1. 引言
随着计算机视觉和图像处理技术的飞速发展,图像特征匹配在许多领域,如视觉同步定位与地图构建图(Simultaneous Localization and Mapping, SLAM) [1] 、立体视觉、图像拼接、物体识别等,起着至关重要的作用。尤其在视觉中,优秀的图像特征匹配算法是正确求解相机位姿的关键 [2] 。图像匹配主要分为灰度匹配和特征点匹配 [3] ,其中基于特征点的匹配方法具有良好的稳定性,对图像尺度、旋转、光照变化有良好的鲁棒性,成为了当前视觉SLAM中主流的图像匹配方法。
对特征的提取与描述是特征点算法的关键所在,对此的研究在很早就开展了,在2004年由Lowe等 [4] 学者首先提出尺度不变特征匹配算法(Scale Invariant Feature Transform, SIFT),利用高斯差分模板构建线性金字塔尺度空间并从中提取具有尺度不变性的极值点,通过图像梯度直方图构建 128 维描述符,但计算复杂度太高,导致SIFT算法的匹配时间较慢。因此,Bay等人在2006年 [5] 提出了加速稳健特征(Speeded up Robust Features, SURF)算法,该算法使用盒状滤波器模板简化高斯尺度空间来改进SIFT算法在保证算法鲁棒性,并将描述符从128维降低到64维,提高了算法匹配效率。2011年,Rublee等 [6] 对加速测试特征点检测算法 [7] (Features from Accelerated Segment Test, FAST)和二进制鲁棒独立特征描述子 [8] (Binary Robust Independent Elementary Features, BRIEF)进行改进,提出了具有旋转不变性的特征点提取算法(Oriented FAST and Rotated BRIEF, ORB),该算法采用二进制描述向量并结合汉明距离实现图像快速匹配,实验表明,ORB算法的匹配速度比SURF、SIFT算法相比提速10倍以上 [9] 。
除了这些经典的特征点算法外,在其上进行改进的特征点算法研究也在快速发展,在2017年,由Mur-Artal等人 [10] 在其提出的ORB-SLAM算法中首次使用四叉树分配算法改善特征点分布密集的情况,避免特征点因聚集而导致的误匹配问题,使特征点算法满足视觉SLAM需求。李伦 [11] 在对SURF特征点算法的基础上,提出了采用渐进采样一致算法(Progressive Sample Consensus, PROSAC)剔除误匹配点对的改进算法,该算法增强了特征点提取的稳定性,提高了匹配正确率。李国竣等 [12] 从阈值入手对ORB算法进行改进,通过设置不同的阈值以满足不同条件下不同图像的特征提取要求。在2022年,潘峰等人 [13] 将GMS算法融入进ORB特征点点算法中,通过四叉树分配算法均匀提取特征点并使用,并融合GMS算法剔除误匹配,其提取匹配效果优于原始ORB算法。
随着深度学习和视觉SLAM技术的进步,结合神经网络的语义SLAM应运而生并迅速发展。不包含语义信息的传统特征点算法将无法理解环境信息并消除误匹配,将不适用于语义SLAM中,因此本文提出了一种基于深度学习的语义特征点提取匹配算法,以满足语义SLAM系统需求。该算法结合语义分割网络和改进四叉树分配算法,实现特征点提取的语义化和均匀化,并采用语义角度直方图方法筛选匹配特征点对。实验评估显示,与传统算法相比,论文提出的算法具有较高的匹配准确性和稳健性,更适应语义SLAM系统需求,并对提高图像匹配准确性和稳健性具有重要意义。
