1. 引言
农业是国民经济基础,农产品是农业中生产的物品。随着数字经济日渐融入农业 [1] ,显著加速了农产品现代化进程。2022年的“中央一号文件”指出,大力推进数字乡村建设,坚决守住农产品质量安全底线 [2] 。然而,我国冷链物流不发达,每年至少四分之一的农产品在物流过程中腐烂 [3] ,农产品的腐烂不仅产生的气体对生态环境有较大的破环,而且对食用腐烂农产品的人易患食源性疾病 [4] ,达到流行病的传播速度。因此,生鲜农产品质量关乎国家生态持续发展以及农村高质量发展,必须加强对农产品冷链绿色物流相关的监测和管理风险,提高生鲜农产品质量建设。
学者对于保证新鲜农产品质量的冷链绿色物流问题,一部分学者将工作的重点放在调度优化上 [5] ,另一部分学者将工作重心放在供应链风险的识别和管理 [6] 。虽然有少数学者对新鲜农产品冷链绿色物流风险进行了研究,但是大多数研究是从宏观角度进行了供应链风险识别 [7] ,并且在新鲜农产品冷链绿色物流中,仍然存在的物流风险分类和识别管理不善的问题,可能会导致许多供应链环节的新鲜农产品的腐烂和损失 [3] 。而且现有的风险类别分类缺少统一的标准:无法有效识别农产品冷链绿色物流过程中发生的风险。相反,对于在新鲜农产品运输过程中产生的多种因素物流风险,统一的风险分类标准将会有助于决策者识别、评估和降低农产品冷链绿色物流运输风险 [6] 。
支持向量机常用于评估和预测信用风险、健康状态和网络安全态势 [8] 。由于支持向量机在开发大数据和云计算方面比传统方法更为准确 [9] ,具有较好的“鲁棒性”和优秀的泛化能力,避免了“维数灾难”以及过拟合问题 [8] ,因此使用支持向量机来评估农产品冷链绿色物流风险。
农产品冷链绿色物流运输过程中的风险识别和评估目的在于识别潜在风险,并采取适当措施避免或尽量减少运输物品的损失。本文为识别和评估新鲜农产品冷链物流提供理论依据,建立科学合理的风险评估体系,对现有的新鲜农产品冷链绿色物流风险因素研究进展进行分析总结,使用分解分析法划分绿色物流流程,结合事故致因相关理论,构造风险评估体系和分级标准,增加压缩变量和反正切函数学习变量以及个体之间的交叉与自身的变异率,改进粒子群算法,建立IPSO-SVR模型,对一家草莓物流运输公司数据进行风险评估,通过不同的模型对比,验证了本文模型的准确性和可靠性,为农产品绿色物流风险评估提供了科学依据。
2. 建立风险评估体系与分级标准
2.1. 风险评估体系
生鲜农产品具有易腐烂、不易保存的特性 [10] ,在物流调度中,容易收到外部和内部的各种因素影响,导致生鲜农产品腐烂和损失。为识别和评估新鲜农产品冷链物流提供理论依据,建立科学合理的风险评估体系,对现有的新鲜农产品冷链物流风险因素研究进展进行分析总结。
2.1.1. 文献分析
Xiuquan Deng [11] (2019)提出风险原因、风险参与者和风险输出三维模型,在此基础上,分析得到易腐烂产品供应链中九种关键风险因素;Surya Prakash [12] (2017)通过了解易腐烂食品供应链中各种风险之间的动态,基于解释性结构(ISM)对易腐烂食品供应链风险因子其进行分析,识别四类和17种风险因子,得到供应链风险的相互关系的见解,提出有效的降低风险的降低策略;Dilupa Nakandala [13] (2016)从货物物流流程角度考虑,将新鲜产品供应链风险划分为五种风险,建立混合风险评估模型,最终获得整体RL的风险来源。周欢 [14] (2021)针对港口危化品的物流风险问题,从物理–事理–人理三个维度分析,构建WSR模型,对港口安全进行评估与监控;赵闯 [15] (2020)考虑内外因素,将生鲜配送物流风险划分为信息技术,设施设备,人员操作和外部环境四个维度进行定量分析,从而使生鲜企业更好的规避风险;付焯 [7] (2018)根据疾病传播的相关原理,将生鲜配送物流风险划分为作业、管理、环境、时效和空间风险五个维度进行分析,从而得到各个参数对于物流供应链的风险评估;张琰 [16] (2017)根据冷链物流理论,根据物流流程将生鲜农产品物流风险划分为7个维度进行描述分析,从而降低生鲜农产品物流成本,完善风险预警管理。如下表1所示:
