1. 引言
随着分布式技术的发展,当前大数据计算处理服务都在云环境上实现。云计算平台可以将大量数据计算任务通过网络分发到多个计算实例中进行处理,最终将各个实例的运算结果汇总返回给用户。云计算通过调用庞大的运算资源更高效地解决以往单机难以处理的复杂计算任务,因此,平台中负载分布是否均衡是评估云计算平台是否可靠可用可扩展的关键。在云计算环境中,负载均衡通过算法动态地对运算资源进行调度,以最大限度地提高集群总体性能 [1],在有限时间内处理更多请求,提高资源的利用率。在云环境下,任务处理单元通过虚拟机技术或容器技术部署在服务器实例上,处理资源是虚拟资源,部署配置可以根据云环境的实时负载情况进行动态调整。因此,云环境下负载均衡可以简单概括为以下两个目标:
1) 对大量的用户请求进行合理分发,减少用户等待响应时间;
2) 将过载服务器上的任务分割转移到其他节点进行处理,提高资源利用率。
当前云环境下负载均衡算法依据触发方式可以分为主动式、被动式以及对称式 [2]。主动式负载均衡根据设定的负载均衡策略定时执行,如轮转调度、加权轮转调度。被动式负载均衡通过对服务器负载性能数据实时采集,判断系统当前均衡性,依据设定的指标阈值进行负载均衡。对称式则是主动式与被动式算法的结合。
通过判断系统当前负载状态是否动态调整,负载均衡也可分为静态负载均衡策略与动态负载均衡策略 [3]。静态负载均衡算法包括随机、轮询 [4]、加权调度 [5]、优先权 [6] 等,动态负载均衡算法包括最少连接数、最快响应速度、负载最轻综合均衡、观察法、预测法 [7]、动态性能分配 [8]、动态服务器补充、服务质量 [9]、服务类型 [10]、规则模式 [11] 等。常见的负载均衡算法及其彼此之间的对比分析如表1所示。
从表1可以看出,静态负载均衡算法相对动态负载均衡算法更简单,但是无法将计算资源最大化利用,造成资源浪费。动态负载均衡算法由于需要考虑的参数指标较多,因此更复杂 [12],且需要对服务器各种指标进行实时监控并分析,对资源进行动态调度,因此动态负载均衡也能更高效合理地运用计算资源,节省能源浪费。许多研究人员对云环境下动态负载均衡算法做出改进,以应对不同云计算环境,提高云平台总体性能,保障云平台的服务质量(QoS)。Pan等 [13] 提出一种最优负载均衡算法,在不牺牲系统性能的情况下对虚拟机进行资源调度,并取得了良好的效果。Said等人 [14] 提出一种基于Moth-Flame优化算法的任务调度方法,用于雾计算中节点最优任务集分配,以满足信息物理系统应用程序服务质量要求。Kansal等 [15] 人总结了云计算中负载均衡算法,详细介绍了Active Clustering、Decentralized content aware等17个算法并进行了对比分析 [16]。
随着人工智能技术(AI)的发展,结合AI的负载均衡算法研究取得了较大进步。Wang等 [17] 人提出一种基于Q-learning的移动性管理方法来处理系统信息的不确定性。为减少服务等待时间,该方法通过反复试验从环境中学习最佳移动性管理策略。Smith等人 [18] 使用基于先到先服务(FCFS)和保守回填的最少工作优先(LWF)队列来提前预留资源以进行负载均衡。谢海涛等人 [19] 基于长短时记忆网络(LSTM)对不同时间跨度中的知识进行融合,实施对用户流量进行预测并实现负载均衡,从而降低用户平均请求时间。张思松 [20] 设计了一种基于深度强化学习算法的高能效数据负载均衡方法,根据存储节点数据量与特征动态实现高能效数据负载均衡。胡华等人 [21] 将强化学习模型Q-learning用在移动社交网络领域中的群智感知任务调度上中。强化学习分步探索做全局优化,微观上NTQL-ASS贪婪算法获取局部最优,综合全局和局部优化策略的负载均衡算法提高了感知效率并节省了能源开销。

Table 1. Comparison of common load balancing algorithms
