1. 引言
目前,我国农田受虫害影响日渐严重,虫情分析可以针对不同区域的农田虫情状况,制定不同的治理农田害虫方案 [1] 。传统的虫情分析靠人工收集与统计,耗时耗力。目前,虫情测报灯在虫情采集中应用较为广泛 [2] 。它主要依靠灯光诱捕装置捕获农业害虫,实现自动诱集、杀虫、虫体分散、拍照等作业,并实时地将虫情信息上传至云平台。虫情测报灯的投入使用可帮助植保人员高效地进行虫情分析,提高测报工作效率和准确率 [3] 。在统计害虫种类和数量时,存在着耗时耗力和准确性差等不足。随着深度学习的发展,通过虫情测报灯所采集到的图像文件,利用图像检测和识别算法对其统计害虫种类与数量或许可以解决人工统计上耗时耗力的问题。
2. 数据探究与预处理
深度学习技术中,需要相对较高的数据质量,它在一定程度上影响了所训练的模型效果,所以数据探究与预处理是在深度学习技术中不可或缺的一部分。经过对数据探究可以更好地了解数据集,更好地针对数据集的特点做不同的预处理操作,提高模型的识别与检测效果。
2.1. 数据探究
2.1.1. 数据资料
本文的灯诱害虫数据集来源是由第十届“泰迪杯”数据挖掘挑战赛A题的官方赛事数据,分为灯诱害虫图像数据与害虫位置坐标数据,图像尺寸为5472 × 3648 px,以jpg格式存储,共28种害虫图像数据。
2.1.2. 数据噪声问题
在所给的数据集中,许多害虫存在重叠,以及一些未给标签的害虫种类,还有许多害虫的残肢、残翅和落叶树枝等等,如所给数据集中图1所示。

Figure 1. Noise problem of lamp-induced pest data
图1. 灯诱害虫数据噪声问题
该数据集的噪声较为复杂,如果直接使用原图进行训练的话,可能导致之后的识别结果中,会把一些残肢,残翅等等也认为是一些体型较小的昆虫,对结果影响较为严重。本文选择利用所给标签进行分割,尽量使特征占到图像的较大比例,减少影响。
2.1.3. 昆虫相似度较大
训练数据集中包含了螟、蛾、虱属等。同属下的特征相似度较大,带入模型中很容易将其互相混淆,导致模型的准确率大大降低。一般不同属类的相似度差异较大,但螟属和蛾属的大多种类从颜色、大小、翅膀等特征上来看较为相似,大螟与线委夜蛾的颜色与身体特征相似度较大如图2。

Figure 2. Borer (left) and noctuid moth (right)
图2. 大螟(左)与线委夜蛾(右)
不仅是大螟与线委夜蛾相似度较大,根据数据集发现,螟类和蛾类的差别都不是很大,在数据质量不高的状况下,并且昆虫的特征受身体姿态等影响,会导致训练出模型的准确率极低的情况,为此,本文利用已有数据,根据科属与颜色以及身体特征最终粗分类出7类害虫。如表1所示。那么可以先对28种害虫进行一个粗分类,分出A~G类后在从分别确定种类,这样可以提高模型的准确率。

