1. 引言
随着信息技术特别是互联网、物联网和云计算等技术的迅猛发展,网络空间中所蕴含的信息量呈指数级增长。信息过载现象愈发严重,给人们带来很大的信息负担。推荐系统作为一种有效的信息过滤手段是当前解决信息过载问题及实现个性化信息服务的有效方法之一。为了提供高质量和个性化的推荐,推荐系统需要收集大量的用户信息、用户行为等,尤其是社交媒体上的用户活动数据,例如标记/评级记录、评论、登记或其他类型的数据。在实践中,许多用户愿意将他们在社交媒体上的在线活动的数据(或数据流)发布给服务提供商,以获得高质量的个性化推荐。然而,他们通常认为来自社交媒体的部分数据是私人的,例如性别、收入水平、政治观点或社会交往等。虽然用户可能拒绝发布私有数据,但公共数据和私有数据之间的内在关联往往会导致严重的隐私泄漏。例如,一个人的政治归属可以从对电视节目的评价中推断出来 [1];一个人的性别可以从社交网络上的位置活动数据中推断出来 [2]。这些研究表明,私有数据经常遭受推理攻击 [3],敌人通过分析用户的公共数据以非法获取有关其私有数据。因此,在将公共数据发布到推荐系统时,保护用户私有数据至关重要。
为了解决这一问题,保护隐私数据的发布平台被广泛研究 [4]。它的基本思想是通过在公开数据发布之前对其进行扭曲,以牺牲公共数据在后期处理阶段的效用,来保护私有数据。对于推荐引擎的用例,效用是指基于被扭曲的公共数据的个性化性能,即推荐引擎是否能够根据模糊数据准确预测个人偏好。在隐私和隐私之间存在一种内在的平衡。
差分隐私 [5] 是一种众所周知的技术,保证用户对具有任意背景知识的攻击者的隐私。在此背景下,还提出了信息论隐私保护方法。他们试图基于各种基于熵的度量(如条件熵 [6] 和相互信息 [7])定量地测量隐私泄漏,并基于这些度量设计隐私保护机制,提出了几种隐私保护信息熵模型 [8]。尽管差分隐私的概念与信息论方法相比更为严格,但是后者更直观、更易访问,符合许多应用领域的实际需求。尤其是信息论可以提供直观的指导,通过观察和分析用户的公共数据(即公共数据中的私人数据的隐私泄漏),定量测量对手可以学习的用户私人信息量。在基于信息论现有的文献中,现有的数据模糊方法主要是通过使用欧几里得距离 [9] 、肯德尔等级相关系数距离 [10] 等指标来限定数据失真,从而确保数据的实用性。它们类似于限制对项目预测用户评级的损失,目标是将预测评分和用户实际评分之间的整体差异减少。
这些度量数据失真的方法,只单方面地考虑了失真数据与真实数据的距离,并没有保留数据变换之后,两两特征之间的关联度。而基于因子分解机的推荐技术,主要是使用特征之间的关联进行推荐,因此,本文考虑使用自定义距离KFC,将数据模糊过程中产生的特征关联度损失进行约束,保留特征之间的关系。
2. 理论基础
本节首先介绍基于因子分解机的推荐算法,然后介绍近年来用于隐私度量的信息熵及其实现机制。
2.1. 因子分解机
因子分解机最初是为了解决类别特征存在较多取值是经过One-Hot编码以后数据国语稀疏导致模型学习能力欠佳的问题,同时也解决了线性模型的特征之间无法进行组合的问题,某些特征经过关联以后,与标签之间的关联性会增强。比如有的女生喜欢化妆品,男生喜欢运动产品。单纯的使用 是无法实现特征之间的关联的。为了实现特征之间的组合,可以在线性的基础上引入二次项:
是无法实现特征之间的关联的。为了实现特征之间的组合,可以在线性的基础上引入二次项:
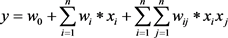 (1)
(1)
n为一个样本的特征个数。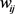 为特征
为特征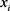 和
和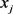 之间的因子,共有
之间的因子,共有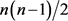 个。
个。
在数据进行训练之前,都会进行One-Hot编码,这样在编码之后数据的维度会特别大,而且会存在大量的0。这样的稀疏矩阵对于求解上面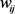 是非常不利的。因此对于每一个特征可以引入一个辅助向量
是非常不利的。因此对于每一个特征可以引入一个辅助向量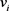 ,使其满足
,使其满足 其中
其中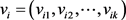 ,因此式(1)可以写成:
,因此式(1)可以写成:
 (2)
(2)
通过矩阵对称性化简等式(2)为:
 (3)
(3)
使得时间复杂度从 降低为
降低为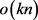 。因此,在特征数量急剧膨胀导致计算量陡增的背景下,因子分解机是一种十分高效的模型。
。因此,在特征数量急剧膨胀导致计算量陡增的背景下,因子分解机是一种十分高效的模型。
2.2. 推理攻击
假定攻击者使用方法q来推断出y (y为隐私数据),并且攻击者总是试图使用q推到出y的代价(c)最小,以此来得到方法q。
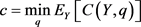 (4)
(4)
