1. 引言
异方差数据常常出现在经济学、生物学、环境科学等领域,是很多统计学家研究的热点方向之一。其中处理此类数据最常用的方法是方差建模法,即不仅对均值建立回归模型,同时也对方差建立回归模型进行分析,有些文献称之为联合均值与方差模型。这个模型主要体现了对方差的重视,它能更好地解释数据变化的原因和规律。特别最近这些年已经有很多学者对基于方差建模的异方差模型研究了模型的参数估计、变量选择以及异方差检验等统计推断。例如,吴刘仓等 [1] 对联合均值与方差模型提出一种同时对均值模型和方差模型的变量选择方法;李双双等 [2] 研究了联合均值与方差混合专家回归模型的参数估计问题;赵远英等 [3] 对响应变量带有不可忽略缺失数据的联合均值与方差模型的贝叶斯估计问题进行了研究;戴琳等 [4] 基于联合均值与方差模型研究了模型的参数估计与基于数据删除模型考虑了统计诊断问题。其它类似的相关研究还可以具体参见文献 [5] [6] [7] [8]。但是这些文献大多数都是基于参数异方差模型展开统计分析的,很少有文献和学者研究基于方差建模的变系数异方差模型的贝叶斯参数估计、异常点识别等统计推断问题。
因此本文针对方差建模的变系数异方差模型,应用Gibbs抽样和Metropolis-Hastings算法相结合的混合算法研究模型的贝叶斯估计和基于K-L距离研究贝叶斯数据删除影响诊断方法,以识别模型的异常点。
2. 模型与符号
2.1. 基于方差建模的变系数异方差模型
针对异方差数据和基于方差建模的思想,提出了如下变系数异方差模型:
(1)
其中
为响应变量且令
;
,
是与
的均值相关的解释变量的观测值,且
是均值模型中一个
维未知回归参数向量,
是一个
维的未知函数参数;
是与
的方差相关的解释变量的观测值,且
是方差模型中一个
维的未知回归参数向量。另外,
是一个已知函数,为了模型的可识别性,一般假设
是一个单调函数且
。在本文中
。
由模型(1),可以获得如下似然函数
(2)
其中
。因为
是非参数,(2)式还不能直接进行优化。因此,首先用B样条来逼近非参数函数
。具体如下,令
是[0,1]区间上的一个剖分。用
作为内节点,那么就有阶为M和维数为
的正则化B样条基函数,这也形成了线性样条空间的一个基。节点选择一般是样条光滑估计中的一个重要方面。类似于文献 [9],内节点的数目选取为
的整数部分。这样,由
逼近
,其中
是基函数向量和
。利用这些符号,(1)式中的均值模型可以写成以下形式:
其中
。
这样,似然函数(2)可以被重新写成以下形式:
,(3)
其中
。
2.2. K-L距离
K-L距离也称作K-L信息,具有距离和信息的某些性质,在统计上以反映两个模型或分布的差异而著称。根据韦博成 [10] 对K-L距离的介绍,密度函数为
与
的两个分布的K-L距离
被定义为:
,其中
表示对
求期望。
3. 贝叶斯分析
3.1. 先验分布
为了应用贝叶斯方法来估计模型(1)中的未知参数,需要给出未知参数的先验分布信息。为了简便,假设
和
相互独立且具有正态先验分布,分别为
,
,
,
,其中“IG”表示逆gamma分布,并且假设超参数
和
是已知的。
3.2. Gibbs抽样和条件分布
基于式子(3),按照以下过程用Gibbs抽样从后验分布
中进行抽样,其中
。
步骤 1. 令参数的初值
。
步骤 2. 基于
,计算
。
步骤 3. 基于
按照以下抽取
;
· 抽样
:
(4)
· 抽样
:
, (5)
其中
,
,
。
· 抽样
:
,(6)
其中
,
。
· 抽样
:
(7)
步骤4。重复步骤2和3。
这样就通过以上算法产生了样本序列
。从(4)~(7)式中很容易发现,条件分布
是熟悉的正态分布和逆gamma分布。从这两个分布抽取随机数是比较容易的。但是条件分布
是一不规则且相当复杂的分布,如何从这个分布中抽取随机数有点困难。在这里主要应用MH算法抽取随机数。选择正态分布
作为建议分布,其中通过选择
,来使得接受概率在0.25与0.45之间,且取
。
3.3. 贝叶斯估计
利用以上提出的计算过程来产生观测值来获得参数
和
