1. 引言
植被通常指被地球表面覆盖的群落的总称,包括森林、草原和灌木等,是地表生态系统的重要组成成分,形成了以土壤、水和大气为中心的生态循环系统。正常情况下植被可在光照、温度、土壤等适宜的自然条件下稳定生长演替,植被与自然因素和人为活动的影响息息相关,其中自然因素方面包括地表土壤粗糙度、地貌类型、气温气候等的变化;人为活动方面包括人类社会的扩张,对生态系统的破坏等,同时植被盖度的变化可以反映区域内的生态环境变化,因此诸多国内外专家很早就开始了对植被覆盖的研究,在一定程度上也有助于揭示生态系统的变化特征。在计算植被的具体覆盖度时,所采用的方法主要有传统测量法和遥感测量法。传统测量法主要包括使用测量仪器测量的仪器法、专业人员人工估算的目测法以及划分样点和样方的采样法,其中仪器法借助一些仪器(如移动光亮机、空间定量仪等)使光透过植被表层来反映植被的生长状况,进而对植被的覆盖度进行估算,其中使用最多的测量方法有照相法和空间计量法等 [1] 。目测法是最初和最原始的传统测量法,该方法主观性大,数据的精度不高,受观测人员观测能力的影响大,即使对于相同的测量区域,不同的测量人员或者不同的测量规范都会使植被覆盖度的测算存在差异;采样法是对研究区域进行样点或样方区域进行划分,通过计算指定样方区域的植被覆盖度来估算整个研究区域的植被覆盖情况,该方法通常精度较高,但一般耗时较长,效率较低,常见的采样法有阴影法、样点法、样方法等。遥感测量法主要有像元分解模型、植被指数法、经验模型法等。其中像元分解模型假设图像中有很多混合像元(即像元中有不止一种地物),通过分解这些混合像元得到像元中的单一的植被指数信息,通过分解的这些植被指数信息来获得研究区域的植被覆盖度;植被指数法是通过建立植被指数,以植被相关的光谱信号为基础,在一定程度上反映植被的实际生长状况,进而估算出研究区域的植被覆盖度。传统测量方法对植被覆盖度进行估算时具有很大的灵活性,测量人员可以根据实际地形将仪器安置在合适的位置,时间和空间上都比较灵活,且估算结果通常较为精确,然而该方法也有一定的局限性,受天气因素、地形地貌因素、及仪器自身精准度的影响,人力和物力成本通常较高。近些年遥感技术的快速发展为实时、动态和连续的植被覆盖度检测和评价提供技术支撑,高分辨率的遥感影像可以提供不同时空尺度的植被覆盖信息及动态变化,同时遥感数据还具有获取周期短、速度快、精度高、成本低、不受天气和时间的限制等优点,所以近年来越来越多的研究人员开始以遥感技术为主要技术手段来获取区域植被覆盖度等参数,进行地表特征相关的课题研究 [2] [3] [4] 。
由于植被指数法用的模块工具操作简单,且估算的植被覆盖信息精度较高,因此目前对植被覆盖的计算主要通过植被指数来实现,常见的植被指数有归一化植被指数、土壤植被指数等,其中归一化植被指数精度最高、应用最为广泛,但是对植被高覆盖区的敏感度不高,对于较高植被的区域使用NDVI指数计算易产生偏差,因此在实际应用中常采用一些估算模型对该指数进行修正来提高其准确性 [5] [6] 。
2. 研究区域概况
2.1. 研究区域地理位置
北京市是中国的首都(东经,北纬),位于华北平原的西北边缘,总面积16,400平方公里。总体地形走向西北高东南低,东、西、北三面环山。北京是典型的暖温带半湿润大陆性季风气候,夏季炎热多雨,冬季寒冷干燥,降水时空分布不均,年平均降水量约600 mm,由于北京地形复杂,生态环境多样,植被类型丰富,垂直分布规律明显 [7] 。北京市行政区划包括主城区(东城区、朝阳区、海淀区)、大兴区、怀柔区等11个行政区县,如图1所示。