2. 特征点算法与神经网络理论基础
2.1. Oriented FAST角点
ORB算法是由Oriented FAST角点 [14] 和Rotated BRIEF描述子 [8] 相结合组成的算法,这种算法旨在改进特征点的性能,同时保持高度精确和鲁棒性。
Oriented FAST角点在FAST角点的基础上增加了特征点对尺度和旋转的描述,FAST角点通过比较该点与周围其他像素灰度值的差别来确定的,具有较高的检测效率。提取如图1所示,具体过程如下:
1) 选取像素
,设其点亮度值为
。
2) 设置亮度阈值
,其值取
的20%。
3) 以像素
为中心,选取半径为3像素的圆上16个像素点。
4) 遍历对比,若所选像素点中有N个连续像素点的亮度值大于
或小于
,该像素点
为角点。
5) 循环以上步骤,遍历图像中各像素。
针对普通FAST角点存在的旋转匹配问题,改进的Oriented FAST角点通过计算灰度质心实现旋转不变性。首先在图像帧中某个图像块
,定义图像块的矩如式1所示。
(1)
式1中
表示在像素坐标(x, y)处图像的灰度值,
取0或者1,
表示图像的矩。将图像的灰度值作称为质心,根据式1计算得到质心C的位置:
(2)
连接矩阵块B的几何中心O和灰度质心C可得到方向向量
,因此FAST角点的方向角表示为:
(3)
经过改进的Oriented FAST在尺度和旋转变换下具有不变性,这增强了特征点在各种场景中的表示能力,从而提高了鲁棒性。
2.2. Rotated BRIEF描述子
Rotated BRIEF描述子由256位二进制字符组成,具体计算步骤如下:在以特征点原点为中心的像素区域
中,随机选择一对像素点,对它们的灰度值进行比较,得到描述子
的当前比特位的二进制值:
(4)
式4中
是点
处灰度值,
是点
处灰度值。进行256对像素点的对比,最终形成的256维二进制字符即为当前特征点的BRIEF描述子,如式5所示:
(5)
当前得到的BRIEF描述子没有方向性,而通过质心方向
可以实现Rotated BRIEF描述子。他们可以由2 × 256矩阵S表示:
(6)
通过式6得到的质心方向
可以计算对应的旋转矩阵
如式7:
(7)
由矩阵与方向,可得旋转描述子
:
(8)
改进的Rotated BRIEF描述子利用FAST角点在提取阶段获取的角点方向信息,使ORB特征点的描述子在图像旋转时具有良好的旋转不变性。
经过优化的Rotated BRIEF描述子结合了FAST角点在提取阶段获得的角点方向信息,使得ORB描述子在图像发生旋转时保持出色的旋转不变性。利用Rotated BRIEF描述子为位姿估计提供精确的特征点匹配对,这在视觉里程计中具有至关重要的作用。
2.3. 语义分割网络
在本文语义特征点算法中,采用YOLACT++网络 [15] 提取环境语义信息。YOLACT++网络是一种简单的全卷积实时语义分割网络,使用Resnet101-FPN作为主干网络,使用在MSCOCO数据集上训练得到的网络参数进行物体检测。假设YOLACT++网络的输入是一个x × y × 3的RGB 图像矩阵,则网络的输出就是一个x × y × n的掩码矩阵,其中n是图像中物体的数量。对于网络最后的每个输出通道
,都会得到一个对象的掩码矩阵,该网络实际分割效果图2所示。
根据图2可知,YOLACT++网络分割输出了物体掩码,置信度与目标定位框,其输出结果展示了网络精细的图像分割效果,将其物体掩码提取出来可视化后如图3所示。