Table 1. Rough classification of 28 pests
表1. 28种害虫粗分类
2.2. 数据预处理
数据预处理技术路线图如下图3。
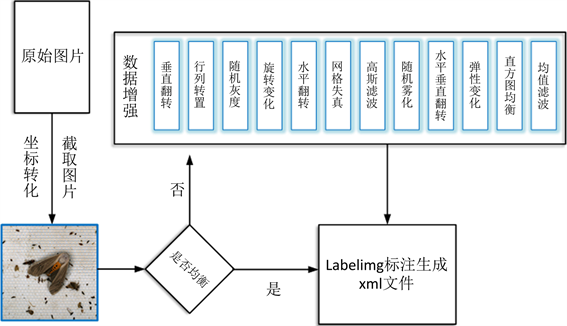
Figure 3. Data preprocessing technology roadmap
图3. 数据预处理技术路线图
由于图像中可用信息占原图比例太少,有太多的数据冗余以及噪声,因此本文根据所需特征对原图进行切割。如果直接按照害虫大小进行切割,则切割的出来的图片尺寸大小不一,虫子也会直接充斥在整个图像中,当使用YOLO-V5模型对图像进行训练时,则锚定框很难做出适应,导致模型的检测效果极差。因此本文以给定的中心点坐标为中心,重新设置计算切割框大小对图像切割,使得害虫图像尽可能在图像中心且不能占据图像过于大的面积,然后统一缩放到550 × 550像素,如图4所示。
2.2.1. 数据增强
数据增强是一种从现有的训练样本中生成新的训练样本的技术,是一种在数据约束环境下提高机器学习模型性能和准确性的低成本和有效的方法。增强方法包括:均值滤波、水平反转、水平垂直翻转、行列转置、随机灰度、随机旋转、网格失真、弹性变换、高斯滤波、自适应直方图均衡、随机雾化等 [4] 。
Mosaic数据增强方法是YOLOv4论文中提出来的,主要思想是将四张图片进行随机裁剪,再拼接到一张图上作为训练数据 [5] 。这样做的好处是丰富了图片的背景,并且四张图片拼接在一起变相地提高批
尺寸(batch_size),在进行批标准化(batch normalization)的时候也会计算四张图片,所以对本身batch_size不是很依赖。如图5所示。
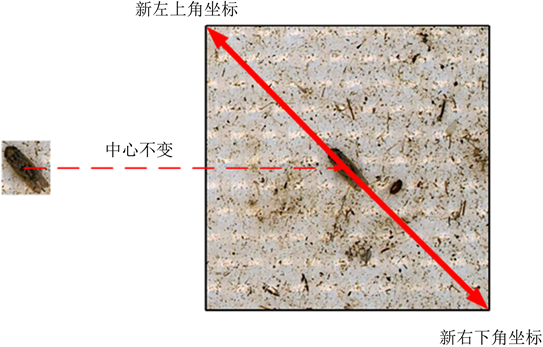
Figure 4. Diagram of coordinate transformation and cutting of brown planthopper
图4. 褐飞虱属坐标转化切割示意图

Figure 5. Mosaic data enhancement for training sets
图5. 训练集的Mosaic数据增强
2.2.2. 数据标记
当使用YOLO-V5进行检测时,需要传入数据在图中的坐标以及标签,所以需要对处理好的数据进行标注,Labelimg是一个图形图像注释工具,本文即采用该工具对数据进行标记 [6] 。由人工完成农业灯诱目标害虫坐标信息标注,以xml格式保存,xml文件中包含了改图中害虫的位置坐标、种类、图片路径等信息。
3. 灯诱害虫智能检测与识别模型
3.1. 基于YOLO-V5l模型的害虫粗分类检测
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升 [7] 。
根据YOLO-V5模型官方提供的模型在COCO数据集上的表现,YOLO-V5的预训练权重较好的有YOLO-V5x,YOLO-V5l,YOLO-V5m这3个权重文件。其中最好的是YOLO-V5x,但是该权重文件收敛速最慢,时间成本较高,所以我们选择相对较好的YOLO-V5l预训练权重文件进行迁移学习。
本文在昆虫相似度较高的情况下,提出的YOLO-V5l模型的粗分类检测,先对数据集的害虫利用YOLO-V5l模型根据表1所划分的A~G类七种作为标签,对害虫进行一次检测,以此来提高模型的精确度。
3.2. 基于ResNet50模型的害虫细分类识别
针对害虫种类之间的相似度较高,导致YOLO-V5检测的结果可能在同科属下分类错误的状况,本文提出在YOLO-V5检测结果基础上,对其进行二次分类,来确保模型的准确率。
ResNet残差神经网络的主要思想是在网络中增加了直连通道,即Highway Network的思想。此前的网络结构是性能输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出。 [8] ResNet残差神经网络的思想和Highway Network的思想也非常类似,允许原始输入信息直接传到后面的层中。ResNet网络结构如图6所示。
ResNet原始网络结构首先经过第一层卷积后进行池化层处理,池化层后先经过三层卷积,然后将经过三层卷积的神经元与直接经过卷积核为1 × 1,步长s = 1的卷积操作后的神经元进行叠加。然后传入下一层卷积层中,将经过三层卷积的神经元与下采样结果(经过卷积核为1 × 1,步长s = 2的卷积操作)进行叠加,之后继续传入卷积层,重复该卷积与下采样叠加操作。该下采样操作会使得输入特征图丢失部分信息。所以本文改进该下采样操作,将每层卷积层之间的下采样部分卷积操作修改为3 × 3,步长设置为s = 2。如图7所示。改进下采样的灯诱害虫特征提取,如图8所示。