表1. 常见负载均衡算法对比
总之,当前云环境下负载均衡算法还没有形成统一的规范,某些研究尝试从某个角度切入对负载均衡问题开展研究,但总体来说仍然有所欠缺,主要体现在以下几点。
1) 不同云环境下实例或节点不同,例如系统、配置、网络带宽与任务需求存在很大差异,并且随着时间的变化而变化。
2) 云环境下负载均衡的细粒度实时性要求高。尽管当前算法对资源状态进行了实时评估,但仍无法对实时变化的请求进行预测,常常需要进行二次调度或多次调度,造成资源浪费。
针对以上问题,结合长短时记忆网络与强化学习技术,提出云环境下基于AI知识分析的负载均衡方法LSTM-TD3 (Long Short Term Memory and Twin Delayed Deep Deterministic policy gradient algorithm)。LSTM-TD3以资源利用率、服务器连接数、响应时间、请求历史数据等为知识参数输入,首先进行任务数预测建模;以预测数据初始化强化学习模型TD3,形成AI分析与评估优化负载均衡计算模型;通过算法训练以及仿真实验对LSTM-TD3的负载均衡效果进行实际验证。实验结果表明,相比传统的云环境负载均衡方法,LSTM-TD3对比无负载均衡、轮询算法、Q-learning和TD3算法分别提高了25.4%,6.41%,3.56%和2.85%,能达到更好的资源负载平衡效果,资源利用率更高。
2. 基于AI知识分析的负载均衡方法
2.1. 模型框架
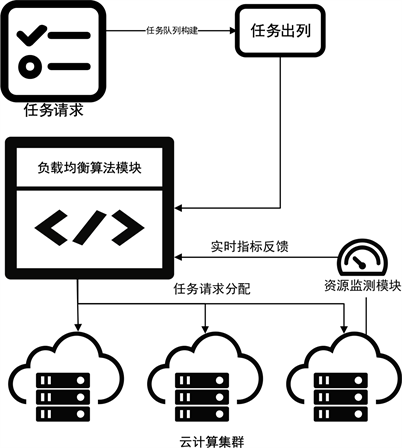
Figure 1. Load balancing framework for cloud computing resource requests
图1. 云计算任务请求资源负载均衡框架
本文所提出的云计算资源负载均衡框架如图1所示,其核心为基于AI知识分析的负载均衡器。监控单元实时采集的实例单元信息以及部署在实例上的容器信息,结合历史知识汇总到负载均衡器中进行动态分析,最终根据分析模型计算的结果分配计算资源。当前大多数负载均衡算法都考虑了时间、成本、能耗、连接数等指标,但是较少会结合对历史数据的知识进行融合分析。本文在常用指标上创新性地结合历史任务数进行AI知识分析建模,通过学习不同时间段的任务量,预测下一个时间段的任务量,提前做出预测,并及时启用备用实例资源,应对可能的请求高峰,以提高云平台服务质量。
2.2. 问题定义
对云环境下的负载均衡问题进行抽象,其本质实则为多目标优化问题,数学模型定义如下。
1) 任务集合定义为
,其中
代表第i个子任务t,n为任务数;
2) 本文通过容器对服务进行部署,容器集合定义为
,其中
中j代表容器的序号,且
;
3) 集合
定义任务的分配情况,若
,则表示任务
被分配到容器
进行处理,若
,为其他;
4) 每个容器需要多种不同类型的资源为任务提供服务,以cpu、内存以及网络宽带作为指标建立资源利用率模型
。其中,cpu表示CPU利用率,mem表示内存利用率,net表示网络带宽使用率。资源利用率可以比较准确的反应负载变化的趋势,当资源利用率
较大时候,当前实例负载较大,反之较小。通过负载均衡指标探测模块可以对相关指标数据实时获取。负载均衡指标计算如公式(1)所示;
(1)
5) 资源需求评分
(公式2所示),资源需求评分
如公式(3)所示,用来衡量实例的负载均衡程度,实现迁移容器时目标的优选;
(2)
(3)
6) 结合资源需求评分
和资源负载均衡度
,最终状态价值评价函数定义如公式(4)所示,
(4)
其中,
为达到当前状态S所采取的负载均衡策略,
。
2.3. LSTM-TD3算法模型
