据库领域研究的热点问题,指从大量的数据中提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。聚类分析现在已经成为数据挖掘领域中一个非常重要的研究方向。MacQueen提出 [1] 的K-means算法是聚类分析中最常用的方法之一。它采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 [2] 。K-means算法假设样本的每个特征对最终聚类的贡献程度一样,但在实际情况中某些特征在聚类的过程中起到很大的作用,而某些特征的作用却很小,甚至对聚类过程没有影响。
针对传统K-means算法的这一问题,学者们进行了大量研究,研究表明:通过对特征赋予不同的特征权值,能够有效解决上述问题并提高聚类性能。目前,计算特征权重的算法有很多种:刘铭 [3] 等人提出一种结合限制数据的特征权值量化函数,该函数通过用户指定的限制数据进行特征权值量化并对不同的限制数据赋予不同的置信度,解决了限制数据分布不均匀和限制数据中可能包含不一致性的问题;Li Jie [4] 等人提出将针对分类问题的ReliefF算法应用于聚类问题,通过ReliefF算法计算特征权重值,并对各维特征进行加权,提高聚类的性能;Meng Qian [5] 等人提出通过梯度下降技术最小化特征评估函数FLearning (w)为每个特征分配权重并进行加权,该算法采用遗传算法和模拟退火算法的优点,减弱冗余特征的影响,解决了容易陷入局部最优解的问题。Songtao Shang [6] 等人提出一种改进的基尼指数算法计算特征权重,该算法克服了原始Gini的缺点,将条件概率与后验概率结合,抑制训练集不平衡时的影响。杨玉梅 [7] 利用信息论中的信息熵计算特征权重并对各位特征加权,有效的解决了特征对聚类的影响。
综上所述,为了提高传统K-means算法的聚类精度,国内外学者对K-means算法进行了大量改进探索研究,并取得了一些阶段性的成果。本文拟研究传统K-means算法在聚类过程中聚类对象的每个特征对聚类结果的贡献度,使贡献程度大的特征优先利用,理论上讲可以有效提升K-means算法聚类的准确率和精度。因此,本文提出将熵值法和ReliefF特征选择算法有机融合,通过采用信息熵和ReliefF特征选择算法对特征进行加权选择,修正聚类对象间的距离函数,使算法达到更准确更高效的聚类效果。实验结果表明,改进后的算法聚类结果稳定,且具有较高的准确率,达到预期目的。
2. K-means算法
K-means算法的核心思想是通过迭代把数据对象划分到不同的簇中,以求目标函数最小化,从而使生成的簇尽可能的紧凑和独立,算法具体流程如下。
输入:簇的数目k,包含n个对象的数据集D。
输出:k个簇。
步骤如下:
1) 从D中任意选择k个对象作为初始聚类中心;
2) 计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
3) 重新计算每个聚类的均值;
4) 当满足一定条件,如没有对象再被重新分配给其他的类簇、聚类中心不再发生变化、误差平方和(SSE)最小,则算法终止;如果条件不满足则回到步骤(2)。
其中,每个对象与中心对象的距离为欧氏距离,距离公式如下:
(1)
上式中:x,y分别表示样本和聚类中心;j表示第j维特征。
3. 基于特征加权的改进算法
3.1. 信息熵
1948年,信息论之父克劳德•艾尔伍德•香农在他发表的论文“通信的数学理论(A Mathematical Theory of Communication)”中,提出了“信息熵”的概念。香农指出,任何信息都存在冗余,冗余大小与信息中每个符号(数字、字母或单词)的出现概率或者说不确定性有关。他用“信息熵”描述信息的不确定性。信息熵的数学表达式如下:
(2)
其中,
表示事件发生的概率。
在权重方面,对于任意两个特征
、
,若
,则表示特征
比特征
好,在聚类过程中,特征
比特征
起到的作用大。
3.2. RliefF算法
