1. 引言
近些年,缅语分词逐渐受到研究人员的关注,但是相比中文分词的成果,缅语分词相关的研究还需要继续努力。目前,主要的分词方法有三类:1) 基于词典匹配的方法,如果发现文本中出现字符串的某一子串与词典中的词条相同,就算是匹配成功。它的优点是速度快,实现简单,缺点是无法正确识别未登录词。2) 基于统计的分词方法,上下文中,相邻的字出现的次数越多,就越可能构成一个词。因此字与字相邻出现的概率或频率能很好的反映词的可信度。它的优点是分词准确性较高,但分词速度较慢。3) 基于规则的分词,通过模拟人对句子的理解,达到识别词的效果。基本思想是语义分析,句法分析,利用句法信息和语义信息文本进行分析,它的优点是分词准确性高,但算法实现复杂,实现难度较大。对比以上三种分词方法,由于缅语的复杂性和相对匮乏性,暂时不考虑基于规则的缅语分词方法。
关于缅语分词方面的研究,Thet T T和Na J C等人曾提出了一种基于规则的音节划分与基于字典的音节合并的缅语分词方式 [1] ,Mo H M和 Nwet K T等人提出了一种基于CRF的缅语人名识别方法 [2] ,Phyu M L和Hashimoto K.等人提出了一种基于CRF和特征聚类的缅语分词方式 [3] 。本文以开发缅语语音合成系统为目的,分析和比较了基于CRF和FMM的分词效果。为了能在缅甸语分词过程中使用CRF模型,我们构建了一个人工分词语料库作为训练集,通过0.58版本的CRF++工具包 [4] 在Linux平台上实现缅语了分词系统。
本文的其余部分安排如下:第一部分,介绍了缅甸语的特征。第二部分,缅语分词方法的介绍。第三部分,实验结果以及分析。第四部分,总结与展望。
2. 缅甸语简介
缅甸语属于汉藏语系藏缅语族,它是缅甸社会主义联邦共和国的通用语,大约有5400万人使用这一种重要的语言。缅语不同于英文以及欧洲其他的一些语言,它与中文相似,都是大字符集上的连续子串,且没有明显的词边界。现代缅甸文字是一种拼音文字,书写时从左到右。从字型来看,好像是用大小不同的圆圈拼接、套叠而成。它在东方和世界文字之林中,可以说是别具一格,不同于方块形的汉子表意,缅文表音。缅甸语有33个基本辅音字母,7个独立的元音字符,7个非独立元音字符,4个基本介音,10个数字符号,2个标点符号,详见文献 [5] 。下面是一个缅语句子划分为音节和音节拼接为词的实例,音节之间和词之间均用“+”连接。
句子:
音节:
词:
中译:我是一名学生。
3. 缅语分词方式
3.1. 基于CRF的分词
条件随机场模型(Conditional Random Fields,简称CRF,或CRFs)是基于隐马尔科夫模型和最大熵模型提出的一种判别式概率无向图学习模型 [6] ,也是一种基于统计序列标注和分割的分词方法 [7] ,它将缅语分词问题转化为一个序列标注问题,即将词语开始至结束字符分别标记,之后根据标记完成对句子分词。相比隐马尔可夫模型和最大熵模型,CRF没有隐马尔可夫模型那样严格的独立性假设(观测值之间相互独立),因而可以容纳上下文信息,同时CRF还克服了最大熵模型标记偏置的缺点。
输入数据的序列标注即为每一个输入序列分配一个标注符号,对于分词问题,
是一个长度为T的输入数据序列,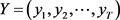 作为对应的标注序列。在给定一个输入序列的情况下,设
为线性链条件随机场,则在随机变量X取值为x的条件下,随机变量Y的取值为y的条件概率具有如下形式,如公式(1):
作为对应的标注序列。在给定一个输入序列的情况下,设
为线性链条件随机场,则在随机变量X取值为x的条件下,随机变量Y的取值为y的条件概率具有如下形式,如公式(1):
(1)
其中,Zx是规范化因子,
是一个任意的特征函数,λk是与特征函数相关的权重。条件随机场的预测问题是给定条件概率
和输入序列x,求条件概率最大的标注序列y*,即对输入序列进行标注。条件随机场的预测算法是著名的维特比算法,如公式(2):