的贝叶斯估计。令
是通过上述混合算法从联合条件分布
中产生的观测值,那么
和
的贝叶斯估计为:
。
根据文献 [11] 有,当J趋于无穷时,
是对应后验均值向量的相合估计。类似地,后验协方差矩阵
的相合估计可以通过观测
的样本协方差矩阵来获得,即
。
这样,后验标准误就可以通过该矩阵的对角元素来获得。
3.4. 贝叶斯诊断
在贝叶斯统计诊断分析中已存在许多诊断统计量用来评价个体观测对参数后验分布的影响,在这主要基于K-L距离研究贝叶斯数据删除影响的统计诊断方法。对任意的
,记
是第i个个体观测数据点,
为完全数据集,
为完全数据集D删除第i个个体观测数据点得到的数据集,
与
分别表示基于数据D与
的似然函数,则
于数据D与
的后验分布分别为
,
。根据Cho等 [7] 的讨论,定义K-L距离为:
, (8)
其中P与
分别表示
基于数据D与
的后验分布,注意到K-L距离
是完全数据集D删除第i个数据点前后对参数
后验分布影响的一种很好的度量。经过简单的计算(8)式变为:
, (9)
其中
表示
基于数据D的后验期望。由Gibbs抽样算法抽取的随机观测序
,可以得到K-L距离
的估计为:
。 (10)
对任意的
,当
很大时,可以诊断第i个个体观测数据点为异常点。
4. 模拟研究
在这通过模拟研究来说明本文所提出的贝叶斯分析方法的有效性。选择均值模型为
和方差模型为
,其中均值参数和方差参数的真实值分别为
和
,另外
,
,
;
分别是
和
的协变量向量,其中的元素产生于均值为零,协方差矩阵为
的正态分布。这样响应变量
就可以从多元正态分布
中产生。
为了调查贝叶斯分析方法对先验分布的敏感程度,考虑以下三种有关未知参数
的先验分布中超参数值的设置的情形:
TypeI:
。这种设置表示具有很好的先验信息。
TypeII:
。这种设置表示具有较差的先验信息。
TypeIII:
。这些超参数值的设置代表的是没有先验信息的情况。
在上面的各种情形下,应用联合Gibbs抽样和Metropolis-Hastings算法的混合算法来计算未知参数和光滑函数的贝叶斯估计。在模拟中分别令样本量n = 80和n = 150。对于每一种情形,重复计算100次。对于每次重复产生的每一次数据集,MCMC算法的收敛性可以通过EPSR值来检验,并且在每次运行中观测得到在3000次迭代以后EPSR值都小于1.2。因此在每次重复计算中丢掉前3000次迭代以后再收集J = 5000个样本来产生贝叶斯估计。参数贝叶斯估计的模拟结果概括在表1中。为了调查估计函数
和
的精确度,画出了在不同样本量和三种先验分布情形下非参数函数的平均估计曲线和真实曲线,并且展示在图1~6中。
在表1中,“Bias”表示基于100次重复计算未知参数的贝叶斯估计与真值的偏差的绝对值,“SD”表示前面给出的后验标准误的平均估计,和“RMS”表示的是基于100次重复计算的贝叶斯估计的均方误差的算术平方根。从表1中可以获得i) 在估计的偏差、RMS和SD值方面,不管何种先验信息贝叶斯估计都相当精确;ii) 当样本量逐渐变大时,估计也变得越来越好。从图1~6中展示了不管何种先验信息,估计出来的非参数函数的曲线与相应的真实函数的曲线逼近得都比较好。总之,从以上结果可以看出本文所提出的贝叶斯估计方法能很好地恢复变系数异方差模型中的真实信息。

Table 1. Bayesian estimation of model parameters under different sample sizes and prior distributions
表1. 不同的样本量和先验分布下模型参数的贝叶斯估计结果
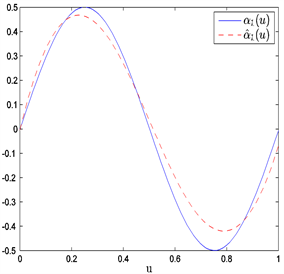
Figure 1. The average estimated curves of nonparametric parts
and
when n = 80 and prior information of Type I
图1. 当n = 80和Type I先验信息下非参数部分
和
的平均估计曲线