1) 人员组织风险
人员组织风险是指,在生鲜农产品配送中涉及到的各类人员,在遇到紧急情况时,人员的应急能力;在运输中遇到道路故障,临时优化调度的能力;设备损坏后的维护能力、应急计划的实施能力,将影响生鲜农产品的质量。
2) 设备设施风险
设备设施风险是指,生鲜农产品的运输环境要求和对设备设施的操作要求极高,若处理不当,将无法保证生鲜农产品的保鲜,同时,设备设施是冷链物流的载体,是重要的组成部分,所涉及的设施设备可能发生故障的风险,因此,我们要即关注设备的振动频率、车身压力、振动加速度等指标,保证生鲜农产品在适宜的保鲜环境中,又要关注设备的机械损伤和完整性、设备的稳定性等指标,减少设施设备出现故障的风险。
3) 外部环境风险
外部环境风险是指,生鲜农产品在运输过程中遇到的一些不可控因素的风险,在运输中气候、道路和交通的稳定性,将会影响货物到达目的地的时间,若发生极其恶劣的情况,甚至会导致无法运输。因此,分析外部环境风险,将会有利于运输计划的顺利实施。
4) 可持续风险
在健康中国和美丽中国两大国家战略的建设背景下,实施绿色物流是一项有利于社会经济可持续发展的战略措施。生鲜农产品在运输过程中,不当的存储不仅会造成生鲜农产品的损失,也会对周边的环境产生一定的污染。因此,选择了四个指标来衡量生鲜农产品包装和保鲜相关的可持续风险。

Table 1. Literature analysis of risk assessment for fresh agricultural products
表1. 生鲜农产品风险评估文献分析表
2.1.2. 建立风险评估体系
结合上述文献分析,可以了解到在物流中有许多因素会影响生鲜农产品的质量,运用分解分析法 [17] ,以系统、简单、可行的方法为目标,通过对生鲜农产品物流流程详细分析,找出生鲜农产品物流系统的各组成要素,识别影响物流的风险因子。
1) 运用分解分析法分解物流流程
首先,在接收到生鲜农产品订单后,考虑物流运输的距离和时间因素,在全程冷藏保温存储和大数据监控下,根据运输的种类选择合适的运输方式,通过生产加工、流通加工后,将生鲜农产品进行冷藏保鲜,进行成本核算签订运输合同,运输到目的地后,再通过批发环节和零售终端进行冷储销售,整个运作流通模式如下图1所示。
2) 建立风险评估体系
通过对生鲜农产品流通流程进一步分析,物流过程涉及四个部分,冷冻加工、冷冻储藏、配送运输及冷储销售。结合事故致因相关理论,即从人、设备、作业、管理四个维度进行考虑,结合上述文献分析,可将物流风险因子划分为四个一级指标,二十二个二级指标如下表2所示。
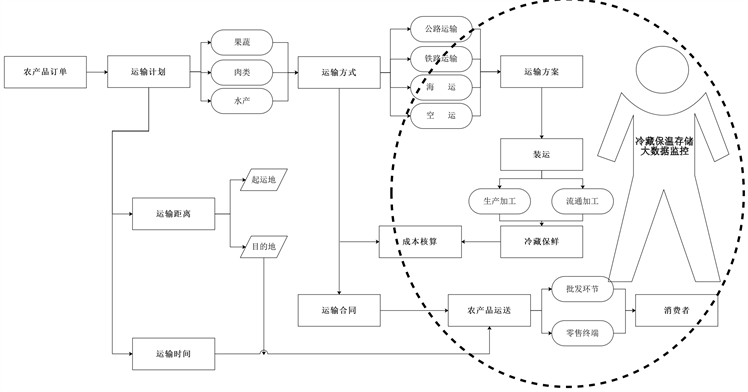
Figure 1. Flow chart of fresh agricultural product transportation work
图1. 生鲜农产品运输工作流程图
Table 2. Risk assessment system for fresh agricultural products
表2. 生鲜农产品风险评估体系
1) 人员组织风险
人员组织风险是指,在生鲜农产品配送中涉及到的各类人员,在遇到紧急情况时,人员的应急能力;在运输中遇到道路故障,临时优化调度的能力;设备损坏后的维护能力、应急计划的实施能力,将影响生鲜农产品的质量。