Figure 2. Segmentation results of the YOLACT++ network
图2. YOLACT++网络分割效果图

Figure 3. Visualization of object masks
图3. 物体掩码可视化图
根据图3中的物体掩码,本文在提取ORB特征点时,根据其位置从语义信息图中提取相应的语义信息,为每个特征点赋予相应的语义信息,从而实现了ORB特征点的语义化。
3. 改进语义ORB算法
3.1. 改进语义ORB特征点提取流程
本文提出的改进ORB语义特征点使用语义信息并结合改进四叉树分配算法,具体提流程如图4。
从图4可知,在输入图像后,处理过程分为两个分支。其中一个分支将图像输入神经网络,以提取图像的语义信息矩阵;另一个分支则对图像进行预处理,构建图像金字塔,为均匀提取角点做好准备。在图像预处理过程中,首先将三通道的RGB图像转换为单通道的灰度图像,接着利用二维高斯分布函数作为卷积核对图像进行降噪处理,如式9:
(9)
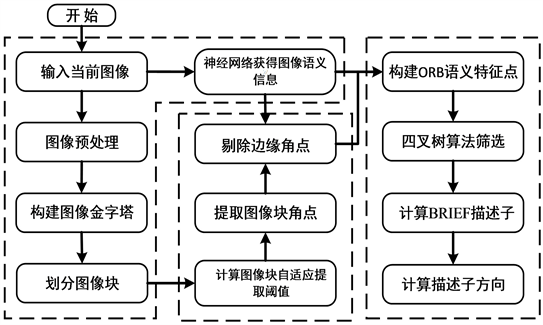
Figure 4. Flowchart for improved ORB semantic feature point extraction
图4. 改进ORB语义特征点提取流程图
该卷积核的公式如式9所示,其中参数
表示模糊半径,其值与图像的滤波平滑度成正比。此外,该流程中还建立了8层图像金字塔,将缩放尺度设置为1.2,并使用双线性插值的方式来保证图像效果。通过使用图像金字塔,相机图像在不同尺度下依然能够正确匹配。
3.2. 改进四叉树分配算法
改进ORB特征点算法分为提取与分配两个部分,在提取阶段,为了避免特征点提取过于集中的问题,改进ORB特征点算法使用了基于图像块的角点提取方式,将整个图像分割成多个图像块。为了平衡效率和性能,算法选择30 × 30像素作为提取FAST角点的图像块尺寸,并且对于图像末尾不足30像素的区域,将其整体视为一个图像块进行提取。为了确保在低纹理区域能够有效地提取FAST角点,本文提出了一种基于图像块的自适应阈值算法。该算法根据特定条件自动调整提取阈值
,具体而言,该阈值的设定方式为:
(10)
式10中
代表图像块中像素点的总数,
表示图像块的像素平均值,
代表位置
处像素的灰度值,而
为初始阈值,用于避免自适应阈值
过小而导致提取无效的特征点。根据经验,
的值设置为10。通过使用自适应阈值算法,可以根据不同纹理程度的图像块采用相应的阈值提取角点,从而使本文所改进的ORB算法能够适应不同纹理特征的环境,进而在每个图像块中都能提取出合适数量的FAST角点。
使用本文的自适应阈值算法后,每个图像区域都提取到了足够数量的FAST角点。因此,在确保角点数量的情况下,需要对提取的角点进行筛选,以保证它们分布均匀且具有良好的质量。为此,本文采用了四叉树分配算法对提取到的FAST角点进行筛选。该算法的大致流程如图5所示。
图5中红色为提取的特征点,蓝色带叉为停止分裂区域,其具体流程如下:
1) 将图像区域里的特征点输入算法中,并原始图像初始化根节点。
2) 将当前节点的区域通过四叉树算法分别划分为四个新的节点,将当前节点中特征点根据所处位置分配给对应的子节点。

