1. 引言
随着硬件技术的不断更新,软件技术的迅猛发展,使得现有网络的承载能力有了飞跃性的提高,但是仍旧存在着网络承载能力的上限。在信息化社会,每天都会产生海量的信息,这些网络信息有些是人们正常合理需求所产生的,有些则是垃圾信息。这些在网络负载中占着不小的比重,给网络带来巨大压力的同时,也会窃取人们的个人隐私信息的网络流量一般称为异常流量。造成网络流量异常的原因有很多,一般包括:恶意攻击,如病毒、DoS攻击和DDoS攻击等;非法访问,如持续性端口扫描、远程未授权访问等。
传统的计算机网络由于观测点分布在各转发设备上,难以实现异常检测。然而,随着软件定义网络(Software-Defined Networking, SDN) [1] 的出现,异常检测在SDN控制器中能很好地发挥作用。作为一种新型的网络架构,SDN将传统的网络解耦成数据转发、网络控制、应用程序相互独立的三层结构,分别称为数据平面、控制平面和应用平面。数据平面主要负责数据转发功能,包括一切转发逻辑和转发表。控制平面掌控着网络全局信息,许多协议和算法都依赖于这个特征。由于SDN是未来网络发展的一个重要趋势,且其能提供比传统网络更完善的网络视图、更容易收集网络中的流信息、具有完善的管理平面,使得在SDN网络中研究网络流量异常检测技术成了一个重要的研究课题。
本文针对在SDN环境下的网络流量的异常检测提出了一种轻量级的算法。该算法利用SDN的特性,周期性地收集网络流量,使用自回归滑动平均模型(Auto-Regressive Integrated Moving Average, ARIMA) [2] 来预测下一时刻的流量值,之后使用支持向量回归模型(Support Vector Regression, SVR) [3] 对预测的流量值进行调整,以此来判断当前网络中的流量是否异常,提高了异常检测的实时性和准确性。
2. 相关工作
网络流量异常检测技术对于网络的监管有着重要的作用,被广泛应用于入侵检测、DDoS攻击检测等技术中。网络流量本质上是一个随机时间序列,随着时间序列分析的发展,预测模型和算法已研究了几十年。Box等人 [4] 提出的时间序列模型通过自回归(Auto-Regressive, AR),移动平均(Moving Average, MA)以及它们的组合为线性静止过程提供了解决方案。此外,常用的异常流量监测技术还有基于特征的检测。该方法通常需要建立一个详实的特征数据库,通过分析用户或主机日志 [5] ,或者统计网络中数据包的信息,例如流量、包头信息 [6] (如源目IP、源目端口、协议等)、内容特征 [7] 等,建立判定规则,与特征数据库中的数据进行匹配来检测。
从2008年以来,SDN的出现以及其转控分离、集中控制等优良性能,使得人们对于在SDN网络环境下的异常流量检测技术做了深入的研究。王强 [8] 将传统网络中的生成树算法进行改进,利用sFlow控制器实现网络流量的监控。由于熵的特性,其经常被用来异常流量的检测。Wang等人 [9] 、王文涛等人 [10] 分别将量子熵、Renyi熵作为SDN网络流量的统计数据,通过设定阈值来检测异常。Carvalho等人 [11] 提出了一个基于拓扑结构的网络流量监测系统。该系统通过OpenFlow协议收集网络流量,并对正常的流量行为构建数字签名,将当前流量与之进行对比,以此来识别异常的流量。