1. 引言
随着科学技术的不断发展,通过卫星得到的遥感图像的空间分辨率不断提高,而利用高分辨率的遥感图像可以帮助地物覆盖制图工作取得更好的效果,从而清楚地了解土地及其生态环境以做出更准确的城乡规划决策。遥感图像的地物覆盖语义分割作为一个对于生产生活具有重要意义的研究课题,近年来在算法层面开展了许多相关的研究工作,像Long等人首先提出了全卷积神经网络(Fully Convolutional Networks, FCN) [1],通过端到端的训练实现了像素到像素的语义分割;剑桥大学团队提出了SegNet网络 [2],采用编码和上采样加反卷积的解码结构,使网络不仅保留了图像的边缘信息还减小了计算量;Noh等人提出了DeconvNet网络 [3],采用了编码和反卷积加反池化的解码结构,通过集成深度反卷积网络和提案式预测,缓解了FCN网络的局限性;Ronneberger等人设计了一个对称的U型网络——UNet [4],同样采用编码–解码结构,并在特征间进行有效的信息融合,使得网络能够在较少的训练图像下产生精确的分割结果;Zhou等人提出了UNet++网络 [5],采用深度监督的编码–解码结构,通过一系列嵌套的密集跳跃连接减小了低层特征和高层特征之间的语义间隙,实现了比UNet更精准的语义分割结果。可以看到,目前一些主流的语义分割算法采用的都是编码–解码结构,其特点是在编码器中将高分辨率到低分辨率的卷积串联起来,逐步减小特征图的大小;而在解码器中,利用上采样、反卷积等操作,将特征恢复到高分辨率。而最近由Wang等人提出的HRNet [6] 则是从一个高分辨率卷积流开始,逐步添加低分辨率的卷积流,并将多个分辨率卷积流并联起来,通过在整个训练过程中保持高分辨率表示,避免从低分辨率复原到高分辨率时带来的空间误差。
在早期的遥感图像语义分割研究中主要依赖于中、低分辨率的数据集,像MCD12Q1 [7]、LandCoverNet [8]、GlobeLand30 [9] 等,在这些数据集上的工作主要侧重于宏观上的制图分析。随着遥感技术的进步,能够获取到的高分辨率的数据集越来越多,像ISPRS Potsdam [10]、ISPRS Vaihingen [10]、ZurichSummer [11] 和Zeebruges [12] 等,利用这些数据集可以实现更为精准的地物覆盖语义分割。然而,这些数据集的数量较少,且覆盖范围有限。而最近由武汉大学构建的LoveDA数据集 [13] 不仅包含了5987张高分辨率图像,并且还覆盖了乡村和城市两种场景,在乡村场景中有很多像森林、河流等自然结构,而在城市场景中以建筑、道路等人造结构为主,在这种具有丰富场景的数据集中开展相关工作具有重要的实际意义。与此同时,丰富的场景还带来了像素分布不均衡的问题。对此,我们提出了基于注意力的HRNet (Attention-based HRNet, AbHRNet)结构:首先,我们在主干网络中引入了卷积注意力模块 [14] (Convolutional Block Attention Module, CBAM)帮助模型关注数量较少的类别的特征,并减小由复杂的背景信息带来的干扰;与此同时,我们还在基准网络交叉熵损失的基础上引入了二元交叉熵损失和Dice Loss [15] 以实现对背景样本的有效监督,并解决目标和背景、目标和目标之间由于面积差距过大带来的难以优化的问题。我们的工作都是基于CodaLab Competitions中的LoveDA Semantic Segmentation Challenge开展的,在相关的网站提交了我们的结果后,最终的测试得分是由官方平台计算得出的。
2. 网络模型结构
2.1. AbHRNet的总体结构
如图1所示为我们提出的AbHRNet的总体结构,包括主干网络和语义分割输出表示网络。