Figure 5. Flowchart of quad tree allocation algorithm
图5. 四叉树分配算法流程示意图
3) 记录每个子节点区域内的特征点数量,若数量为零,则将该节点不再进行分裂,若数量不为零则继续进行四叉树分裂。
4) 计算当前已经划分的节点数量,若数量超过所需数量则停止分裂,同时保存节点内质量最好的特征点,若节点数量未超过所需数量,则返回运行步骤(2),对当前存在的有效节点继续进行四叉树分裂。
从图5可看出四叉树分配算法首先将图像划分为根节点,然后通过递归分裂的方式生成子节点。在此过程中,根据特征点的存在情况以及需求数量,对分裂过程进行控制。最终,在各节点区域内保留响应值最大的角点,以实现特征点的有效提取。
3.3. 边缘角点剔除
在利用四叉树分配和自适应阈值提取得到ORB语义特征点之后,需要结合神经网络得到语义掩码进行边缘点检测以消除边缘点。边缘点是指位于分割掩码边缘区域的角点,如图6所示。
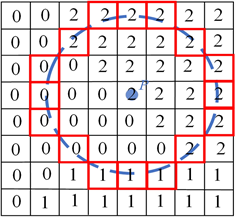
Figure 6. Illustration of edge and corner points
图6. 边缘角点示意图
图6中角点 为边缘角点,在本文中为了判断是否为边缘点,需要使用图像的语义信息矩阵。FAST角点提取涉及红圈中的灰度值判断,在本文方法具体实现中,以角点原点坐标为中心,考察7 × 7矩形块内的像素。若矩形块内存在与角点原点不同的掩码编号,则判定该点为边缘点并剔除。若完全相同,则保留非边缘点。通过剔除边缘点,仅保留稳健的语义特征点有利于语义特征点的准确匹配。
3.4. 语义角度直方图匹配优化算法
针对特征点匹配中存在的错误匹配特征点对问题,本文提出了一种语义角度直方图优化算法,以剔除误匹配点对。该方法分为两个部分:匹配点对角度差直方图筛选和语义类别筛选。利用ORB特征点所采用的Oriented FAST角点算法,可以获取特征点的角度信息。其匹配特征点的角度信息如图7所示:

Figure 7. Illustration of matching feature point angles
图7. 匹配特征点点角度示意图
在图7中,两幅图像间的匹配点特征点由连线表示,带有线圈的圆圈表示匹配特征点的方向角度。设第一帧匹配特征点的角度为α,第二帧匹配特征点的角度为β,则两帧之间匹配点的角度差可表示为:
(11)
根据式11,当两帧之间的角度差大于0时,角度差
等于两帧角度之差;而当角度差小于0时,角度差
等于两帧角度之差加上360˚。因此,角度差
的取值范围为0˚到360˚。将此范围划分为60个直方图区间,将计算得到的角度差值分配至相应的角度直方图区间内,统计每个区间内匹配特征点的数量,并绘制类似于的角度直方图。如图8所示,选取数量最多的区间作为正确匹配特征点,剔除其余错误匹配。此外,为了降低计算误差,保留正确区间相邻区间内的匹配点,这样的处理方法可以提高匹配特征点的准确性。
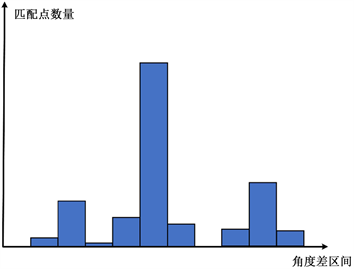
Figure 8. Illustration of angle histogram filtering
图8. 角度直方图筛选示意图
语义类别筛选通过对比特征点对的语义类别信息,对匹配特征点对进行优化。具体而言,当两个匹配点的语义类别相同时,保留该匹配对;若不同,则予以剔除。本文采用的筛选方法效果如图9所示。

Figure 9. Illustration of feature point matching filtering effect
图9. 匹配特征点筛选效果
对比图9与图7可以看出论文提出的语义角度直方图优化算法有效地筛选并剔除了误匹配,保留了正确的匹配点对。提高了论文提出的改进语义特征点的匹配精度。
4. 实验与结果分析
为了验证论文提出的改进语义特征点算法在特征点算法中的性能表现,本章将论文提出的改进语义特征点算法与普通ORB算法,四叉树分配算法特征点在特征点提取与特征点匹配两个方面进行实验评估,并在匹配环节使用多种环境场景多种匹配阈值进行评估分析。
4.1. 特征点提取实验
为了验证本本中提出的特征点提取方法的有效性,本节将采用改进的语义特征点提取策略,并将其与标准ORB特征点提取算法以及采用四叉树分配策略的ORB特征点提取方法进行对比分析。在同一张图片中分别提取了500个特征点以比较各方法的特征点分布。普通ORB算法采用OpenCV图像处理库中的实现版本,其提取效果如图10所示。