其中 是使用q推导出y的预期成本函数。发布数据x进行数据混淆,得到数据x,通过解决以下问题,可以得到q。
是使用q推导出y的预期成本函数。发布数据x进行数据混淆,得到数据x,通过解决以下问题,可以得到q。
 (5)
(5)
攻击者在观察混淆数据 后的成本收益为:
后的成本收益为:
 (6)
(6)
 表示敌手在观察
表示敌手在观察 后,获取的隐私代价。隐私保护的理念是,找到
后,获取的隐私代价。隐私保护的理念是,找到 ,使
,使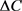 最小,并且能够使用
最小,并且能够使用 进行推荐。
进行推荐。
3. 框架流程
为应对基于用户隐私的推理攻击,设计了基于隐私保护服务器的推荐系统架构(PriFM)。整个系统架构主要由用户、数据发布平台、第三方服务器三部分组成。推荐及隐私保护过程如下:
1) 首先用户将自己的活动数据上传到社交网站,尤其是标签、评分、评论等能够反映个人偏好的活动。当用户想要订阅第三方服务时,授予第三方访问此类活动数据的权限,得到第三方的服务。
2) 根据用户自己的隐私标准,数据发布平台对其历史活动数据进行模糊处理,以保护用户指定的私有数据不受推理攻击。当用户在社交媒体上连续报告其活动时,在线数据发布模块在将其活动流发送到第三方服务之前,对其活动流中的每个活动进行模糊处理。所有的数据混淆都是在保证个性化的基于因子分解机的推荐的效用下进行的,通过限制混淆数据引起的特征关联度损失。
3) 尽管第三方服务接收到模糊的公共数据,但仍然可以向用户提供高质量的基于因子分解机的推荐。
4. 历史数据发布
首先,为了减少学习最佳混淆函数所产生的问题复杂性,在框架中结合聚类算法。由于类似的用户活动常常引起类似的隐私泄漏 [11],因此,使用公共数据将类似用户聚集到一个组,将大量用户分为有限的数组集合。然后,基于用户聚类,从公共数据中定量地测量用户指定的私有数据(如性别)的隐私泄漏,在给定的失真预算下通过最小化隐私泄漏来学习最优模糊函数,并且限制特征关联度的损失。最后,基于所学习的模糊函数,进行概率数据模糊处理。
4.1. 用户聚类
从每一个用户的公共数据中直接学习最优混淆函数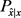 ,会导致复杂度按用户的数量的二次增长。为了减少问题的复杂性,用户聚类阶段根据用户的公共数据向量将用户聚类成有限数量和固定数量的组。我们根据用户的历史记录对用户集进行聚类,为了简单起见,采用欧氏距离的层次聚类,根据聚类结果,我们得到了用户U到聚类G的映射,其中每个元素g (
,会导致复杂度按用户的数量的二次增长。为了减少问题的复杂性,用户聚类阶段根据用户的公共数据向量将用户聚类成有限数量和固定数量的组。我们根据用户的历史记录对用户集进行聚类,为了简单起见,采用欧氏距离的层次聚类,根据聚类结果,我们得到了用户U到聚类G的映射,其中每个元素g ( )是对应聚类的质心。
)是对应聚类的质心。
4.2. 聚类模糊函数学习
4.2.1. 信息熵隐私度量
隐私泄露通过攻击者在观察混淆数据以后,产生的信息增益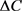 来测量。Calmon等人 [12] 证明了
来测量。Calmon等人 [12] 证明了 可以表示为混淆数据与隐私数据之间的互信息。
可以表示为混淆数据与隐私数据之间的互信息。
 (7)
(7)
如上所述,我们使用概率模糊函数 生成发布的混淆数据
生成发布的混淆数据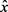 ,因此,联合概率
,因此,联合概率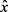 和y可以通过下面来计算:
和y可以通过下面来计算:
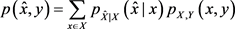 (8)
(8)
边际概率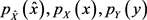 可以通过以下计算:
可以通过以下计算:
 (9)
(9)
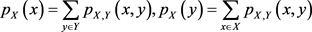 (10)
(10)
结合上述公式,发布公共数据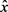 和隐私数据y可以描述为:
和隐私数据y可以描述为:
 (11)
(11)
其中第二项是y的熵,即为给定数据集中指定隐私数据的常量。因此,在互信息中,忽略此项,得到:
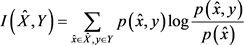 (12)
(12)
结合公式(8)和(9),互信息可以只描述为两个因素,使用给定的数据集产生的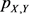 和混淆函数
和混淆函数 :
:
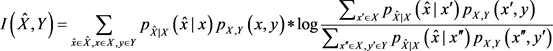 (13)
(13)
 在给定的失真约束
在给定的失真约束 ,通过最小化
,通过最小化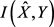 取得。
取得。
4.2.2. 距离度量