2.2. 研究区域自然资源概况
受暖温带大陆性季风气候影响,北京地带性自然植被为暖温带落叶阔叶林。在西部和北部山区,气候和土壤随着海拔的升高表现出明显的垂直分异,植被垂直分布明显。低山中次生落叶阔叶灌木以牡荆、杏、桃为主,常见的伴生种有蚱蜢腿、雀舌。在一些地区,栓皮栎林、麻栎林、油松林和侧柏较为分散。森林中常见的伴生树种有白术、桑树和榆树。盐肤木、香附、节油也分布在低山峡谷。中山地区分布有油松、辽东栎和山杨。林下灌木包括二色胡枝子、紫丁香、苦楝等。在高海拔地区,主要有华北落叶松林、格氏栲林、格氏栲林等植物群落。然而,由于原始森林的大规模破坏,大多数次生林现在由山杨和桦树组成。此外,在平原地区还有欧亚大陆草原成分,如蒺藜、猪毛菜、柽柳、碱蓬等,深山区保留有欧洲西伯利亚成分,如华北落叶松、云杉、圆叶鹿蹄草、舞鹤草等;同时,有热带亲缘关系的种类在低山平原也普遍存在,如臭椿、(左木,右栾)树、酸枣、荆条、黄草、白羊草等。这些反映了组成北京植被区系成分的复杂多样 [8] [9] 。
由于不同地区成土因素的差异,北京地区土壤分布从山地到平原具有一定的规律性;山区土壤多为棕壤、淋溶褐土和山地草甸土;平原区从冲积扇顶部向下逐渐为褐土、潮褐土、潮土,东南部低洼平原为盐渍潮土;北京郊区是一个高肥力的菜园土,在天然土壤的基础上经过多年的培育。
北京水资源严重短缺,且时空分布不均云。北京的主要供水来源是地下水、地表水和再生水。从2000年到2006年,全市总用水量逐年下降,从2000年的40.47亿立方米下降到2006年的34.3亿立方米。2007年,全市计划用水35.5亿立方米,其中再生水4.8亿立方米。境内无主要河流,水资源主要依靠当地自然降水和永定河、潮白河上游的水 [10] 。

Figure 1. Map of the administrative divisions of Beijing
图1. 北京市行政区划图
2.3. 遥感数据获取
由于地理空间数据云平台的数据比较丰富,且语言为中文,下载数据容易操作,故本次实验选用地理空间数据云平台下载的landsat8遥感影像,其中空间分辨率为m,轨道号为123-32,时间为2013年2月25日,云量为2.31%。其他数据有北京市的县区矢量边界。注意下载时要注意选取的遥感影像的云量较小(主要是研究区域的云量要尽可能小),防止云量太多影响地面植被信息的提取;另外成像时间要尽量控制在6~10月,因为该时间段的植被生长茂盛,植被覆盖较高,且影像的色彩丰富,纹理层次清晰,高质量的遥感影像能够为数据正确地处理和分析提供保障 [11] 。原始影像如图2所示:

Figure 2. Original image of Landsat8
图2. Landsat8原始影像
2.4. 遥感数据处理
2.4.1. 图像裁剪
图像裁剪的目的是去除遥感影像中研究区域外的部分,分为规则裁剪和不规则裁剪。本文采用不规则裁剪的方法,利用北京市的矢量数据对landsat-8原始数据进行裁剪,精确获得北京市的遥感数据,并减少了数据量,可以加快后边辐射定标,大气校正等步骤的处理速度。裁剪结果见图3。
2.4.2. 辐射定标