(2)
3.1.1. 标注方式
条件随机场的缅文分词思想类似于中文分词思想,就是通过分析大量的缅语文本语料库去计算一个音节在字符串中的位置的可能性。利用条件随机场来进行缅文分词就是一个字符标注的过程,缅文文本的标注以一个音节为基本单位,缅甸语的词是由单个音节或多个音节构成,统计5000个缅语句子,共计124,809个词,去除重复的词语后得到23,098个词,分别统计去重复前和去重复后缅语的词长分布,如表1所示。

Table 1. Situation of Burmese syllable in words
表1. 缅语词长统计表
由表1可知,去重前缅甸语中的词语的大多数为单音节词、双音节词和三音节词,四音节词及以上相对较少,统计得到缅语的词长均值为1.86个音节,去重后双音节词和三音节词所占比例较大。本文使用“S”“B”“M”“E”来分别表示单音节词、该音节出现在词的头部、该音节出现在在一个词的中间位置和该音节出现在一个词的词尾位置。缅甸语文本“ ”标注过程如图1所示,图1中过程①将句子分为五个词,过程②表示将每一个词划分为对应的音节并进行标注。
”标注过程如图1所示,图1中过程①将句子分为五个词,过程②表示将每一个词划分为对应的音节并进行标注。
3.1.2. 特征模板
CRF中一共存在两种模板:U-gram和B-gram,U-gram为一元模板,表示只与当前位置对应的标签相关的特征,B-gram二元模板,表示前一个位置和当前位置对应的标签相关的特征,当类别数很大的时候,这种类型会产生许多可区分的特征,这将会导致训练和测试的效率都很低下,本文选择的是U-gram模板。对字符串标注前还要进行特征的选择,虽然条件随机场模型中在理论上可以允许各种长度各种样式的特征,但是如果我们选择的特征过多过长会使得整个系统在运行算法时变得速度很慢,所以通常我们选取特征只在有限的上下文本范围内进行选择。特征模板格式:%x [row, col]。x可取U或B,对应两种类型。方括号里的编号用于标定特征来源,row表示相对当前位置的行,0即是当前行;col对应训练文件中的列,这里只使用第1列(编号0)。本文选择距离为2的特征模板,其具体含义如表2所示。
3.2. 基于FMM的分词
本文对基于词典的分词算法采用正向最大匹配(Forward Maximum Matching,简称FMM),其主要原理都是切分出单音节串,然后和词库进行比对,如果是一个词就记录下来,否则通过增加或者减少一个音节,继续比较,一直还剩下一个音节则终止,如果该单音节串无法切分,则作为未登录处理。同时,缅语文本中存在四音格结构 [8] [9] ,缅甸语四音格词的类型为ABCD、ABAC、ABCB、AABB、ABCC、ABBC、ABCA、ABAA、ABAB、AAAA、AABC,共11种。其中,数量最多的是ABCD类型,最少的是ABAA类型。本文用到AAAA、AABB、ABAA、ABAB四种四音格词,即若音节列表中连续出现四个音节满足以上四种四音格词结构,则将这四个音节重划为一个词。
词典来自Technomaion Studios公司编著的缅甸语-英语词典,共有词条26,601个,为了充分和合理的使用词典,我们提出了基于Hash的词典设计方式从而能够更快更有效率的分词。
4. 实验方案与结果分析
4.1. 实验数据库的构建以及分析
本文实验数据库的构建过程为:
1) 利用爬虫软件火车采集器在缅甸语网站上抓取大约600 MB的原始语料库,内容涵盖了娱乐、体育、生活、商业、宗教、新闻等各方面。
2) 原始语料经过去重复和去非法字符后得到文本语料库,从文本语料库中随机挑选出5000句作为缅语分词实验文本集,经过音节划分之后,采用基于词典的分词方法对数据进行初步划分;