随着AI技术的发展和应用,长短时记忆网络被广泛应用于文本分类、机器翻译、语音识别等时序问题。相较于传统回归算法,它引入类似“记忆”的概念,用于处理和“记忆”有关的各种任务。本文引入LSTM [22] 对历史任务数据进行时序建模,用于预测当前状态的下一个状态可能出现的任务量。由于预测任务量时,特殊时间节点以及短时间范围内任务数量的正向反馈远高于其他时间段,所以可以较大地提高预测准确度。此外,由于强化学习通过与环境交互获得正向或反向奖励的方式求解最优策略,已被广泛应用到机器人、自动驾驶等领域。强化学习模型如图2所示,通过与环境不断段交互试错的方式来进行学习,实现大规模需求条件下的云平台资源调度。
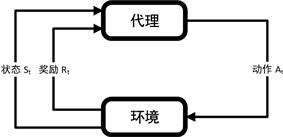
Figure 2. Interaction between agent and environment in reinforcement learning
图2. 强化学习中代理与环境的交互过程
几乎所有的强化学习过程都可以用马尔可夫决策过程来进行描述。本文使用一个五元组
来对此过程进行表示。其中,S代表环境状态的集合,即当前云环境下各个实例,各个容器负载程度集合,用负载均衡指标
进行描述;A表示代理所能采取的动作集合,即负载均衡器所进行的调度操作;P表示状态转移概率,如:
,即负载均衡器在状态s下采取调度操作a后变为状态
的概率;R是奖励函数,即状态s下采取操作a时能获得的奖励;y为衰减因子,取值为[0, 1],用于调整不同训练回合的奖励权重。强化学习中还有一个重要的概念是策略
,即云环境下不同的负载均衡执行操作的依据。如,负载均衡器在t时刻的
状态下,根据策略
执行动作
,接下来环境(各个实例中不同服务的指标
、
、
变化)通过状态转移概率概率P和奖励函数R得到新的状态
和奖励
。状态s下的策略选取如公式(5)。
(5)
通过寻找最优价值函数
来寻找最优策略,
表示在策略
下的价值函数。相关计算如公式(6)所示。
(6)
TD3即Twin Delayed Deep Deterministic policy gradient algorithm [23] 的简称,双延迟深度确定性策略梯度。TD3相对DDPG (Deep Deterministic Policy Gradient)具有以下优势:1) 用类似双Q网络的方式,解决了DDPG中Critic对高估动作Q值的问题;2) 延迟actor更新,让actor的训练更加稳定;3) 在target_actor中加上噪音,增加算法稳定性。由于采取了经验回放(Experience Replay)机制,TD3能将训练过程中学习到的经验数据存储在经验池中,并且通过随机抽样的方式更新网络参数,不仅加速模型的学习,还提高了强化学习网络的稳定性 [23]。

Figure 3. TD3 algorithm structure framework
图3. TD3算法结构框架
TD3算法结构如图3所示,Actor与Critic分别称为演员网络与评论家网络,Actor根据策略,结合当前状态
,输出动作
,Actor目标网络用作对未来可能的动作
进行模拟,输出目标动作
。Critic网络与Critic目标网络则分别对Actor网络和Actor目标网络的动作进行评判,计算出
,以及目标动作
下目标Q值
。图中
、
、
和
分别代表Actor网络、Critic网络、Actor目标网络和Critic目标网络的参数。Critic网络每一回合都会进行更新,并采取最小Q值策略,即选取Critic目标网络中最小的Q值作为目标值
,即公式(7)所示。
(7)
其中,
为随机噪声,服从截断正态分布
。Actor网络和四个目标网络参数根据公式(8)进行更新。
(8)
3. 基于LSTM-TD3知识分析的负载均衡模型
云环境中,排除特殊情况,每天不同时间段、每年不同时期的任务数量波动的具备一定的规律性 [24]。通过融合历史任务数作为知识,经过LSTM进行经验学习对参数进行初始化,作为Actor、Critic模型的参数输入,构建基于TD3的AI知识分析进行负载均衡模型,模型如图4所示。