辐射定标目的在于消除太阳角度和位置、薄雾等大气条件引起的影像失真问题,从而保证图像的质量,为后期遥感影像的识别判读和分类打好基础。采用ENVI提供的Radiometric Calibration工具进行辐射定标,在Output Interleave选项中可选择一个定标后的影像元栅格文件输出存储的格式。其中,BSQ格式(按影像元的波段顺序存储)可以提供最佳的影像元空间波谱处理的能力,BIP格式(按影像元的波段顺序与影像元波段行的交叉顺序存储)为影像元提供了最佳的影像元波谱行交叉处理的能力,而BIP或BIL格式(按影像元波段行的交叉顺序存储)则应该是一种介于影像元空间波谱处理和影像元波谱行交叉处理之间的一种折中存储的格式。注意此处选取输出栅格文件格式为BIL或BIP格式,其不仅提供了最佳影像元波谱行交叉处理的能力,而且为下一步的FLAASH大气校正做数据准备,辐射定标结果见图4。
2.4.3. 大气校正
FLAASH大气校正工具(FLAASH Atmospheric Correction)采用MODTRAN4 + 辐射传输模型对单波段或多波段影像逐像元地进行大气分子和气溶胶等大气粒子散射校正。MODTRAN4 + 辐射亮度传输参数计算模型不仅能够支持许多类型的辐射传感器,且由于该算法的精度高;它直接通过传感器图像像元的辐射光谱和化学特征来实时估计成像地区大气的辐射亮度属性,不需要依赖于大气传感器成像时需实时计算和测量传感器成像地区的大气辐射亮度参数获得的数据 [12] 。采用FLAASH大气校正工具对TM/ETM + 影像进行大气校正时应注意输入的像元值类型(辐射亮度单位转换)、文件类型(必须为BIP或BIL存储结构)以及正确设置文件输入输出路径和正确输入相应参数。大气校正的目的在于削弱,消除大气分子对地物的反射和气溶胶散射等的影响,保证遥感信息提取和参数反演的精度。大气校正的结果见图5。
3. 像元二分模型
党中央、国务院非常重视中国的地理国情,但要做好这一基本国情的工作,就必须对地理条件进行普查。如果要做好地理条件的普查,要从最基础最重要的植被覆盖度开始。本研究选择的区域是北京,要得到该地区的植被覆盖度,需要从以下步骤开始:首先计算NDVI,基于像元二分法模型将二者结合起来,根据已有的研究区土地类型分布图制作掩膜文件,最后通过反演估算该地区的植被覆盖度 [13] 。整个过程相对来说比较简单,但也有难点,比如在像元二分法模型中分析两种NDVI,即植被完全覆盖的NDVI和裸土所在的NDVI。像元二分法模型与NDVI植被指数相结合,在实际应用中取得了良好的效果。从基本原理来说,像素二分法模型实际上是用一个临界点作为分割线,这个临界点就是分类样本的光谱范围。例如,假设一个区域由分类样本的方差形成。这时候我们只需要判断终端像素是落在范围内还是已经超出范围,分配终端像素即可。最后经过比较,就可以得出各个类别的概率。设植被覆盖区域信息为,非植被覆盖区域信息为,则混合像元的信息可分解为两部分,用公式表达为。
(1)
设混合像元中植被覆盖区和裸土覆盖区所占面积比例为SC和
,完全的植被覆盖的纯像元信息为
,完全的裸土覆盖的纯像元信息为
,将植被覆盖区域在混合像元中贡献的信息
表示为:
(2)
将裸土覆盖区域在混合像元中贡献的信息
表示为:
(3)
结合
,得
(4)
(5)
通过上述公式转换,对于混合像元的信息量可用下式表示:
(6)
其中
表示植被覆盖度,G表示像元所反映的信息总量,
表示像元中植被部分所占像元覆盖的遥感信息量,
表示裸土部分所占像元覆盖的遥感信息量。