1994年,Knonenko提出了ReliefF算法,它是Relief算法的扩展,主要处理多分类问题 [8] 。ReliefF算法的基本思想是从训练样本集中随机取出一个样本xi;然后从与xi同类的样本中取出k个近邻样本Hi;再从其他与xi不同的类中分别取出k个样本Mi;根据权重公式更新每个特征的权重;随机抽取m次,得到最终的特征权重。
权重表达式如下:
(3)
上式中:
表示样本xi所属的类别;c表示除样本xi所属的类别外的类别;p(c)表示类别c的先验概率。
表示样本xi关于第j个特征的值;m是随机抽取样本的次数;
表示距离函数,用于计算两个样本关于第j个特征的距离,计算公式如下:
(4)
其中,
表示第j个特征的所有取值中的最大值和最小值。
ReliefF算法用于处理多分类问题,每个样本都要有明确的类标记。但聚类分析中的样本没有类标记。所以,需要先对样本集进行一次初聚类,获得样本的类标记,再用ReliefF算法进行特征权重的计算。
3.3. 基于特征加权的改进算法ER_Kmeans算法(EntropyReliefF_Kmeans)
传统的K-means算法在聚类过程中假设每个特征对于聚类的影响是相同的,忽略了特征对于聚类过程的影响,导致最终的聚类结果准确率不高。基于特征加权的改进算法则有效的解决了这一问题。
ER_Kmeans算法的基本思想是将聚类对象的特征权重与信息熵作为K-means算法的特征权重进行聚类。设信息熵权重为w1,特征权重为w2,则最终的特征权重为
(5)
ER_Kmeans算法的步骤如下(图1):
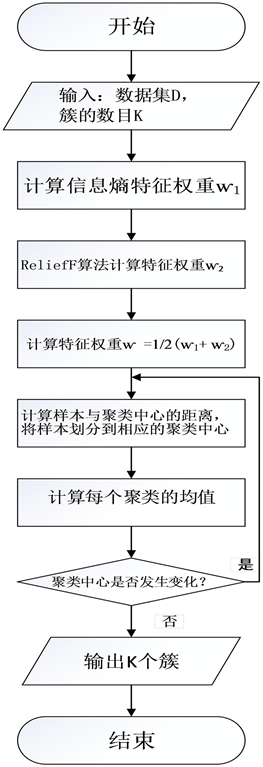
Figure 1. ER_Kmeans algorithm flowchart
图1. ER_Kmeans算法流程图
输入:数据集D,簇的数目K
输出:K个簇
1) 随机选择K个初始聚类中心;
2) 计算信息熵特征权重ⱳ1;
3) ReliefF算法计算特征权重ⱳ2;
4) 计算特征权重ⱳ;
5) 计算每个样本与这些聚类中心的距离
;并根据最小距离将样本划分到相应的聚类中心;
6) 重新计算每个聚类的均值;
7) 若聚类中心不再发生变化,则算法终止;如果聚类中心发生变化则回到步骤(5)。
4. 仿真实验
4.1. 实验环境与数据集
实验的硬件环境为Intel(R)Core(TM)i5-6500 3.20 GHz,8 G内存,软件环境为Matlab2016b,Windows7操作系统。实验选取的数据集为UCI数据库 [9] 中的Iris、Balance-scale、Stalog数据集,数据集的主要信息如表1所示。
4.2. 实验结果与分析
为了验证在聚类过程中聚类对象的每个特征对聚类结果的贡献度不同,在Iris、Balance-scale、Stalog 3个数据集各计算20次得到各特征对应的权重值如图2、图3、图4所示。图中一条线代表一次计算。
由图2、图3、图4可以看出,每个特征对于聚类结果具有不同的影响。以图4 Stalog数据集的特征权重值为例,从图中可以看出,特征7和特征12的权重值较高,说明其对聚类结果的影响较大;特征6和特征15的权重值较低,几乎趋近于0,说明对聚类结果的影响较小甚至可能没有影响。传统的K-means算法忽略了这一问题,导致最终的聚类结果在精度方面较低。
为了验证算法的有效性及稳定性,在相同的实验环境下,ER_Kmeans算法与传统K-means算法、文献 [4] 的基于ReliefF算法的加权K-means算法ReliefF-Kmeans、文献 [7] 的基于信息熵的加权K-means算法entropy-Kmeans在相同的数据集下,都进行了20次的单独实验,并取平均值,在准确率、误差平方和(SSE)、迭代次数和运行时间4个方面进行比较。结果如表2~表6所示。
从表2可以看出,在准确率方面,ER_Kmeans算法明显高于其他3种算法,由于传统K-means算法忽略了特征对于聚类结果的影响,聚类结果是不稳定的,所以准确率低于其他3种算法;从表3可以看出,ER_Kmeans算法的误差平方和低于其他3种算法,误差平方和越小,说明聚类中的对象越相似,所以ER_Kmeans算法每类的类内对象相似度高,聚类质量优于其他3种算法,达到了聚类分析的最终目的,