2) 设备设施风险
设备设施风险是指,生鲜农产品的运输环境要求和对设备设施的操作要求极高,若处理不当,将无法保证生鲜农产品的保鲜,同时,设备设施是冷链物流的载体,是重要的组成部分,所涉及的设施设备可能发生故障的风险,因此,我们要即关注设备的振动频率、车身压力、振动加速度等指标,保证生鲜农产品在适宜的保鲜环境中,又要关注设备的机械损伤和完整性、设备的稳定性等指标,减少设施设备出现故障的风险。
3) 外部环境风险
外部环境风险是指,生鲜农产品在运输过程中遇到的一些不可控因素的风险,在运输中气候、道路和交通的稳定性,将会影响货物到达目的地的时间,若发生极其恶劣的情况,甚至会导致无法运输。因此,分析外部环境风险,将会有利于运输计划的顺利实施。
4) 可持续风险
在健康中国和美丽中国两大国家战略的建设背景下,实施绿色物流是一项有利于社会经济可持续发展的战略措施。生鲜农产品在运输过程中,不当的存储不仅会造成生鲜农产品的损失,也会对周边的环境产生一定的污染。因此,选择了四个指标来衡量生鲜农产品包装和保鲜相关的可持续风险。
2.2. 风险分级标准
将运输中生鲜农产品面临的风险划分为四个严重程度级别(1~4,分别代表极低、低、高和极高)进行评估,根据评估的结果企业采取不同的措施,如表3所示:
Table 3. Risk grading standards for fresh agricultural products
表3. 生鲜农产品风险分级标准
3. 模型建立与分析
支持向量机是一种用于分类和回归的人工智能学习方法 [9] ,常用于评估和预测信用风险、健康状态和网络安全态势等问题。支持向量机在开发大数据和云计算方面比传统方法更为准确,具备较好的“鲁棒性”以及优秀的泛化能力,避免了“维数灾难”以及过拟合问题 [8] ,比传统的评估模型更有效。此外,传统支持向量机主要用于二值分类问题,为使其适用于多分类问题 [9] ,本文采用一对一方法,构造
个二分类器(问题有k类)。因此,在本研究中,使用支持向量机解决小样本和高维问题,从而评估农产品冷链物流风险。
3.1. 支持向量机算法
假设给定的样本数据集和标签分别为
,
,
,则支持向量机的传统二分类SVM数学模型为:
(1)
所有样本不一定能够保证线性可分,因此,为提高模型的适用性,在目标函数中增加具有不确定性的惩罚因子。其中:w为权重向量;C为惩罚因子,惩罚因子数值越大对产生误差的数据点惩罚越大;
为数据被错误分类时产生的误差(松弛变量)。
当上式的约束条件取“=”时,上式对应的解称为支持向量。根据拉格朗日对偶原理可将上述式子转化为:
(2)
式子中
称为核函数,核函数是SVM解决非线性分类问题的核心,目前应用最广泛的核函数有4种。高斯核函数适应性强,参数少以及泛化能力较好,因此,本文选择高斯作为模型的核函数,其具体的表达式为:
(3)
公式(2)可解,若解为
,则公式(1)的最优解为:
(4)
(5)
决策函数为:
(6)
在公式(6)中:
为拉格朗日乘子;
为满足Mercer定理的核函数;
为截距。上述过程的KKT条件为:
(7)
满足
的向量被称作支持向量,在决策函数(6)中,若
,则目标函数的值为0,若
,结合KKT条件中的
可以得到:
,此时的
的值为正负1,换句话说,当支持向量
不为零时,支持向量
才会在决策变量中起作用。
支持向量机根据惩罚因子C和核函数参数σ值的变化,分类结果差距巨大,一方面,C值太大或者σ值过小,高斯分布比较集中,会使得模型过度学习,从而造成模型泛化,另一方面,C值太小或者σ值过大,高斯分布会太平滑,模型会产生欠学习的状态。因此,选择最佳参数是支持向量机优化的最大难题。由于支持向量机参数和分类结果之间的联系无法使用函数映射体现,只能够通过重复的训练测试来选择支持向量机的参数,整个过程过度依赖专家的经验,不仅耗时耗力、效率低下,而且对于复杂问题的参数很难得到合理设定,在一定的程度上限制了SVM的发展。针对此问题,许多学者将支持向量机的参数设定问题转化为最优解问题,采用智能算法来求解该问题。