Silva等人 [12] 提出了一个可对异常流量进行分类的ATLANTIC框架,该框架使用信息理论来计算流表熵值的偏差,并结合一系列的机器学习算法对流量进行分类。Boero等人 [13] 将入侵检测系统与SDN结合起来,选取机器学习中的支持向量机(support vector machine, SVM)作为核心算法,使用SDN控制器提取的流量特征作为SVM的输入,以此来训练模型并检测异常流量。作为监督学习算法的一种,SVM算法具有很高的分类精度,但是其对于未知类型的攻击无法进行有效检测。近年来,由于大数据、人工智能等算法的兴起,基于SDN网络的异常流量检测技术有了很大的扩展。王晓瑞等人 [14] 为了快速识别DDoS异常流量,提出了一种基于BP神经网络的检测算法,该算法提取流表的特征,经过BP神经网络的训练后实现对数据包进行检测。王伟 [15] 将网络中的流特征以五元组的方式保存,并分别使用表征学习、LSTM网络、CNN网络来训练模型,以此来实现对异常流的检测。此外,在不同的SDN部署环境中,研究人员对于异常流量检测技术的研究一直都在进行,在云平台 [16] 、5G网络 [17] 、物联网 [18] 、移动网络 [19] 等环境中,相继提出了一系列的检测技术。
本文受ARIMA的启发,能对具有周期性的时间序列有很好的预测效果,同时了解到网络流量具有很大的非线性和不规则性,需要有一个算法能对预测的结果进行矫正。而基于SVM在回归算法中的应用——SVR算法,对于多种特征的回归问题具有良好的预测效果,且计算复杂度都较低,能够快速地进行矫正。因此,为了快速准确地对网络流量进行检测,本文从整体网络中网络流量变化情况的角度来考虑,提出了一个ARIMA-SVR组合模型。该模型利用每天网络流量变化的周期性特征来预测下一时刻的网络流量值,再将现实中重大节日、事件等活动对于网络流量的影响作为影响因子,调整网络流量的预测值,使之更精准。该模型充分利用了整体网络的变化情况,使得检测算法的速度得到提升,同时降低了控制器的资源消耗,提升了模型训练的速度。关于ARIMA-SVR模型的建立过程可见第三章。
3. 模型建立
3.1. 自回归滑动平均模型
对于网络流量来说,其具有周期性。例如白天网络流量大,晚上流量小;用餐时间段内,流量小等特点,且每日的流量变化情况较为相似,具有明显的周期性。对于这种有明显周期性的时间序列,ARIMA模型具有较好的预测效果。
该模型可用ARIMA(p, d, q)来表示,其中,p表示自回归模型(AR)的阶数,d表示差分次数,q表示滑动平均模型(MA)的阶数,该模型的表达式形式为:
, (1)
其中已知参数是,
表示在时间t时的值;
表示随机白噪声序列,为独立误差。未知参数为:
为
的系数,即自回归系数;
为
的系数,即滑动平均系数;AR阶数p;MA阶数q;以及差分次数d。
ARIMA模型通过对过去时刻的时间序列进行平稳性检查,通过d次差分,将非平稳序列转化为平稳序列,之后使用自相关函数和偏自相关函数确定模型的p、q值范围,再使用BIC最小化原则选择最优的p、q值,最后通过多项式拟合等曲线拟合方法来求得待求系数
和
的值。
3.2. 支持向量回归
网络流量中不定时地就会出现较大的波动,例如节假日,演唱会,明星直播等事件发生时,都伴随着较大的网络流量波动。因此,需要一种模型,能够根据这些情况,适时地调整网络流量的预测值。针对这种有多种特征的回归问题,SVR有较好的预测效果。其是SVM在回归中的应用,泛化误差和计算复杂度都较低,且能够避免过学习的问题。