基于因子分解机的推荐算法主要是利用两两特征组合,引入交叉项特征,提高模型得分,因此对数据混淆过程中产生的两两特征间关联度损失非常敏感。因此,不能使用其他类型的损失来衡量,如欧几里德、平方L2、肯德尔等级相关系数来衡量。表1为项目评分特征关联损失的实例,原始评分模糊为b或者c,当两个模糊数据的欧式距离完全相同时,所产生的特征关联损失不同。b两两特征间的差异与a相同,没有产生任何特征关联度损失,c则产生的特征关联度损失为5 (设 ),表明相同的数据失真预算用欧几里德距离意味着不同的特征关联度的损失。因此,考虑到数据造成的特征关联度损失模糊处理对于因子分解机推荐算法至关重要,我们定义一种类似于肯德尔等级相关系数距离——KFC,用来衡量两个列表之间的成对关联度不一致的数量。对于两个用户A和B,分别将其公共数据向量表示为
),表明相同的数据失真预算用欧几里德距离意味着不同的特征关联度的损失。因此,考虑到数据造成的特征关联度损失模糊处理对于因子分解机推荐算法至关重要,我们定义一种类似于肯德尔等级相关系数距离——KFC,用来衡量两个列表之间的成对关联度不一致的数量。对于两个用户A和B,分别将其公共数据向量表示为 和
和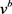 ,则距离
,则距离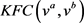 的计算方式为:
的计算方式为:
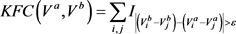 (14)
(14)
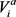 为列表
为列表 中项目i的项目得分,依次类推。
中项目i的项目得分,依次类推。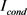 是一个指示函数,当
是一个指示函数,当 为真时,等于1,否则等于0。
为真时,等于1,否则等于0。 为允许两两特征关联度差异的最大值,区间为[0, t],t为项目评分的最大值。将等式计算出的成对关联度不一致的数量除以
为允许两两特征关联度差异的最大值,区间为[0, t],t为项目评分的最大值。将等式计算出的成对关联度不一致的数量除以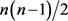 ,标准化到[0,1]区间,值为1表示最大不一致,值为0表示两个列表有相同的特征关联度,则:
,标准化到[0,1]区间,值为1表示最大不一致,值为0表示两个列表有相同的特征关联度,则:
 (15)
(15)
在实践中,当有n维特征时,计算两两特征之间的关联度距离,需要进行 次的成对比较,得到的计算复杂度为
次的成对比较,得到的计算复杂度为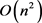 。为了提高计算效率,我们使用自举采样来近似计算特征间的关联度,并不比较所有特征对之间的关联度,而是随机抽取S对特征进行比较,在统计S对特征关联度之后,通过除以
。为了提高计算效率,我们使用自举采样来近似计算特征间的关联度,并不比较所有特征对之间的关联度,而是随机抽取S对特征进行比较,在统计S对特征关联度之后,通过除以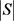 将其规范化:
将其规范化:
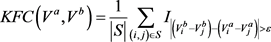 (16)
(16)

Table 1. Data before and after project scoring confusion
表1. 项目评分混淆前后数据
4.2.3. 模糊函数学习
模糊处理功能是根据单个活动数据进行学习的,其中活动是指项目上的评级、标签等。为了将公共数据i (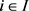 )中的私人数据y的隐私泄漏降至最低,我们遵循用于群集模糊功能学习的相同隐私实用程序权衡框架,并尝试将
)中的私人数据y的隐私泄漏降至最低,我们遵循用于群集模糊功能学习的相同隐私实用程序权衡框架,并尝试将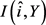 最小化。为了更好地约束特征关联度损失,我们事先计算两两特征之间的关联度,并进行存储,再基于Bootstrap采样近似,来计算总的特征间的关联度。总之,我们首先通过经验计算
最小化。为了更好地约束特征关联度损失,我们事先计算两两特征之间的关联度,并进行存储,再基于Bootstrap采样近似,来计算总的特征间的关联度。总之,我们首先通过经验计算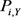 ,并使用算法1学习每个用户u的最优模糊函数
,并使用算法1学习每个用户u的最优模糊函数 ,这也是一个凸优化问题。
,这也是一个凸优化问题。
算法1. 模糊函数学习
输入:联合概率 ,失真预算
,失真预算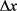 ,用户公共数据向量
,用户公共数据向量
输出:模糊函数
1. 求解最优化问题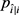
2. 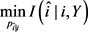
3. 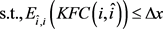
4. 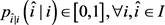
5. 