算法设计
LSTM-TD3算法伪代码展开如算法1和算法2所示:
算法1:LSTM预测网络
1) 输入历史任务量数据
,作为LSTM的输入。
2) 设置LSTM网络相关参数:input_size = 10、hidden_size = 20、num_layers = 2、bias = 0、dropout = 0.4。
3) 将当前时刻神经网络的输入和下一时刻输入作交叉熵构建损失函数,交叉熵公式如(9),p为真实概率分布,q为预测概率分布:
(9)
4) 按照步骤2循环更新,直至迭代完成,loss值完成收敛。
5) 输出LSTM网络模型参数,用作TD3模型初始化。
算法2:强化学习TD3
1) 初始化Critic网络
、
以及Actor网络
参数
、
、
。
2) 使用算法1中的LSTM网络输出的预测任务数,组成预测状态
,初始化Actor和Critic目标网络参数
、
、
。
3) 初始化经验池M。
4) 对每个episode循环执行以下步骤:
a) 获取云环境下的初始状态
,由每个实例不同容器的资源负载度组成。
b) 初始化每一个episode中的临时经验池
。
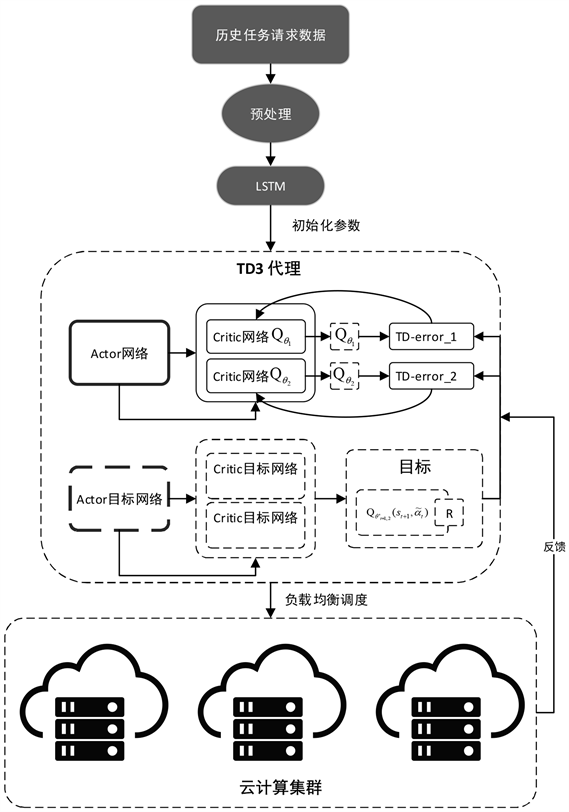
Figure 4. LSTM-TD3 model structure
图4. 本文LSTM-TD3模型结构
c) 若
没有超过系统承载阈值(设定90%的实例资源综合评价指标
,则集群暂停处理请求)并且系统任务转移时间小于限定值,循环执行以下步骤:
i) 于状态
下,选择带有噪声的动作
:
,
。
ii) 根据策略执行动作
,得到环境反馈的奖励
和新状态
。
iii) 将
存入临时经验池
。
iv) 从经验池M进行随机采样,用于Actor,Critic目标网络训练。
v) 重新计算在经验池的随机样本TD误差,更新Sum Tree节点优先级。
vi) 每i步,使用确定性策略梯度更新Actor网络参数
。
vii) 结束step循环。
viii) 若
,则
存入经验池,k为负载均衡评价标准的阈值。
5) 结束episode循环。
4. 实验结果与分析
实验环境与参数设置
本实验环境配置如表2所示。负载均衡实验使用CloudSim4.0进行云平台模拟,实验用计算机节点总数设置为50,具体配置如表3所示。共分为五组节点,其中N11-N30为2个处理单元,但是组内节点执行效率有差别,N31-N50采取同样的配置方式,目的是增加云环境的多样性,增加负载均衡的复杂度。
Table 2. Experimental environment configuration
表2. 实验配置
Table 3. Parameter settings of nodes
表3. 节点参数设置
本文分别在50、100、200和400个任务下进行负载测试实验。取该仿真环境中不同任务下的50次历史实验数据用作LSTM-TD3算法历史数据,对Q-learning、TD3、LSTM-TD3展开训练,根据不同任务,分别训练250个回合。其中,在400个任务的情况下,Q-learning、TD3、LSTM-TD3算法随着迭代回合数的增加,奖励值的收敛结果实验如图5所示。
从图5中可以看出,LSTM-TD3的奖励值在50个回合内,相较于TD3、Q-learning能获得较为稳步上升的奖励,表明基于LSTM预测数据进行初始化的Actor不会出现过大的Q值偏移,因而奖励值也不需要产生过大的波动。同时从50回合到100回合区间内,LSTM-TD3与Q-learning均能较快地到达奖励稳定值(−250)左右,TD3则是在100回合左右突然奖励值达到该稳定值,表明在本实验环境下,三个强化学习模型均能在100回合以内学习完毕。