在不断的研究过程中,我们发现遥感测量植被覆盖度的方法有很多,但最合适、最简单的方法是利用常用的植被指数NDVI来近似估计植被覆盖度。这个模型中最重要的两个参数文件是NDVIsoil和NDVIveg (由不同地类直方图NDVI的阈值计算得来)。根据这个模型,我们可以得到两个假设。第一个假设是,当研究区域内VFC的最大值和VFC的最小值分别为100%和0%时,可以得到研究区域内NDVI的最大值和最小值。在这个过程中会有各种干扰,所以这个NDVI的最大值和最小值也在一定范围内,这个值的范围可以根据照片的实际情况来确定;然而,第二个假设与第一个假设有很大不同。其前提条件是必须有实测数据的支持,用实测数据的极值来近似代替VFC极值,这两个实测数据对应的照片的NDVI值就是最大NDVI值和最小值。虽然像素二分法模型是一种广泛使用的简单的植被覆盖度估计方法,但包括方法在内的任何事物都有其好的一面和坏的一面。像素二分法模型也是如此。在我们获得的NDVI图像中,由于某些原因,像素值可能不在−1到1之间,会出现很多异常像素。如果按照这个图计算NDVI的最大值和最小值,就找不到对应的极值。在实践中,很难获得一定的值,所以我们通常用理论上相似的值来代替。
4. 研究区域植被覆盖度估算
4.1. 归一化植被指数NDVI
归一化植被指数通常是指遥感影像数据中近红外波段(植物强烈反射的波段)和红光波段(植物吸收的波段)反射值的差与近红外波段和红光波段反射值的和的比值 [11] 。计算公式如下:
(7)
其中NIR指近红外波段的像素值,Red指红波段的像素值。近红外波段和红波段是Landsat系列卫星必不可少的波段,健康的植被反射更多的近红外和绿光,吸收更多的红光和蓝光,因此近红外和绿光对植被的反射进行加强,这也很好地解释了我们平时眼睛看到的植被大多为绿色。NDVI的范围始终在−1到1之间,会随着近红外通道和红光通道反射率的高低而变化,且每种植被类型的土地覆盖没有明显的界限。NDVI指数是分析人员检验植被生长状态好坏时最常用的标准指标,通常NDVI的值越高,植被就越健康;NDVI的值较低时,说明植被覆盖比较低或几乎没有植被覆盖。通常NDVI输出负值表明该区域根据云、水、雪等地物生成;NDVI的值接近于零说明该区域主要有岩石、裸土等构成;NDVI的值较低说明该区域比较贫瘠,由沙石、岩石等构成;NDVI的值比较适中说明该区域由灌木层和草地构成;NDVI的值较高表示该地区有热带雨林或温带雨林。目前NDVI广泛应用于干旱监测、农业生产预测和监测等。对选择的三幅遥感影像进行预处理后,在ENVI软件中运用Transform工具中的NDVI模块计算获取三期遥感影像的NDVI值,遥感影像因受云层、气溶胶等大气影响会形成噪声点,所获取的NDVI值可能会出现极大或极小的异常值,NDVI正常取值范围应在−1~1之间 [1] 。
4.2. NDVI的提取流程
在此之前,我们已经对得到的数据进行了预处理,数据的预处理将有助于我们更方便、更顺利地执行以下操作。估算植被覆盖的第一步是计算NDVI并计算每种地物类型的NDVI。打开ENVI软件,选择要操作的文件,也就是我们操作之前完成的大气校正的结果图。NDVI计算的步骤相对简单。在右边的工具箱里输入“NDVI”打开它,选择之前做的flaash大气校正的结果。我们需要注意以下操作,因为传感器的信息类型在多次操作后会丢失,并且只有一个海岸线波段,所以我们需要将以下波段从NDVI波段手动更改为4和5,此处先不考虑传感器的类型,如图6所示。
输入刚做好的NDVI,首先要先处理一下NDVI的异常值(即超出−1到1范围内的值),利用波段运算工具,输入公式,该公式的意思是筛选出NDVI中大于−1且小于1的值,让小于−1的NDVI的值变为0,让大于1的NDVI的值变为1,b1对应NDVI文件,得到去除异常值的NDVI。得到去除异常值的NDVI结果图,如图7所示。