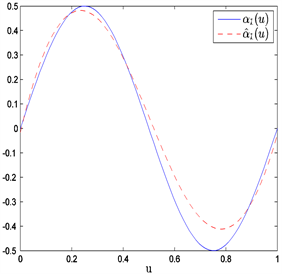
Figure 2. The average estimated curves of nonparametric parts
and
when n = 80 and prior information of Type II
图2. 当n = 80和Type II先验信息下非参数部分
和
的平均估计曲线
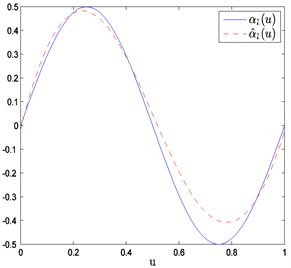
Figure 3. The average estimated curves of nonparametric parts
and
when n = 80 and prior information of Type III
图3. 当n = 80和Type III先验信息下非参数部分
和
的平均估计曲线
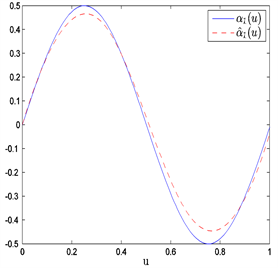
Figure 4. The average estimated curves of nonparametric parts
and
when n = 150 and prior information of Type I
图4. 当n = 150和Type I先验信息下非参数部分
和
的平均估计曲线
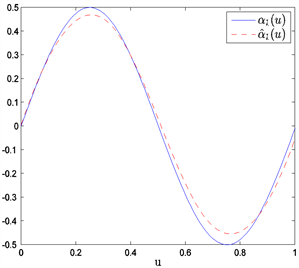
Figure 5. The average estimated curves of nonparametric parts
and
when n = 150 and prior information of Type II
图5. 当n = 150和Type II先验信息下非参数部分
和
的平均估计曲线
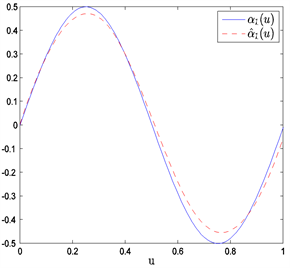
Figure 6. The average estimated curves of nonparametric parts
and
when n = 150 and prior information of Type III
图6. 当n = 150和Type III先验信息下非参数部分
和
的平均估计曲线
最后为了检测根据K-L距离来识别异常点的效果,在第10个个体观测数据点的响应变量加10构成人工数据集D。然后对人工数据集D应用本文介绍的贝叶斯影响诊断方法来检测影响观测。其中MCMC算法的收敛性可以通过EPSR值来检验,并且发现在3000次迭代以后EPSR值都小于1.2。因此在计算中丢掉前3000次迭代以后再收集J = 5000个随机样本来通过(10)式计算K-L距离
。图7和图8报道了相应的诊断结果。正如预期的一样,通过图7和图8很容易就发现,第10个个体观测数据点被诊断为异常点,且诊断方法对先验分布超参数取值的选取不是很敏感。
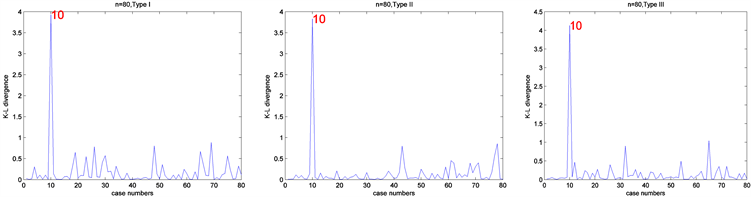
Figure 7. Bayesian case deletion diagnosis results based on different prior information and n = 80
图7. 当n = 80时,基于不同的先验信息下贝叶斯数据删除影响诊断的数值结果
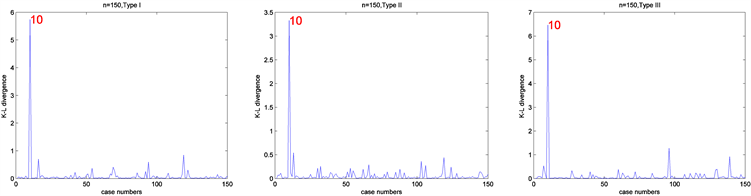
Figure 8. Bayesian case deletion diagnosis results based on different prior information and n = 150
图8. 当n = 150时,基于不同的先验信息下贝叶斯数据删除影响诊断的数值结果
5. 结论
本文针对变系数异方差模型,基于Gibbs抽样和MH算法相结合的混合算法,以及根据K-L距离研究模型的贝叶斯估计和贝叶斯统计诊断方法。模拟研究显示了模型与贝叶斯方法的可行性和有效性。
基金项目
浙江省高校重大人文社科攻关计划项目资助(2018QN037)。