6. 返回模糊函数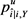
4.3. 概率在线活动混淆
基于学习到的模糊函数,我们使用算法2对来自用户活动流的每个传入活动进行模糊处理。对于项目i上的每个传入活动,我们首先获得相应的模糊函数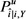 来保护u指定的私有数据y。然后,我们基于
来保护u指定的私有数据y。然后,我们基于 对项目i上的活动进行模糊处理,并将活动i映射为项目i上作为模糊数据。
对项目i上的活动进行模糊处理,并将活动i映射为项目i上作为模糊数据。
算法2. 混淆在线活动数据
输入:模糊函数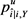 ,失真预算
,失真预算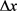 ,活动数据i
,活动数据i
输出:模糊数据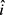
1. 求解最优化问题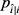
2. 
3. 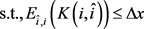
4. 
5. 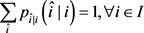
6. 返回模糊函数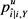
5. 实验结果与分析
5.1. 评价指标
(1) 推荐质量评估
评价推荐系统推荐质量的度量标准主要有统计精度度量方法、决策支持精度度量方法和排名度量方法。本文实验采用统计精度度量方法中均方根误差作为评价指标来衡量评分预测推荐精确度:
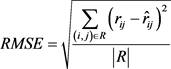
其中,R表示评测集中的评分矩阵, 表示实际评分,
表示实际评分, 表示预测评分。RMSE越小,说明推荐算法的精确度越好,推荐质量越高。
表示预测评分。RMSE越小,说明推荐算法的精确度越好,推荐质量越高。
(2) 隐私保护性能评估
对私有数据的推断攻击试图从用户发布的公共数据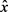 中推断出用户的私有信息y (例如,性别),这可视为离散数据的分类问题。因此,我们使用两种推理攻击方法直接评估隐私保护的性能,即支持向量机和朴素贝叶斯。假设敌人已经根据一些非隐私意识用户的原始公共数据x和私有数据y训练了他们的分类器。我们随机抽取50%的用户作为非隐私意识用户进行分类训练,然后根据模糊活动数据
中推断出用户的私有信息y (例如,性别),这可视为离散数据的分类问题。因此,我们使用两种推理攻击方法直接评估隐私保护的性能,即支持向量机和朴素贝叶斯。假设敌人已经根据一些非隐私意识用户的原始公共数据x和私有数据y训练了他们的分类器。我们随机抽取50%的用户作为非隐私意识用户进行分类训练,然后根据模糊活动数据 对其余用户的隐私数据y进行推理攻击。我们使用曲线下面积(AUC)来评估推理攻击的性能。在实验中,我们将此值(1 - AUC)作为隐私保护指标。较高的(1 - AUC)值意味着更好的隐私保护。当AUC = 0.5时,则意味着任何推理攻击方法的性能都不比随机猜测好。
对其余用户的隐私数据y进行推理攻击。我们使用曲线下面积(AUC)来评估推理攻击的性能。在实验中,我们将此值(1 - AUC)作为隐私保护指标。较高的(1 - AUC)值意味着更好的隐私保护。当AUC = 0.5时,则意味着任何推理攻击方法的性能都不比随机猜测好。
5.2. 数据集
本文采用 GroupLens研究组提供的MovieLens数据集ML-100k对算法进行评估,该数据集包含了943个用户对1682部电影的100,000个评分记录,每个用户至少对20部电影评 过分,评分范围为1~5之间的整数,代表喜好程度从低到高。该数据集的评分稀疏度为93.7%。实验中,我们将数据集平均分成5组,采用交叉验证的方法进行实验,训练集与测试的大小比例为4:1。