SVR的核心思想与SVM相同,都是将样本空间通过核函数映射到特征空间中,在特征空间实现对样本的回归。对于数据集
,其中
。引入松弛变量
、不敏感系数
以及惩罚参数
。当满足条件
时,可认为这些数据点都有同样的回归方程。其中w和b为待求系数,则该参数可由如下公式求出:
(2)
3.3. 异常检测模型
本文所使用的ARIMA-SVR模型充分利用了SDN网络对于网络监控的优点,快速采集网络流量,对其进行短期预测,以此来判断网络流量是否异常。我们的异常检测算法部署在SDN控制器内,如图1所示,控制器中主要包含了链路发现模块、流量采集模块、数据库模块、ARIMA预测模块以及异常检测模块这5部分。
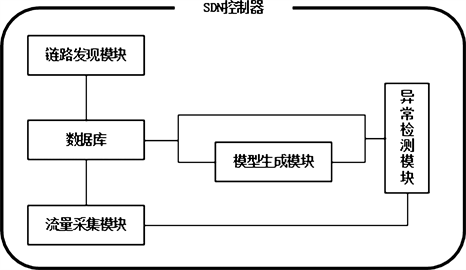
Figure 1. Diagram of module in SDN controller
图1. 控制器中模块构成示意图
首先,由链路发现模块对网络中的交换机链路进行发现。在控制器和交换机通过OpenFlow协议建立链接之后,控制器会定期向所链接的交换机发送LLDP (Link Layer Discovery Protocol) [20] 报文,根据返回的响应消息实现网络链路的发现。之后将收集到的网络拓扑,包括交换机及其使用的端口号,以集合的形式保存到数据库中。
之后,流量采集模块周期性地采集网络拓扑中各条网络的带宽使用情况。每经过一定的采样周期sampling_time,控制器就会通过OFPT_PORT_STATUS消息向所链接的交换机发出端口查询消息,得到当前时刻通过该交换机各个端口的数据包字节数current_byte,根据已记录的pre_byte计算出当前网络中各链路的已用带宽BandWidth:
, (3)
单位为KB/s,随后将current_byte赋值给pre_byte,以便下一次的计算。同时,将计算出来的已用带宽BandWidth保存到存储模块的数据库中。
至此,存储模块就存储了链路发现模块每次探测到的网络拓扑集合,以及流量采集模块每次计算出的交换机各端口不同时刻的网络带宽。这些存储的数据将会被ARIMA预测模块和异常检测模块所调用,用于后续的计算。
接着,ARIMA预测模块将会调用存储模块中存储的带宽使用数据,以一天内所测得的带宽数据作为基本单位,通过ARIMA算法训练模型,并预测下一次的带宽值
。由于不同天次,不同时刻,通过网络的流量有所不同,为了模型能够更好地适应这些变化所带来的误差,需要定时地更新模型。该模块可以在任意时间,以最新的训练数据重新训练模型,以使得模型与现实网络带宽情况更好的匹配。
最后,异常检测模块将使用SVR算法,对当前的网络流量进行异常检测。我们先定义热点事件(Hot Point)为能在短时间内引起网络流量激增的事件,例如,双11、比赛赛事、春节购票等情况。在热点事件发生前,网络中的流量变化较为平滑,但当热点事件发生后,大量的数据包被发送到目标主机,使得网络流量有一个向上的突增。由于ARIMA算法只是根据过去的流量数据进行预测的,但当网络中的流量因为热点事件而发生大幅度的改变后,这时预测出来的值就会与真实值有较大的差距。我们使用SVR算法对ARIMA预测的值进行调整,使其接近真实值。我们选择预测值
,是否周末(W),是否节日(F),是否有热点事件(H)这四个变量作为输入变量,通过训练好的SVR模型进行预测,得到修正值
,最终可得到最后的预测值:
. (4)
当真实值在预测值的
范围内时,我们认为当前网络中并没有发生异常,反之,则说明网络流量异常,需要进行后续的干预。
具体步骤如下:
1) 控制器使用LLDP协议发现所有链接的交换机。
2) 控制器周期性发送OFPT_PORT_STATUS数据包,获得当前时刻通过交换机各个端口的数据包总字节数。之后利用公式(3)计算已用带宽,并将其保存到数据库中。
3) 选取一定数量的带宽值,使用ARIMA算法训练模型,得到预测值
。
4) 使用预测值
,是否周末(W),是否节日(F),是否有热点事件(H)这四个变量作为输入特征,通过SVR训练模型并进行预测,得到修正值
。
5) 根据公式(4)得到最终的预测值
。如果下一时刻的真实值,没有超过1.2倍的
,则说明当前是正常流量,反之,则说明当前流量有异常。
4. 实验结果与分析
我们使用树形网络拓扑来仿真。如图2所示,该拓扑是一个3层的二叉树,包括7台交换机(核心交换机-c1,汇聚交换机-a1 a2,边缘交换机-e1 e2 e3 e4),6台主机以及2台服务器。
在实验中,我们将网络带宽设为1 Mbit,从2台服务器中随机选取一台作为流量的接收方。6台主机随机向服务器发送一定大小的流量。如图3所示,开始时通过的是正常的网络流量,网络带宽在60 KB左右。在90秒时,由于某热点事件的引发,使得网络流量在短期内有了突变,其增加到了128 KB/s。
我们对于原始数据进行平稳性和白噪声检验。对于非平稳序列,其存在单位根,因从可用单位根检验来判断序列是否平稳。其中ADF检验(Augmented Dickey-Fuller test,增项DF检验)就是一种检测序列中是否存在单位根的方法。该检验采用统计学中的假设检验方式,其假设序列存在单位根,即非平稳。因此,对于平稳序列,计算其在给定的置信水平上的显著性水平,若其统计值小于1%的临界值,就说明其严格拒绝原假设,即序列平稳。如表1所示,原始数据的统计量adf值分别小于critical_values中的1%,5%和10%的三个临界统计值,且p值小于0.01,说明此时数据符合平稳性的要求。同时,在白噪声检验中,p值小于0.05,说明此时的数据是随机分布的,符合白噪声检验的要求。

Table 1. Stationarity and white noise test
表1. 平稳性和白噪声检验
然后,训练最佳的ARIMA模型,获得p值和q值的取值,最优的取值应满足BIC最小的原则。根据这个原则,从表2中可知,最优的p值为10。然而q的值可为9和10,按照取最小值的原则,选取q为9。至此,我们得到了时间序列预测的最优模型ARIMA(10, 0, 9)。
Table 2. Related parameters of ARIMA model
表2. ARIMA模型相关参数
模型的预测效果如图4所示。ARIMA模型的预测值没有很好地贴近真实值,且当真实值有较大的流速变动时(例如在90秒时,流速超过120 KB/s),预测值变化的幅度不够。因此单纯的ARIMA模型无法有效地预测网络流量的变化情况。
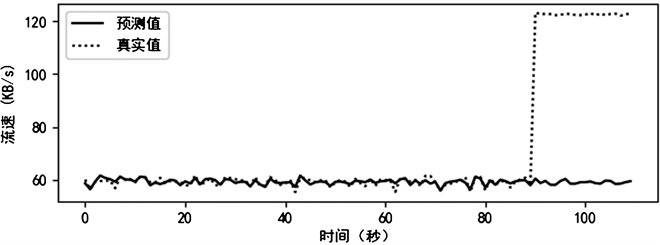
Figure 4. Prediction results of ARIMA model
图4. ARIMA模型预测结果