随着回合数的不断增加,能看出TD3与Q-learning的奖励值变化会出现突然的降低情况,证明TD3与Q-learning相比LSTM-TD3,由于缺乏对任务数的预测,缺乏历史知识的分析,对某些环境突变的因素没能做出很好的预测,因此模型相对来说不够稳定。整体上看,在当前实验环境下的负载均衡任务下,传统的Q-learning算法与TD3算法最后都能达到较好的效果,相较于LSTM-TD3,传统的Q-learning与TD3奖励的收敛速度较慢,缺乏历史知识分析也导致了模型的学习速度相对来说较慢,当面临更多任务的时候可能会出现难以收敛的情况。因此,以上实验能够表明,结合LSTM的TD3网络LSTM-TD3能更好地进行负载均衡。
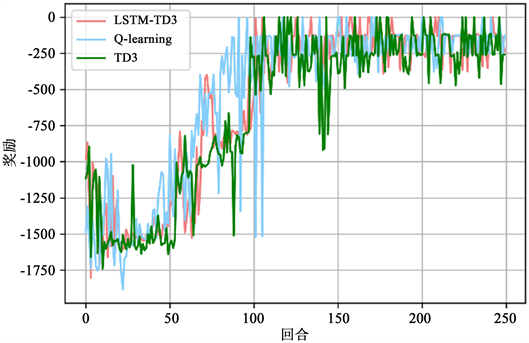
Figure 5. Reward changes over turn for different algorithms (400 missions)
图5. 不同算法下奖励随着回合的变化(400个任务)

Figure 6. Time required by different load balancing policies for different tasks
图6. 不同任务数下不同负载均衡策略完成任务所需时间
本文对50、100、200和400个任务下的负载测试实验分别消耗的时间进行展示并分析,结果如图6所示。在任务数为50个时,无负载、轮询算法、Q-learning、TD3、LSTM-TD3算法分别消耗的时间为602 ms、529 ms、520 ms、541 ms、以及530 ms。各个算法下完成任务消耗时间接近,表明在此环境下基于强化学习的负载均衡算法并没有提供比传统轮询算法更好的负载效果。但由于任务数的增加,传统轮询算法属于静态算法,无法对环境的变化做到动态的负载。因此,在400个任务下传统的算法完成任务需要的时间比基于强化学习算法完成任务需要的时间多得多,例如轮询算法在400个任务下所需时间为13,901 ms,LSTM-TD3为12,473 ms,两者相差1428 ms。
以上结果可以看出,使用训练好的强化学习模型进行负载均衡,相比无负载均衡算法以及静态负载均衡算法更能有效对资源进行调度,达到资源利用均衡的状态。LSTM-TD3相比传统轮询方法、Q-learning [25]、TD3平均完成任务时间提高百分比如表4所示。
由表4可以看出,LSTM-TD3相比其他算法能更有效地进行负载均衡。与传统的云环境负载均衡方法对比,在本文的实验环境下,LSTM-TD3相比无负载均衡、轮询算法、Q-learning和TD3算法平均分别提高了25.4%,6.41%,3.56%和2.85%,能达到更好的平衡效果,资源利用率更高。
5. 结语
针对云计算环境下传统负载均衡方法难以对蕴含在历史数据中的流量信息进行知识分析与智能利用问题,对蕴含在云平台历史运行过程中的流量信息进行知识分析,用于预测云计算环境下新到任务的请求量,并提出一种基于AI知识分析的负载均衡方法LSTM-TD3。LSTM-TD3结合LSTM用于预测模型训练进而对TD3进行初始化,以资源利用率、服务器连接数、响应时间、请求历史数据等为知识参数输入,进行任务数预测建模,紧接着以预测数据初始化强化学习模型TD3,形成AI分析与评估优化负载均衡计算模型,并通过算法训练和仿真实验对模型和负载均衡结果进行实际验证。在CloudSim4.0进行云平台模拟,对比了Q-learning、TD3、LSTM-TD3模型奖励值的收敛结果,以及传统负载均衡算法与强化学习负载均衡算法完成任务所消耗的时间。实验结果表明,相比传统的云环境负载均衡方法,LSTM-TD3对比无负载均衡、轮询算法、Q-learning和TD3算法分别提高了25.4%,6.41%,3.56%和2.85%,能达到更好的资源负载均衡效果,资源利用率更高。
NOTES
*通讯作者Email: qiuyang@bingosoft.net