3.2. 基于改进PSO算法的支持向量机参数优化
粒子群算法相比其他的智能算法,粒子群算法具有参数少、编码简单、寻优速度快、效率高等优点 [8] 。然而,粒子群算法在后期容易陷入局部最优解,因此本文对粒子群算法中引入压缩变量和反正切函数学习变量以及个体之间的交叉与自身的变异率。从而加强粒子群算法的全局搜索能力,增强对支持向量机参数的寻优能力。具体步骤如下:
Step 1:设置粒子群算法的迭代次数、惩罚因子以及种群数量等参数,将种群初始化,生成支持向量机松弛系数及惩罚因子C和核函数参数σ粒子的初始位置和速度。
Step 2:将每个粒子的参数在支持向量机中训练,对训练结果跟实际情况对比,计算均方根误差,根据均方根误差的数值确定每个粒子的适应度。
Step 3:每次的粒子适应度与前面所有的粒子适应度对比,选用粒子适应度最高的。更新过程中进行个体之间交叉率为0.7的交叉以及个体自身变异率为0.7/种群数量的变异。
Step 4:在粒子的速度公式中引入压缩因子、反正切函数学习因子
、
进行速度和位置更新。
(8)
(9)
Step 5:若满足终止条件,则输出最终解,否则返回Step 2。
通过使用IPSO算法对支持向量机的c和g寻优,找出适合模型的最佳参数,建立IPSO-SVR模型,将来源于一家草莓物流运输公司的数据带入IPSO-SVR模型,得到农产品风险评估等级。IPSO-SVR模型以及评价流程如下图2所示:

Figure 2. IPSO-SVR model and evaluation flowchart
图2. IPSO-SVR模型以及评价流程图
4. 实例求解与分析
4.1. 数据来源及处理
数据来源于一家草莓物流运输公司,将其数据划分为定量和定性数据。对于定量数据,由于数字经济推进农产品流通现代化进程,该物流企业能够收集到生鲜农产品在运输过程中的数据。例如冷藏车内温度、湿度传感器,获得冷藏车内实时得温度和湿度;数字经济的数据信息跨时空传递特征使得该物流公司,可以借助全球定位系统(GPS)和数据库技术,自动匹配道路状况等数据。对于定性数据,采用层次分析法进行定量处理。例如:对于物流企业的设备效率、员工技能、管理水平等指标,采用五级量表进行衡量,其中一级表示企业有高效的设备和熟练的员工,而四级表示设备效率低和员工操作不熟悉。此外,对于运输管理、保鲜规划和应急规划,管理者可以使用关键事件方法来衡量绩效。最后,对于定性指标,在数据收集的早期阶段,通过检测和调查确定水平。随着数据量的增加,使用人工智能技术学习和训练风险评估模型。对数据进行描述性统计,如下表4所示:
Table 4. Descriptive statistics of data
表4. 数据描述性统计表
从上表可知,数据没有出现异常增加或减少情况,因此,存在异常值的可能性较低,然而,个别指标之间差别较大,例如运输时间的最大值是相对湿度的48倍,因此,需要将样本的数据标准化处理,映射到[0, 1]区间,去除样本数据单位限制,有效调整指标的范围,避免不当的数据选择,减少预测误差。使用
,
进行标准化处理。
由于风险评估体系指标的数量相对较多,为降低模型的计算难度,以及提取主要成分进行可视化,对指标间相关性进行分析,在确保样本数据信息丢失最少的目标下,对数据指标进行降维,选择代表最多信息的特征进行数据可视化。使用主成分分析进行数据降维。如图3所示:

Figure 3. Sum of variance for cumulative interpretation of data
图3. 数据累积解释方差和图
曲线为累积可解释方差贡献率,通过使用最大拟然估计方法选择超参数,特征值选择为23,其方差贡献率为99.99%,选择最大2个主成分进行数据样本的可视化,其总解释方差为79.41%,在一定程度上可判断数据集的分布情况,如图4所示。

Figure 4. Distribution of the dataset
图4. 数据集的分布情况图
从图中可以看出,四种不同风险等级相互交叉,很难找出明确的分界线,将四种风险等级划分,而支持向量机在开发大数据和云计算方面比传统方法更为准确,具有较好的“鲁棒性”和优秀的泛化能力,避免了“维数灾难”和过拟合问题 [8] ,因此将标准化以及降维后的数据带入模型,来评估农产品冷链物流风险。
4.2. 研究过程
本文使用朴素贝叶斯(NBM)、决策树(DT)、邻近算法(KNN)、逻辑回归(LR)、神经网络(ANNS)、四种核函数的支持向量机的模型,进行分类性能上对比,使用基于标准网格算法的最优核函数支持向量机(GS-SVR),和标准粒子群算法的支持向量机(PSO-SVR)模型,验证IPSO算法提高了参数优化的效率,评价指标为:拟合优度(R2),准确率(Accuracy),精准率(Precision),召回率(Recall),F1值(F1_score),时间(Time)。
拟合优度(R2)是对模型的拟合效果打分,其取值范围是
,取值越接近1模型的数据拟合性就越好。
准确率(Accuracy),精准率(Precision),召回率(Recall),F1值(F1_score)。是根据模型的混淆矩阵进行计算,如下表5所示:
Table 5. Confusion matrix and evaluation index calculation table
表5. 混淆矩阵以及评价指标计算表
准确率(Accuracy)是指正确分类样本个数占总样本个数的比例,反映对数据的整体分类能力;召回率(Recall)是指预测正确的A类数据占实际A类数据的比例,召回率越高,代表尽量捕捉越多的少数类;精准率(Precision)是指预测正确的A类数据占预测为A类数据的比例,即将多数判错后所需付出的成本;召回率和精准率之间是相互矛盾的,两者之间的平衡是指在满足捕获少数类别的同时减少对多数类的误伤之间的平衡,F1值(F1_score)便是作为考量两者平衡存在的调和平均值综合指标,其数值范围在
,越接近1效果越好。
4.3. 结果与分析
基于pytho以及Scikit-learn库,对标准化以及降维后的249个数据,分别输入到朴素贝叶斯(NBM)、决策树(DT)、邻近算法(KNN)、逻辑回归(LR)、神经网络(ANNS)、四种核函数的支持向量机的模型中,使用confusion_matrix()和soce()函数得到每个模型的混淆矩阵和拟合优度,如下图5所示:



Figure 5. Confusion matrix diagram of each model
图5. 各个模型混淆矩阵图
从上图可以看出,knn和核函数为sigmoid的拟合优度效果最差,核函数为rbf的支持向量机、决策树和神经网络的拟合优度效果为最好是0.98。混淆矩阵的斜边颜色越深,说明模型的分类准确性更高,从颜色深浅可以判断决策树的分类效果最差,通过对混淆矩阵进一步处理,得到准确率(Accuracy),精准率(Precision),召回率(Recall),F1值(F1_score)指标,如下表6所示。