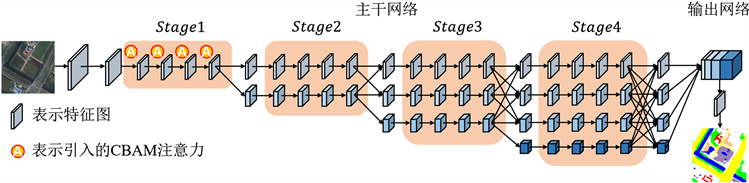
Figure 1. Overall structure of AbHRNet
图1. AbHRNet的总体结构
在主干网络中,首先将图像通过2个步长为2的3 × 3卷积,得到分辨率为原图1/4的特征,然后将特征送入由多个分辨率卷积流形成的特征提取模块。该模块从一个高分辨率卷积流开始作为第一阶段,然后逐步添加由高分辨率到低分辨率的卷积流形成新的阶段,最终将I个分辨率的卷积流并联起来。
用于表示相关卷积流的特征,其中s表示第s个阶段,r (
)既表示第r个卷积流又表示分辨率的索引,第1个卷积流的分辨率索引为1,则第r个卷积流的分辨率为第1个卷积流分辨率的
,具体的特征表示请见图2。
而在主干网络多个分辨率卷积流之间还利用了特征融合操作来反复交换信息。其中,低分辨率特征具有较强的语义信息表征能力,而高分辨率特征则具备较强的空间信息表征能力,因此在融合之后,增强了高分辨率特征的语义表示,同时还在高分辨率特征中保持了精准的空间信息。具体实现过程如图3所示,我们以融合3个分辨率的特征表示为例。输入包括3个特征:
,输出特征
为三个输入特征转换后的特征之和,计算公式如下式所示:
(1)
其中,
代表独立于输入分辨率索引x和输出分辨率索引r的转换函数。当
时,
;当
时,
代表
个步长为2的3 × 3卷积;当
时,
则代表
倍的双线性插值上采样操作,并通过1 × 1的卷积以保持通道数的一致。

Figure 2. Backbone network structure sketch
图2. 主干网络结构简图

Figure 3. Multi-resolution feature fusion
图3. 多分辨率的特征融合
而在通过主干网络后将得到的多个分辨率卷积流的输出特征送入语义分割输出表示网络。首先是通过双线性插值上采样操作将多个分辨率的特征缩放到同一尺寸下,保持通道数不变,并沿着通道维度将输出特征拼接起来,最终将拼接后的特征通过1 × 1的卷积把通道数转变为要分割的类别数,再通过双线性插值上采样放大到与原图同样大小后作为最终的语义分割输出结果表示。
2.2. 基于卷积注意力的增强特征提取模块
由于在遥感图像中,不仅包括我们感兴趣的地物类别,还包括复杂的背景样本,而为了让模型能够更加关注到我们感兴趣的目标特征信息,并减小由复杂的背景信息带来的干扰,我们在HRNet中引入了卷积注意力模块(Convolutional Block Attention Module, CBAM)。在基准HRNet网络中,Stage1的基本组件为BottleNeck模块,Stage2、Stage3和Stage4的基本组件为BasicBlock模块,我们在Stage1的BottleNeck模块中引入了CBAM注意力,构建了CBAM-BottleNeck模块,并把它作为AbHRNet中Stage1的基本组件,具体的实现过程如图4所示。首先在通过1 × 1卷积、3 × 3卷积和1 × 1卷积后,将得到的特征F依次通过通道注意力(Channel Attention, CA)模块以及空间注意力(Spatial Attention, SA)模块。在通道注意力模块中,对特征F分别进行全局最大池化(Global Maximum Pooling, GMP)操作和全局平均池化(Global Average pooling, GAP)操作,得到聚合了遥感图像空间信息的最大池化特征和平均池化特征。而在将它们通过具有隐藏层的多层感知机(Multi-Layer Perceptron, MLP)共享网络后,利用逐元素求和来融合输出特征向量,从而得到通道注意力特征图
:
(2)
其中,
表示Sigmoid函数。而后将特征F与通道注意力特征图