最后,将ARIMA模型的预测值与是否周末(W),是否节日(F),是否有热点事件(H)作为SVR模型的输入,训练模型,得到最后的预测结果。如图5所示,在预测的数据中,当真实值有较大上升时,预测值也会跟随上升。且绝大部分的真实值都小于1.2倍预测值。因此,所提的ARIMA-SVR模型能够很好的达到预期的效果。
由于本文所提模型来源于单一的ARIMA模型、SVM模型,因此将这些模型与本文所提出的ARIMA-SVR模型进行比较。模型判断效果的性能可由如下公式的度量:
. (5)
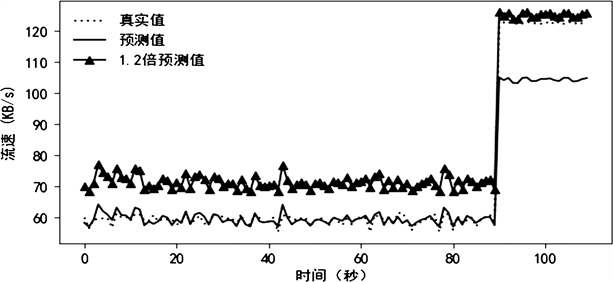
Figure 5. Prediction results of ARIMA-SVR model
图5. ARIMA-SVR模型的预测结果
分别使用正常流和异常流对模型进行测试,计算得到各模型的准确率。如图6所示,ARIMA-SVR模型对于正常流和异常流都具有较高的准确率,能够很好的分辨出网络流量的异常情况。ARIMA因为是基于正常流进行模型建立,故当由大量异常流导致的网络流量波动剧烈时,对于异常流检测的准确率较高。SVM模型属于有监督的机器学习模型,其对于正常流有较高的检测准确率,但对于未知类型的异常流,其准确率较低。
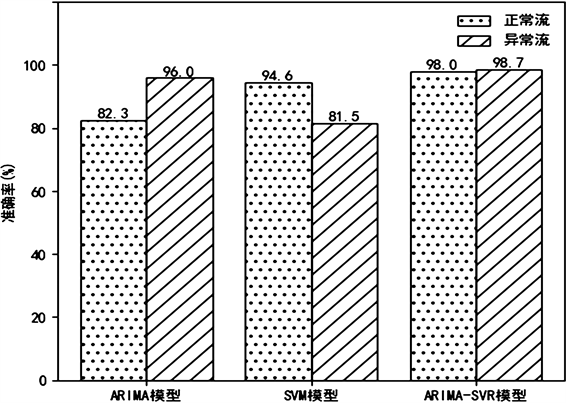
Figure 6. Accuracy of each anomaly detection model
图6. 各模型异常检测效果的准确性
为了进一步比较各模型的性能,我们采用检测率(Detection Rate, DR)和误报率(False Acceptance Rate, FAR)对模型的稳定性和可用性进行分析。检测率和误报率可由下面的公式得出:
, (6)
. (7)
检测率越低就意味着有大量的异常流没有被检测出来,这些流会给正常的访问造成困扰。误报率越高,就意味着大量的正常的数据包被错误检测,会使用户无法获得服务。如表3所示,本文的模型和其他两种模型相比,检测率高,同时误报率最低,检测效果更稳定。原因在于SVM模型对于部分偏差值较小的异常数据,无法有效的进行区分;ARIMA模型对于短时间内流量波动特别剧烈的值,无法得到有效检测。本文所提的ARIMA-SVR模型利用整体网络中的流量变化情况来判断当前网络是否异常,特别是对于DDoS攻击、端口扫描等攻击有较强的检测能力。
Table 3. Stability of each anomaly detection model
表3. 各模型异常检测效果的稳定性比较
5. 结论
基于SDN的网络使得控制器能够获取整个网络的信息。然而,现有的网络流量异常检测算法无法很好地适应SDN网络。因此,在本文中我们提出了一种基于时间序列预测和支持向量回归的方法,即ARIMA-SVR算法。该算法通过周期性的发送LLDP报文,可以有效的对网络的运行状态进行检测,并利用ARIMA模型来预测下一时刻的网络流量值,再将现实中重大节日、事件等活动对于网络流量的影响作为影响因子,使用SVR模型调整网络流量的预测值,使之更精准。该模型充分利用了整体网络的变化情况,使得检测算法的速度得到提升,同时降低了控制器的资源消耗,提升了模型训练的速度,提高了整体网络的效率。我们的实验结果有效地验证了算法的准确率以及稳定性和可靠性。
对于今后的工作,我们计划继续优化算法,使其能适应各种类型的网络流量,并能够在多控制器的网络中得到应用。
基金项目
本研究由国家自然科学基金资助项目(61501108)提供支持。
NOTES
*通讯作者。