从下表可知,SVR在各项指标上都位居前五位,相对去其他五个模型;其中核函数为Rbf的支持向量机在拟合优度方面远远超出其他支持向量机模型,对数据整体进行了更加精准的分类,精准率和召回率方便表现更加平衡,虽不是最高,但精准率和召回率两个指标的调和平均值综合指标排名是第一名;综合来讲,支持向量机相对其他模型有着更为出色的分类效果,核函数为Rbf的支持向量机表现尤为出色。
Table 6. Score table of evaluation indicators for each model
表6. 各个模型评价指标得分表
基于python以及Scikit-learn库,在IPSO-SVR模型中各个参数设置为:松弛系数及惩罚因子C的取值范围是[0, 10],核参数gamma及缩写g的取值范围是[0, 10],交叉验证为5-fold,种群数量为50,迭代次数为80,学习因子
为0.2,学习因子
为0.5,惯性因子w为0.5。GS-SVR模型参数和IPSO-SVR模型设置参数相同,GS-SVR模型的g和c的参数范围相同,具体结果如下表7所示:
Table 7. Various model parameters and evaluation indicators table
表7. 各个模型参数以及评价指标表
结果表明,所有的模型在使用RBF核函数的支持向量机下,对农产品绿色物流风险进行了有效的分类,分类的准确率最低达到了80.32%。GS、PSO以及IPSO算法对SVR参数的优化,都极大提高了模型的准确率。在时间评价指标上,GS算法运行的效率远远比IPSO和PSO算法慢,在准确率指标上,IPSO算法最为出色,提高了SVR准确率的9.62%,分类效果更优,综上所述,本文提出的IPSO-SVR模型能够更好地应用于农产品绿色物流风险评估。
5. 结论
本文为识别和评估新鲜农产品冷链物流提供理论依据,建立科学合理的风险评估体系,通过对文献分析,使用分解分析法划分农产品绿色物流流程,结合事故致因相关理论,将物流风险因子划分为人员组织、设备设施、外部环境以及可持续风险。建立科学合理的风险评估体系和分级标准;然后,增加压缩变量和反正切函数学习变量以及个体之间的交叉与自身的变异率,改进粒子群算法,克服由人为因素或客观数据差异带来的影响,建立IPSO-SVR模型;最后,并对一家草莓物流运输公司数据进行风险评估,通过九种模型对比,RBF核函数的SVR模型精准率和召回率两个指标的调和平均值综合指标排名第一,验证RBF核函数的SVR模型优越的分类性能;通过三种模型对比,在准确率指标上,IPSO算法最为出色,提高了SVR准确率的9.62%,验证了本文IPSO算法对支持向量机参数寻优的优化效率。通过十一种模型验证了本文模型的准确性和可靠性,为农产品绿色物流风险评估提供了科学依据。
对于未来工作,我们侧重以下两点:1) 将使用更多的实例,以证明AHP-IPSO-SVR模型的准确性和普遍性;2) 对于大量的数据,支持向量机运算能力可能有限,后续考虑研究更强大的机器学习模型,如卷积神经网络。
基金项目
国家自然科学基金地区项目,编号(72261005),数据驱动下考虑学习与恶化效应的绿色制造资源配置方法研究;贵州省省级科技计划项目:数据驱动下基于集成学习的云制造资源配置及其应用研究(编号:黔科合基础-ZK [2021]一般339);贵州省省级科技计划项目:数据驱动下基于深度计算的智慧云物流资源配置方法及其应用研究(编号:黔科合基础-ZK [2022]一般080);贵州省哲学社会科学规划课题一般项目:数字经济对贵州高质量发展的溢出效应及其传导机制研究(编号:21GZYB09);产业集聚对绿色发展的时空差异及传导机制研究(编号:21GZYB10);贵州大学“研究基地及智库”重点专项课题:数字经济对贵州省新型工业化发展的影响要素及其路径研究(编号:GDZX2021031)。