进行逐元素相乘,得到特征
:
(3)
其中,
表示逐元素相乘操作。
在空间注意力模块中,则是对特征
沿着通道维度分别进行GMP操作和GAP操作,而后将得到的最大池化特征和平均池化特征进行拼接以得到有效突出信息区域的特征,再通过标准卷积层后输出空间注意力特征图
:
(4)
其中,
表示滤波器大小为7 × 7的卷积操作,
表示特征的拼接操作。而后将特征
与通道注意力特征图
进行逐元素相乘,得到特征
:
(5)
将得到的特征
与输入特征F进行逐元素求和,并通过Relu激活函数后得到输出特征。
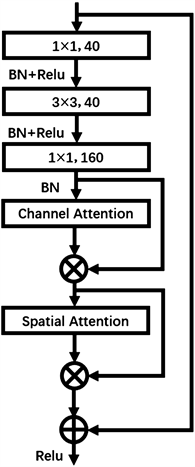
Figure 4. CBAM-BottleNeck module
图4. CBAM-BottleNeck模块
2.3. 损失函数
在本文的任务中,除了目标类别以外的地物均归为背景类别,而背景样本数量巨大且形态复杂,使得在该任务中出现了很多目标样本被误分类为背景样本的情况。而为了实现对背景样本的有效监督,我们在基准网络只有交叉熵损失(Cross Entropy Loss, CE Loss)的基础上引入了二元交叉熵损失(Binary Cross Entropy Loss, BCE Loss)和Dice Loss。其中,BCE Loss用于对背景样本的有效监督;而Dice Loss [15] 起先是用来计算两个样本之间相似性的度量函数,而现在则是在各种语义分割任务中得到了广泛的使用。通过将Dice Loss与交叉熵损失结合在一起,具有以下的优势:1) Dice Loss和交叉熵损失分别从图像的整体层面和像素层面对网络进行优化;2) 当图像中背景样本和目标样本之间的面积差距过大时,交叉熵损失无法对小面积的目标样本进行优化,而Dice Loss则可以帮助各种大小的样本进行优化;3) Dice Loss可以帮助模型更加关注前景区域的学习。最终,通过将损失之间的优势进行互补,实现有效地性能提升,总损失计算如下:
(6)
其中,
和
分别表示BCE Loss和Dice Loss的权重系数。
3. 实验及结果分析
3.1. 数据集
我们选择LoveDA数据集进行实验验证。LoveDA数据集是武汉大学测绘与遥感信息工程国家重点实验室于2016年7月在南京、常州和武汉等地通过谷歌地球平台收集的0.3米空间分辨率的遥感图像数据集,总面积为536.15 km2。该数据集总共包含5987张高分辨率遥感图像,以及166768个标注对象,图像的尺寸为1024 × 1024,并将其划分为7个类别:背景(RGB: 255, 255, 255)、建筑(RGB: 255, 0, 0)、道路(RGB: 255, 255, 0)、水体(RGB: 0, 0, 255)、荒地(RGB: 159, 129, 183)、森林(RGB: 0, 255, 0)、农田(RGB: 255, 0, 255)。图5展示了在LoveDA数据集中各个类别的像素数量,可以看到背景占据的像素数量最多,而荒地占据的像素数量最少,总体呈现不均衡的分布。LoveDA数据集中是从上述3个城市内9个农村场景和9个城市场景中收集的数据,训练集选择了4个农村场景和4个城市场景共8个场景的数据,剩余的数据作为验证集和测试集。
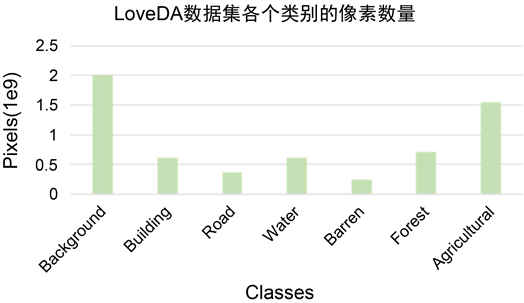
Figure 5. Number pixels of each category in the LoveDA dataset
图5. 在LoveDA数据集中各个类别的像素数量
3.2. 实验设置和评估指标