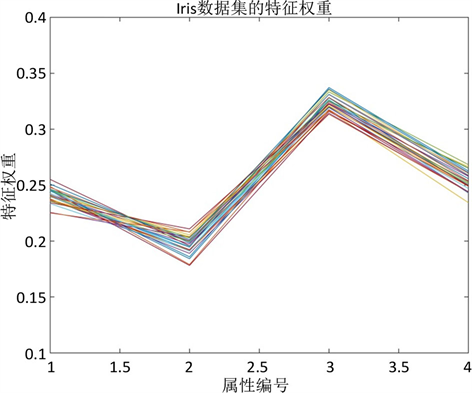
Figure 2. Feature weights of the Iris dataset
图2. Iris数据集的特征权重
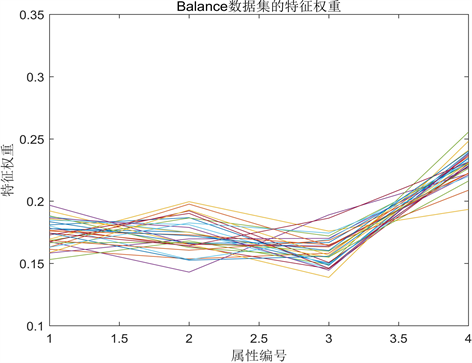
Figure 3. Feature weights for Balance-scale datasets
图3. Balance数据集的特征权重
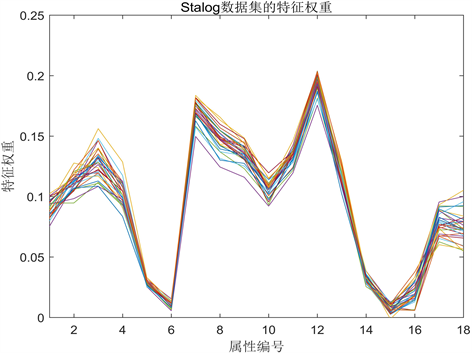
Figure 4. Feature weights of the Stalog data set
图4. Stalog数据集的特征权重

Table 2. Comparison of accuracy of each algorithm in UCI dataset (%)
表2. 各算法在UCI数据集的准确率比较(%)
Table 3. Comparison of error square sum (SSE) of each algorithm in UCI dataset (/ms2)
表3. 各算法在UCI数据集的误差平方和(SSE)比较(/ms2)
Table 4. Comparison of the number of iterations of each algorithm in the UCI data set (/times)
表4. 各算法在UCI数据集的迭代次数比较(次)
Table 5. Runtime comparison of each algorithm in UCI dataset (/ms)
表5. 各算法在UCI数据集的运行时间比较(/ms)
Table 6. The average run time of each algorithm in the UCI data set is compared with each iteration (/ms)
表6. 各算法在UCI数据集的平均每次迭代运行时间比较(/ms)
即类内相似度高,类间相似度低;从表4和表5可以看出,ER_Kmeans算法在迭代次数和运行时间上低于传统K-means算法和entropy-Kmeans算法,在Iris数据集和Stalog数据集上低于ReliefF-Kmeans算法,但在Balance数据集上高于ReliefF-Kmeans算法, 原因是算法的初始聚类中心是随机选择的,从而导致了算法迭代次数的不稳定、运行时间的长短不同。但在平均运行时间上二者差别不大,从表6可以看出,ER_Kmeans算法在平均每次迭代运行时间上低于传统K-means算法和entropy-Kmeans算法,在Balance数据集上高于ReliefF-Kmeans算法,但ER_Kmeans算法平均每次迭代的时间与ReliefF-Kmeans算法相差不大,说明迭代次数和运行时间较高是受到初始聚类中心的影响。
5. 结束语
本文提出一种利用信息熵和ReliefF算法对特征加权的K-means算法ER_Kmeans算法,有效的解决了不同的特征对于聚类具有不同的影响这一问题。实验结果表明:改进后的K-means算法在准确率和聚类误差上都优于传统K-means算法和其他两种特征加权方法,取得了较好的聚类结果。
基金项目
本研究获得国家自然科学基金(61363016, 61063004);内蒙古自然科学基金(NO.2015MS0605, NO.2015MS0626, NO.2015MS0627, NO.2017MS0605);内蒙古教育厅高校研究项目(NJZC059);内蒙古自治区高等学校科学研究重点项目(NJZZ14100);教育部留学人员基金([2014]1685);内蒙古自治区科技计划项目:穿透降水量GSM网络在线监测与数据传输系统的资助。