Figure 10. Extraction effect of regular ORB algorithm
图10. 普通ORB算法提取效果
在图10中,左侧图呈现了提取的特征点在RGB图像上的分布,而右侧图则展示了将这些特征点投影至由神经网络分割生成的掩码上,以更直观地反映特征点的分布情况。由图可知,标准ORB算法主要关注具有最大响应值的FAST角点,从而在图像中纹理较为丰富的区域聚集了大量特征点。然而,这种特征点分布过于密集,导致物体掩码上特征点数量不足,进而不利于对图像内物体的语义信息进行有效感知。
在四叉树分配算法中,为了提取500个特征点通常需要首先提取大量的特征点,然后通过筛选来减少其数量。本文提出了一种自适应阈值算法,与传统四叉树分配算法相比,后者采用固定的25提取阈值。两种算法提取到的特征点总数如表1所示。

Table 1. Total number of extracted feature points
表1. 提取特征点总数量
根据表1,可以发现固定阈值为25的四叉树算法与论文算法的特征点提取数量相近。图11展示了两种算法得到的特征点。
 (a) 四叉树算法特征点分布
(a) 四叉树算法特征点分布 (b) 改进语义特征点算法特征点分布
(b) 改进语义特征点算法特征点分布
Figure 11. Distribution effect of feature point extraction
图11. 特征点提取分布效果
在图11中,图11(a)展示了四叉树分配算法特征点分布,而图11(b)展示了本文语义特征点分布。从右侧的掩码特征点分布图中可以看出,在提取接近数量的待分配特征点的前提下,本文的改进语义特征点所采用的自适应阈值算法相较于传统四叉树算法的固定阈值提取,能够实现更加均匀的特征点分布,满足了语义SLAM系统对提取特征点的要求。此外,改进语义特征点利用图像的语义信息剔除了位于掩码边缘的特征点,这有利于减少在进行语义特征点匹配时可能出现的误匹配情况。
4.2. 特征点匹配实验
本章采用TUM数据集中的室内图像数据集进行实验,确保方法有效性和实验可靠性。实验从数据集中选取三种室内场景的图像序列,分别为fr1_rpy,fr2_desk和fr3_sitting_xyz,三种室内场景如图12所示。


 (a) fr1_rpy (b) fr2_desk (c) fr3_sitting_xyz
(a) fr1_rpy (b) fr2_desk (c) fr3_sitting_xyz
Figure 12. Illustration of experimental scene image
图12. 实验场景图像示意图
图12为选定场景序列图像,在选定的匹配图像中,包含多种室内场景和相机运动,如相机上下旋转(fr1_rpy)、左右旋转(fr2_desk)和平移(fr3_sitting_xyz)。选定这些图像进行对比实验可以确保本文方法的可信性。
本章实验采用三组不同环境匹配图像提取同样500个特征点,采用50,65,80三种提取阈值,匹配方法使用汉明距离暴力匹配,比较普通ORB算法,四叉树分配算法与本文语义特征点算法的特征点匹配精准度,三种算法的匹配特征点数量如表2所示。
Table 2. Number of matching feature points in three different scenarios
表2. 三种场景下匹配特征点数量
表2中为不同匹配方法使用三种阈值下的匹配点数量,可以看出未进行均匀化的普通ORB方法在三对匹配图像的三种阈值下的匹配点数量上都有巨大的优势。图12为普通ORB方法在65匹配阈值下匹配点图,在图中两张图像为匹配图像对,相连线段为匹配图像的匹配特征点对。