本实验基于Pytorch深度学习框架,GPU使用了NVIDIA GeForce GTX 2080Ti显卡。在训练期间,初始学习率设置为0.1,并使用动量为0.9、权重衰减为10−4的随机梯度下降(SGD)优化器。训练的迭代次数为30k,batchsize设置为8。对于数据的预处理,采用了随机裁剪、水平/垂直翻转、角度旋转等数据增强方式。实验使用的预训练模型是基于ImageNet数据集。我们采用mIoU (即所有类别IoU的平均值)作为评价指标。
3.3. 实验结果及分析
表1展示了我们的方法与部分主流的语义分割方法的比较。具体而言,我们选择的对比网络包括:FCN8S [1], DeepLabV3+ [16], PAN [17], UNet [4], UNet++ [5], Semantic-FPN [18], PSPNet [19], LinkNet [20], FarSeg [21], FactSeg [22]。通过比较可以看到在我们提出的AbHRNet网络中,mIoU达到了最高的51.14%,并且在背景、建筑、道路、荒地、农田等5个类别中都达到了最高的分割精度,尤其是帮助精度较低的荒地类别实现了较大的性能提升,这证明了我们提出的改进对于遥感图像地物覆盖语义分割任务是有帮助的。

Table 1. Comparison with mainstream semantic segmentation algorithms on the LoveDA dataset
表1. 在LoveDA数据集上与主流语义分割算法的比较
为了对我们提出改进的有效性进行验证,我们开展了相关的消融实验。正如表2所展示的,在基准网络HRNet上,mIoU为49.17%,而在主干网络中引入了CBAM注意力后,mIoU达到了50.79%,提高了1.62%,尤其是对于分割效果很差的荒地(Barren)类别,分割精度几乎上升了1倍,这说明引入的CBAM注意力帮助我们的模型关注到了数量较少的类别,并在训练过程中赋予其更多的权重,实现了有效的性能上升。而在基准网络交叉熵损失的基础上,引入了二元交叉熵损失和Dice Loss后,mIoU达到了51.14%,进一步地提升了0.42%,说明该损失可以有效地监督背景样本,并帮助极大或极小的目标样本实现更为有效的分割。
Table 2. Ablation experiments on the LoveDA dataset
表2. 在LoveDA数据集上的消融实验
与此同时,为了直观地证明我们提出方法的有效性,我们还在图6中展示了在LoveDA数据集上的语义分割可视化结果,图6(a)为原始的遥感图像,图6(b)为基准HRNet网络的分割结果,图6(c)为我们提出的AbHRNet网络的分割结果。其中第一行展示了在农村场景中的语义分割可视化结果。可以看到,基准HRNet网络将大部分的荒地目标样本错误地分类为背景样本,而在我们改进的HRNet网络中,则将大部分的荒地目标样本实现了正确的分割。而第二行则展示了在城市场景中的语义分割可视化结果。在图中的右下角可以看到,在我们提出的方法中实现了对森林类别和建筑物类别更精细的分割。最终通过可视化的结果,同样证明了我们提出的方法在遥感图像语义分割任务中实现了性能的提升。
4. 结论
本文提出了基于注意力的HRNet (AbHRNet)网络用于遥感图像地物覆盖语义分割任务。首先,通过在特征提取网络中引入卷积注意力(CBAM)模块,帮助模型更加关注我们感兴趣的目标特征信息,并减小由于复杂的背景信息带来的干扰;同时,我们还在基准网络交叉熵损失的基础上引入了二元交叉熵损失和Dice Loss,以实现对背景样本的有效监督,并解决了目标和背景、目标和目标之间由于面积差距过大带来的难以优化的问题。最终正如在LoveDA数据集上的实验结果所展示的,我们的方法达到了最优的性能,尤其是在分割效果不好的荒地类别中,实现了精度的翻倍。
基金项目
国家自然科学基金62271336。
NOTES
*通讯作者。