3) 将基于词典的分词结果交给两位缅甸语专家进行校对以及改正,缅语专家按语义对语料分词,将5000个缅语句子平均地分为25个文档,编号为#1,#2,#3,……,#25。A专家和B专家各自需要完成的文档如表3所示,#1至#5号文档由专家A完成后得到TextSet1文本集,包含5个文档,编号#A1~#A5,由专家B完成后得到TextSet2文本集,包含5个文档,编号#B1~#B5,#6至#15号文档由专家A完成后得到TextSet3文本集,#16~#25号文档由专家B完成后得到TextSet4文本集。
本文根据置信度来衡量实验结果的真实性,假设A专家、B专家对同一个文档完成分词以后得到的两个文档#Ai和#Bi (I = 1, 2, 3, 4, 5)中词的数量分别表示为N(Ai)、N(Bi),其中相同的词的数量表示为M(AiBi)。那么Bi相对于Ai的置信度表示为公式(3):
(3)
若将TextSet1文本集作为标准分词数据,那么TextSet2文本集相对于TextSet1文本集的置信度为C(Bi, Ai),阈值C1 = min{C(Bi, Ai)}。若将TextSet2文本集作为标准分词数据,那么TextSet1文本集相对于TextSet2文本集的置信度为C(Ai, Bi),阈值C2 = min{C(Ai, Bi)},其中i = 1, 2, 3, 4, 5,置信度的计算结果如表4所示。
根据表5,C(Bi, Ai)的最小值为0.875,则基于文本集TextSet1时,选定阈值为0.875。同理,基于文本集TextSet2时,选定阈值为0.906。
另外,分词精度和分词速度是评判一个分词系统性能好坏的两个重要方面,分词速度主要就是对待缅语分词,机器运算的处理速度,在机器硬件条件一样的前提下,分词速度越快越好。分词精度则主要是指的分词能够达到的准确程度,这是评价一个分词系统的最核心的标准。本文对于分词精度将选用召回率R、准确率P以及F-值作为评判标准 [10] ,其定义如公式(4),(5),(6)。其中,F-值能够综合衡量准确率和召回率,是P和R之间的权重比,令β = 1,则对待P和R的权重相同。A表示测试文本中切分正确的词总数,B表示测试文本切分错误的词总数,C表示在标准文本中属于正确答案但是在测试文本中没有被识别出来的词总数。
(4)
(5)
(6)
Table 3. Segmentation distribution by expert A and B
表3. 专家A和专家B的分词文档
Table 4. Results of the Confidence calculation
表4. 置信度计算结果
4.2. 分词实验结果对比及分析
将TextSet3文本集和TextSet4文本集作为CRF分词系统中的训练数据,#1~#5号文档作为测试数据进行CRF分词,同时也采用基于词典的分词方式,为了充分和合理的使用词典,我们提出了基于Hash的词典设计方式从而能够更快更有效率的分词,基于词典的算法采用正向最大匹配算法(FMM),分别将两种分词结果与TextSet1文本集和TextSet2文本集比较后,得到表5所示结果。
Table 5. Segmentation results of CRF and FMM methods
表5. CRF和FMM分词结果
根据表5可知,不论是基于文本集TextSet1还是基于文本集TextSet2,采用CRF分词得到的置信度大于阈值,采用FMM分词得到的置信度小于阈值,并且CRF分词的F-值相比FMM分词提高了10个百分点以上。而在机器的硬件条件相同的情况下,对同样大小的文档分词,CRF的分词速度相比FMM分词的速度慢,未来将考虑统计和词典结合的分词方法以提升速度和精度。
5. 结语
通过置信度、分词精度和分词速度比较了基于CRF和基于FMM的缅语分词方法,实验结果表明,前者对缅语分词具有较好的效果,可以将基于CRF的分词方式初步应用于缅语的分词。但是在分词速度上后者更占优势,因此,需要进一步考虑更完善的系统同时提升速度和精度。
基金项目
本文获得国家自然科学基金项目(61262068)资助。
参考文献
NOTES
*通讯作者。