 (a) fr1_rpy (b) fr2_desk
(a) fr1_rpy (b) fr2_desk (c) fr3_sitting_xyz
(c) fr3_sitting_xyz
Figure 13. Illustration of matching points using regular ORB method
图13. 普通ORB方法匹配点示意图
从图13中可以观察到,传统的ORB方法在提取特征点时,主要集中于纹理丰富的区域。这一特性使得它能够匹配到更多的特征点,然而,这也导致匹配点过于密集且存在误匹配的情况,并不满足语义SLAM对特征点算法的需求。因此需要采用四叉树分配算法来实现特征点的均匀分布。而本文所提出的语义特征点方法与四叉树分配方法在阈值为65时的匹配效果如图14所示。

(a) fr1_rpy
 (b) fr2_desk
(b) fr2_desk (c) fr3_sitting_xyz
(c) fr3_sitting_xyz
Figure 14. Comparison of matching feature points between two algorithms
图14. 两种算法匹配特征点对比示意图
在图14中,左侧展示了基于四叉树分配方法的匹配结果,而右侧则展示了论文提出的基于语义特征点方法的匹配结果。通过与图13的对比可以发现,尽管使用四叉树分配方法得到的匹配点数量减少,但其分布更加均匀,更符合视觉SLAM的需求。将本文提出方法与四叉树分配方法进行比较,从图14中可以观察到,在65匹配阈值下,本文提出的优化方法能够剔除大部分误匹配,保留正确的匹配特征点对。然而,在相同的匹配阈值下,四叉树分配算法匹配特征点仍存在大量误匹配。因此,通过图12与图14的对比,可以看出论文提出的改进语义特征点方法在65阈值下能够有效地去除大部分误匹配。而在相同条件下,两种对比方法均出现了大量误匹配,已无法求解正确的变换位姿,这进一步证明了对匹配点对进行筛选优化的重要性。
论文提出的改进语义特征点方法通过语义角度直方图优化匹配结果,结合特征点的语义类别和角度差实现精确匹配。本文算法在TUM数据集的三种室内环境,50与80匹配阈值下的特征点匹配效果如图15所示。

(a) fr1_rpy
 (b) fr2_desk
(b) fr2_desk (c) fr3_sitting_xyz
(c) fr3_sitting_xyz
Figure 15. Illustration of image feature point matching under two thresholds
图15. 两种阈值下图像特征点匹配示意图
在图15中展示了两个匹配图像对,它们之间的连接线段表示匹配特征点。左图使用描述子匹配阈值为50,而右图为80。在阈值为50的情况下,结合本文提出的语义特征点匹配优化方法,可以确保得到的匹配特征点都是正确的,没有不符合相机运动方向的错误匹配。然而,在阈值为80的宽松匹配条件下,理论上会有大量误匹配,但通过本文提出的语义直方图筛选算法,仍能筛选掉了大部分错误匹配,并保留了正确的匹配特征点对。因此,实验结果表明本文使用的语义角度直方图优化算法能够稳定有效地筛选掉特征点匹配环节中出现的误匹配,大大提高了本文语义特征点的匹配精度。
5. 结束语
本文提出了一种改进的语义特征点算法,旨在满足语义SLAM系统对特征点的需求。该算法使用YOLACT++网络对图像进行分割,提取匹配图像内的语义信息,并在特征点提取环节结合语义信息与改进四叉树分配算法实现特征点的语义化与均匀化。同时,在特征点匹配环节,本文提出了基于本文语义特征点算法的语义角度直方图匹配优化算法,该算法通过语义筛选与角度直方图筛选两个环节来剔除误匹配,从而获得更精准的特征点匹配对。实验对比评估表明,与对比方法相比,本文提出的语义特征点算法在提取上实现了特征点的语义化与均匀化,并满足了语义SLAM系统对特征点的需求。此外,本文提出的匹配优化算法在多种场景多种匹配阈值下匹配精度均高于对比算法,实现了本文语义特征点的精准匹配。因此,本论文算法具有重要的理论和实际应用价值。