基于公开的数据集,首先研究隐私保护与基于因子分解机推荐性能之间的权衡。其次,与其他隐私保护推荐算法进行对比。最后,探讨了不同损失度量下基于因子分解机推荐的效用保证。
5.3. 实验比较与分析
5.3.1. 隐私保护与效用权衡
使用以下两种方法进行比较:
随机混淆:对于历史数据模糊处理,给定的概率p,随机模糊每个用户的公共数据向量 [13]。p控制了扭曲预算。
差分隐私:不关心攻击者所具有的背景知识,即使攻击者已经掌握除了一条记录之外的所有记录的
敏感信息,该记录的敏感信息也无法被披露 [14]。差分隐私有两种实践机制,拉普拉斯机制和指数机制,前者适用于结果为数值型的保护,后者适用于结果为非数值型的保护。在这里,我们使用前者来进行比较。
在这个实验中,我们调整不同方法中的模糊处理预算,以直接显示隐私实用程序的权衡。PriFM框架的参数主要是控制失真预算。我们将性别是所有实验中的私人数据,为了运行时效率,根据经验,选择用户群的数量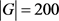 和对样本的数量
和对样本的数量 ,
,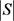 用于估计每个用例的KFC距离。
用于估计每个用例的KFC距离。
图1显示了在电影数据集上不同隐私保护数据模糊处理方法的隐私–效用权衡结果。首先,我们清楚地观察到隐私保护和为所有方法启用基于FM的推荐的效用之间的权衡。虽然,高度扭曲的公共数据使得敌人难以推断出用户的私人数据,有更好的隐私保护。但是,高度扭曲的公共数据会导致较高的数据效用损失,也会阻止推荐算法准确预测用户的偏好。其次,我们能够观察到,与其他方法相比,PriFM始终能够在所有情况下实现更好的隐私保护和更高的效用。
Figure 1. Different approaches to privacy-utility tradeoffs on the movielens-1m dataset
图1. 不同的方法在Movielens-1M数据集上进行隐私-效用权衡
5.3.2. 隐私保护性能
PrivFM框架旨在保护用户特定的私人数据,在这个实验中,我们将性别作为隐私数据,并报告定制的隐私保护性能。我们调整了所有数据模糊处理方法的失真预算,以保持相同的数据效用。图2显示了电影数据集上的性别隐私保护结果。我们观察到,在保护私人性别时,我们的框架优于所有其他方法,因为它实现了1-AUC的最高值。这表明,在相同的数据下,个人的隐私可以达致更佳的私隐保障。

Figure 2. Privacy data-gender measurement
图2. 隐私数据–性别衡量
5.3.3. 不同损失度量的效用
在本实验中,我们使用我们的方法研究了隐私–效用权衡的不同损失度量,包括欧几里得度量,余弦距离和基于特征损失的度量的KFC距离。我们保持其他参数和以前的实验一样。图3显示了不同损失指标下的隐私–效用权衡。首先,我们观察到,基于KFC的损失指标优于其他两个指标的指标,因为它同时实现了更好的隐私保护和效用。换句话说,限制数据混淆造成的特征关联度损失可以更好地保持公共数据中的特征之间的关系,从而降低学习FM算法的效用损失。PriFM可以有效地提高基于排序的推荐在相同的隐私保护水平下的效用。
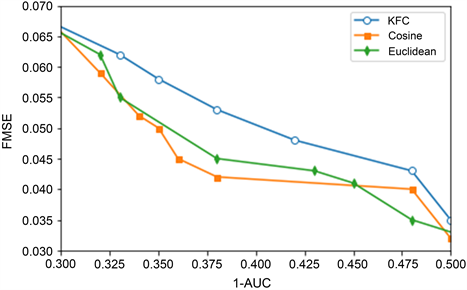
Figure 3. Privacy utility tradeoffs, different distance measures
图3. 隐私效用权衡——不同距离度量
6. 结束语
本文介绍了一种可定制、连续的隐私保护的社交媒体数据发布框架,通过发布模糊的用户活动数据,不断地保护用户指定的数据免受推理攻击,同时仍然确保所发布数据的实用性,以增强基于因子分解机的推荐。为了提供定制的保护,我们学习了最佳的数据混淆方法,以便将用户指定的私有数据的泄漏降到最低,为了确保数据实用性,减少特征间的关联性的损失,我们使用类似于Kendall-t距离来限制数据混淆过程中产生的关联度损失KFC。我们通过大量实验证明PriFM框架可以提供对私有数据的有效保护,同时还可以为基于因子分解机的推荐用例保留已发布数据的效用。如何在隐私保护和推荐质量之间寻找一个平衡是一个值得深入研究的课题。