经大量研究结果证明,NDVI与植被覆盖度之间存在较高的拟合度,但往往不能直接用NDVI来代替植被覆盖度,还需要进行一系列的操作步骤。因此本文利用归一化植被指数和像元二分模型共同计算北京市的植被覆盖度,将NDVI代入像元二分模型中得
(8)
其中NDVIveg代表完全被植被覆盖部分区域的NDVI值,NDVIsoil代表完全被裸土覆盖部分区域的NDVI值,理论上NDVIsoil值大小接近于0,NDVIveg值大小接近于0,但在实际工作中现实往往不是如此,由于植被在不同时期的长势不同,且受自然和人为活动的影响,该植被邻近区域的地物类型也可能不同,导致该植被像元的邻近像元会有差异,所以NDVI的值要根据研究区的实际情况来选择。
我们需要用到已有的土地类型分类图来统计不同的地物类型NDVI的最大值和最小值,选择掩膜文件中的土地类型分类图在ENVI软件中打开,得到北京市的“土地类型分类图”,如图8所示。
该土地类型分类图一共有5个类别,分别是:林地、农用地、城市用地、水体和其他。由于这5种类型的土地类型分别对应了5个掩膜文件,因此我们需要用它们相对应的掩膜文件来统计与之对应的NDVI的阈值。制作掩膜文件有两个途径,分别为ENVI中的Build mask和Apply mack两种工具,由于Build mask工具操作较简便且制作效果较好,因此我们采用Build mask工具来制作掩膜。打开build mask面板,选择土地类型分类图,点击options,直接的输入Data Range。
由于给定的土地类型分类图中林地、农用地、城市用地、水体、其他分别对应的类别值为1、2、3、4、5。所以数据范围中1到1对应的是林地,根据此范围生成林地的掩膜文件,并以此类推,得到其他类型对应的掩膜文件。由于我们统一认定水体里植被很少或基本不存在植被,所以将水体的NDVI值设为0。

Figure 8. Classification map of land types in Beijing
图8. 北京土地类型分类图
原理是这里面的分类类别值为1的是林地,所以我们就用Data Range1到1的这个范围就生成林地的掩膜文件,这个过程类似于密度分割。按照相同的方法2到2是农用地,3到3是城市用地,4到4是水体,5到5是其他。这里面水体可以不用做掩膜文件,因为我们都普遍认为水里面没有植被存在,所以认为水体的NDVI为0可以不用统计。其中林地掩膜如图9所示。
进行不同类别置信区间的统计,用到ENVI中的compute statistics统计工具,依次选择之前做好的去除异常值的NDVI和不同类型对应的掩膜文件,其中林地的统计直方图如图10所示。
我们之前使用的置信区间是5%到95%,但是在直方图中我们发现像元个数达到五位数,意味着它有一个量级突变。因此当像元个数从四位数变为五位数和五位数变为四位数时,我们都需要记录此时相对应的值,即这种地物类型的最小和最大NDVI。以此类推,农业用地、城市用地和其他地类的直方图的阈值都用同样的方法计算。将波段与相应的参数文件对应好之后输出得到北京市的植被覆盖度文件,如图11所示。