Figure 7. Schematic diagram of down sampling improvement
图7. 下采样改进示意图

Figure 8. Feature extraction of lamp-induced pests
图8. 灯诱害虫特征提取
上文,YOLO-V5检测模型中将7类28种害虫进行检测,检测出的结果分为A~G七类,其中B、C、F三个种类与其他种类区分度较大,在上文划分时只有一个小类,因此害虫检测模型输出的结果不必再进行识别分类过程。但A、D、E、G仅是一个粗分类结果,并不能确定到最终的种类上,因此本文搭建了ResNet50识别模型用于确定最终的种类,流程总结如下图9。
3.3. YOLO-V5l与ResNet50结合的害虫检测与识别模型
在上文基于YOLO-V5的害虫检测模型与改进下采样的ResNet50害虫识别模型的基础下,将检测模型与识别模型相结合,提出基于检测—识别的虫情分析模型。一层检测对灯诱害虫图像进行检测,得出粗分类结果;再代入二层识别模型,得出最终的害虫类别,如图10所示。并对其进行数据统计。

Figure 10. Pest detection and identification model process based on the combination of YOLO-V5l and ResNet50
图10. YOLO-V5l与ResNet50结合的害虫检测与识别模型流程
3.4 模型预测增强算法
由于害虫的识别受身体姿态、重叠状况、形状、鳞片特征等影响较大 [9] 。不同的待识别图片传入细分类害虫识别模型中可能影响较大,可能做某些图像操作例如:随机旋转、均值滤波、水平反转、水平垂直翻转等操作后,再次传入细分类模型会得出不同的分类结果,导致模型预测结果的错误。因此本文提出对待训练图片进行数据增强后,再带入细分类害虫识别模型中,对数据增强检测结果与原始图片的检测结果进行加权计算如式(1)。得出最种预测结果,流程如下图11所示。
(1)
表示最终预测种类,
表示权重因子,
表示每种数据增强与原图所检测的结果,最终取
最多的结果作为最终检测种类。
4. 评价指标
判断一个算法、模型是否优秀需要一个评判标准,常用的评价指标有以下几种:准确率(Accuracy),精准率(Precision),召回率(Recall)等 [10] 。
准确率是指正确分类的样本量占总样本量的比例,其计算公式如下式(2):
(2)
召回率是指实际正样本在预测正样本中所占的比例,反映了分类器发现全部正样本的能力,其计算公式如下式(3):
(3)
式中:TP表示正例分类正确的数量;TN表示负例分类正确的数量;FP表示正例分类错误的数量;FN表示负例分类错误的数量。
本模型的精确率如图12(左)与召回率如图12(右)在训练过程中的变化可以从Tensorboard中显示出来,横坐标为Epoch次数,纵坐标为精确率与召回率在不同迭代次数时的精度,图中浅色的线表示真实的数据图,而深色的线表示平滑之后的数据图。
本模型在精确率与召回率上有着较好的表现。但在目标检测中,单纯使用精确率与召回率在目标检测中并不足以体现模型的性能。AP是不同Recall下Precision的均值,也就是对应PR曲线的面积。对于一个PR曲线来说,每一个阈值对应着一个P和R。当阈值从0到1走过,绘制出每个阈值对应的P和R值,得到的就是PR曲线 [11] 。而m则代表各类别的平均。mAP值(Mean Average Precision),即平均AP值。
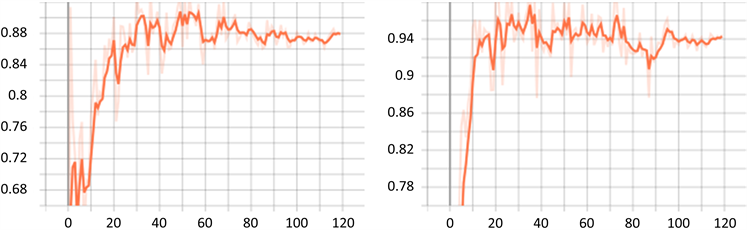
Figure 12. Accuracy (left) and recall (right)
图12. 精确率(左)与召回率(右)
(4)
其中
表示全部种类,q表示每个种类,
表示每个种类的AP值。
mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5:即将IoU设为0.5时,计算每一类的所有图片的AP,然后所有类别求平均,即mAP。本害虫检测模型的mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5如下图13(左)所示。mAP@.5:.95 (mAP@[.5:.95]):表示在不同IoU阈值(从0.5到0.95,步长0.05) (0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。如图13(右)所示,图中浅色的线表示真实的数据图,而深色的线表示平滑之后的数据图。mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5指标与mAP@.5:.95指标分别最终达到了0.9491与0.7043,具有较好的结果。
5. 实验环境与训练参数
本项目在内存为64 G,CPU为i9-9900KF,GPU为NVIDIA GeForce RTX 2080的设备上进行模型的训练,使用Keras 2.3.1,Opencv-python 4.4.4.64,Pytorch 1.11.0,Python 3.7.12的训练环境,训练参数Batch Size为16,Epoch (YOLO-V5l)为120,Epoch (ResNet50)为50,Image Size为(500, 500),IOU为0.5。
6. 结果分析
基于上文的害虫检测模型,将虫情采集图像上传至模型中,检测图像中的害虫类别与数量,结果如下图14,有部分害虫漏检,这张图像的漏检率为6.97%,其中可以看到有部分的透明残翅,与一些较小的残叶与树枝被误检为虱类害虫,原因可能是因为虱类害虫在图中占比太小,导致识别不佳,准确率为88.4%。
对其所有预测结果求其平均误检率与平均漏检率结果如下表2。
对于平均精确率,主要由于许多残肢与残叶等细小噪声,容易被误判为虱属,导致结果的平均精确率并不完美,平均漏检率主要是由于一些肢体的重叠和遮挡,导致会出现漏检,其中八点灰灯蛾,由于背部和腹部颜色差异极大,一定程度上的导致了它的漏检率较高。
对于B类(八点灰灯蛾)、C类(黄毒蛾)、F类(大黑鳃金龟)这种不需要进行二次识别的类别,直接使用一层检测模型的mAP@.5:.95。结果如表3。
其中八点灰灯蛾与黄毒蛾的检测效果较好。但是大黑鳃金龟由于与石蛾相似度较高,它们之间存在互相误检,导致mAP值较低。
7. 总结
本文介绍了当前我国的农田害虫现状,利用深度学习技术对使用灯诱害虫装置获取的数据进行虫情分析,可以解决人工统计虫情信息耗时耗力的缺点。灯诱害虫图片数据中,灯诱害虫种类繁多,虫体姿态多样,噪声较大,害虫间的肢体重叠,对于模型的准确性造成了较大的影响。本文从以下几个方面逐步建立虫情分析模型。
数据探索与预处理方面:针对昆虫同科属下相似度较大的情况,提出了数据粗分类,用以提高检测模型时的准确率。针对数据不均衡的情况,使用12种数据增强方式,对数据进行扩充,使数据均衡化。
一层检测模型方面:使用YOLO-V5l模型,将粗分类的数据带入检测模型中,减少由于28分类的分类数量过多,以及类间相似度较大对模型的影响,提高模型的准确率。
二层识别模型方面:将YOLO-V5l检测模型粗分类的结果带入二层识别模型中去做细分类,并提出了一种加权的预测增强算法,以提高模型准确率。
在传统的农业中,往往虫害已经发展开来时才会出现明显特征并实施治理,这样不仅防治过程中产生的成本高,而且由于之前的环保意识不那么强,在害虫的防治上大量用药,导致农业环境污染严重和农业产品的不完全安全。而如今,人们对农业虫害上有了更科学更持续更深入的认知,在农业虫害上更注重预防害虫,这不仅效果好了,防治过程中的成本少了,对农业的环境也更科学与友好了。
虫情测报灯便是科学农业的产物,而本文则是利用虫情测报灯收集的图像数据,进一步智能快捷的将虫情分析出结果。因此,关于当前农业的发展,我们要用更发展、更智能、更科学、更环保的眼光来进行思考,不仅要让科技走向越来越智能,也让农业也跟上科学、智能和环保的脚步。
基于YOLO-V5l与ResNet50的农田害虫检测模型在农业灯诱相似害虫检测与识别方法取得了较好的识别精度,为相似害虫识别提供了技术参考。但农业灯诱相似害虫识别精度仍有提升的空间,下一步需要改进与完善的地方包括:
1) 对于残肢、残翅、碎叶等的影响需要降低。
2) 对于害虫肢体重叠的情况还需进一步加强攻克。
3) 对于粗分类时的分类情况,还需进一步定义一个确定的方法。
4) 对于昆虫形态、以及同类昆虫不同生长时期的识别还需进一步加强。
5) 对于数据采集装置,需要避免对昆虫造成较大的伤害,减少残肢的出现。