要先处理一下植被覆盖度的异常值(即超出0到1范围内的值),因为0对应无植被覆盖,1对应百分百植被覆盖,研究区域的植被覆盖只可能在这个范围内,利用波段运算工具,输入公式,该公式的意思是筛选出植被覆盖度的值中大于0且小于1的值,让小于0的植被覆盖度的值变为0,让大于1的植被覆盖度的值变为1,b1对应北京的植被覆盖度文件,得到去除异常值的北京市植被覆盖度,如图12所示。

Figure 12. Removing outliers of Beijing vegetation cover
图12. 二维滤波后的频谱信息
在修正异常值的北京市植被覆盖度图像基础上按照不同的区间范围进行密度分割,用到的是ENVI中的New Raster Color Slice工具,同时对每个区间的颜色进行修改,由于研究的是植被情况,这里颜色设置为由浅绿到深绿,如图13所示。
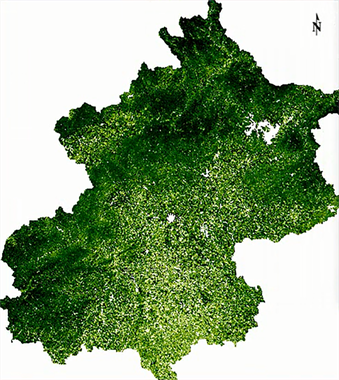
Figure 14. Vegetation cover density segmentation plot
图14. 植被覆盖度密度分割图
由图14可以看出北京市整个区域植被覆盖较高尤其是北京市的北部和西南部区域,主要包括延庆县、怀柔县、密云县,门头沟区和房山区,这些多山区和郊区。中南部和东南部的植被覆盖度比较小,因为北京市主城区在中南部,这部分区域经济发达,且没有大片的山区,因而植被覆盖较少。图中密云水库、怀柔水库、金海湖及一些河流附近区域密度分割等级极低,显示白色,进一步验证了水体的植被覆盖极少或几乎没有的假设。目前核实植被覆盖度的方法主要是野外实地测量,主要内容是:用数码相机从与地面垂直的角度拍摄,通过GPS定位找到图像上对应位置的像素,将其植被覆盖度与实际测量的植被覆盖度进行比较验证,得到对比结果。为了获得准确的结果,照片之间的间隙变形应该减少。室外的地方一般是90 × 90米大小,在选定的地方要按一定顺序均匀拍照。
本次研究的主题是利用归一化植被指数(NDVI)为主要参数并基于像元二分法模型来反演北京市的植被覆盖度。从修正后的北京植被覆盖度密度分割图来看,中心区植被覆盖度相对小于四周边缘区,且植被覆盖度的水陆差异明显(湖泊、河流区域植被覆盖度极低),说明本研究课题的反演估算结果与北京市的实际地表植被覆盖没有太大差异,表明该方法取得了很好的效果。并且该方法不需要复杂的设计和计算,非常简单,易于操作,而且可以应用于不同分辨率的遥感数据
5. 结论
植被覆盖度是反映区域生态系统环境变化重要指标,本研究主要探讨了利用Landsat8数据并基于像元二分模型和NDVI来反演北京地区的植被覆盖度,本文北京的遥感影像计算出归一化植被指数NDVI并修正,根据土地类型分布数据制作不同地类的掩膜,进一步反演出植被覆盖度,与北京野外实测的植被覆盖情况基于行政区划和河流水系分布图进行分析验证,结果表明,反演的植被盖度与实地测量的植被覆盖度吻合较好,可以进行下一步研究。同时也存在一些问题需要进一步探讨:遥感图像中有很多云量和薄雾,可以使用同态滤波方法来降低云的影响,但对于如何消除这些影响值得进一步探讨。不同的土地利用类型对模型参数NDVIveg和NDVIsoil的置信区间可能有不同的要求。
从修正后的北京植被覆盖度密度分割图来看,中心区植被覆盖度相对小于四周边缘区,且植被覆盖度的水陆差异明显(湖泊、河流区域植被覆盖度极低),说明本研究课题的反演估算结果与北京市的实际地表植被覆盖没有太大差异,表明该模型对于本研究的适用性,也说明该方法取得了很好的效果。该方法不需要复杂的设计和计算,易于操作,且可以应用于不同分辨率的遥感数据,因此在以后关于某地区植被覆盖度的反演研究中,可以多采用此类方法。