1. 引言
随着我国经济生产总值的提升,人均GDP也得到显著提高,一户一车已经成为普遍现象,据公安部统计,2021年我国汽车保有量达3.02亿辆 [1] 。但是汽车使用数量上升的同时也引发了更多的交通事故,据估计,90%的车祸是由人为失误造成的 [2] 。面对复杂多变的道路状况,传统汽车驾驶需要驾驶员时刻保持警惕,观察到变幻莫测的周围环境,针对环境变化判断并规划出合适路线且做出相应的驾驶操作。但是疲劳驾驶、阴雨天气、陡峭崎岖的山路等特殊交通情况都会影响驾驶员的判断,这就为事故和危险的发生提供了可能性。相比之下,自动驾驶汽车的优势就显而易见了,与人为产生的失误不同,它可以进行自主判断,而且注意力会长时间保持较高的水平。同时,自动驾驶汽车能更好地节能减排、减少污染 [3] ,应用前景一片光明。自动驾驶汽车在面对复杂的交通状况时,需要对交通车辆、路过的行人、交通标志、交通信号灯以及路面车道标识等做出准确的判断。保证汽车安全自动驾驶的关键是对目标的精准检测和识别,从而做出最优判断。本文将展开讲述YOLO算法在自动驾驶领域的应用,并对如何进一步提升自动驾驶汽车检测的MAP和FPS进行总结与展望。
2. 评价指标
学习目标检测算法,首先要知道有哪些评价指标。最主要的衡量指标有精确度、召回率、AP、MAP、交并比及FPS,其中,前4个用来衡量分类精度,交并比(intersection over union, IoU)用来量化真实和预测边界框之间的交叠率关系,最后,FPS (frames per second)用来衡量运行速度。
2.1. 分类精度的衡量指标
目标预测有正例和负例两种,预测情况分为真阳性(True Positives, TP)、假阳性(False Positives, FP)、假阴性(False Negatives,FN)和真阴性(True Positives, TN)。
1) 精确度也称为阳性预测值,是指全部被检测出的样本中是正确样本的概率。
2) 准确度是指全部预测中预测正确的概率。
3) 召回率是指全部正样本中被正确预测出来的概率。
通常情况下,精确度与召回率呈负相关。PR曲线是通过精确度和召回率计算绘制的,其中x轴表示召回率,y轴表示精确度,可以直观反映算法性能,其理想点是接近(1.0, 1.0)。
4) AP由P-R曲线和x、y轴围成的面积组成,面积与检测效果成正比。它用来表示召回率下检测的平均正确性。
5) MAP是所有AP的平均值,对数据集中所有的对象类别进行计算,数值越高,效果越好。
。交并比用来衡量真实和预测边界框之间的交叠率关系,是真实框与预测框的交集对并集做比值得到的。预测效果最好时该数值达到1。
。
2.2. 运行速度的衡量指标
FPS用来衡量运行速度,即每秒可以处理多少张图像,图像张数越多表明速度越快,效果越好。
3. 目标检测算法
目标检测的发展经历了两个阶段:“传统目标检测阶段(2014年前)”和“基于深度学习的检测阶段(2014年后)” [4] 。基于深度学习的目标检测方法分为两类:两阶段检测方法和单阶段检测方法 [5] 。
3.1. 两阶段目标检测算法
2013年Sermanet等人 [6] 提出了OverFeat算法。OverFeat算法在当时非常出名,它基于AlexNet [7] 实现了识别、定位、检测共用同一个网络框架。使用了卷积神经网络的方法,利用特征提取,分类提取到的特征再次应用到定位检测中,该算法为深度学习奠定了基础。但是有一些弊端,如:面对小目标检测实验时,精准度不高,而且很容易出错。接下来的一年诞生的R-CNN使用“Region Proposal (候选框) + CNN”提取的分类网络组合方式解决了前面存在的问题。两阶段目标检测算法应运而生。该目标检测算法将目标检测分为候选区域的选取和目标的分类识别两部分。所以它的优点也就显而易见了,能实现精准的定位和检测,然而,也正因为分为了两阶段,所以检测速度较慢。下面介绍R-CNN和Faster R-CNN两种两阶段目标检测算法。
3.1.1. R-CNN系列基础框架的发展史
Girshick等人在2014年提出R-CNN [8] 算法,该算法为后面的研究奠定了基础。R-CNN的提出 [9] 相比于传统的方法具有一定的优势,主要表现在它采用了选择性搜索算法提取候选区域,极大地减小了候选区域的数量,降低了网络计算量。并且,大幅度的提高了目标检测的准确度和速度。R-CNN目标检测算法可以分成四步:第一步,利用选择性搜索算法SS (Selective Search) [10] 从图像中提取约2100个候选框。第二步,计算卷积特征,提取各候选框的函数向量。第三步,分类候选框,用AlexNet将各个函数向量发送给各个向量机(SVM),判断是否属于此类。第四步,使用非极大值抑制算法并进行边界框回归来获得候选的最佳框。该算法有效的提高了精确度,但R-CNN也有一定缺陷,由于它需要对2000个候选框进行特征提取,需要占用大量的内存空间,提取特征时会消耗更多的时间,并且,由于它是分两个阶段进行目标检测,每个阶段一一训练也会延长训练时间,此外,提取特征时会进行大量的重复计算,这些都会导致出现检测速度慢的问题。针对此问题,He等人在2015年提出了SPP-Net [11] 算法,提升了检测速度。R-CNN网络结构图及整体流程图分别如图1、图2所示。
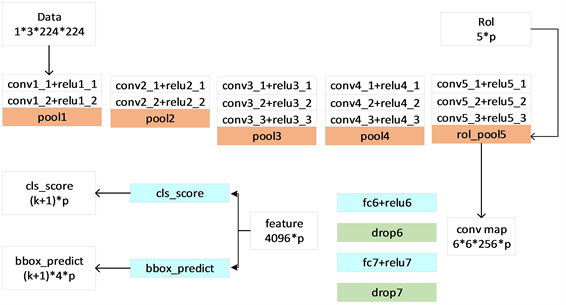
Figure 1. R-CNN network structure diagram
图1. R-CNN网络结构图
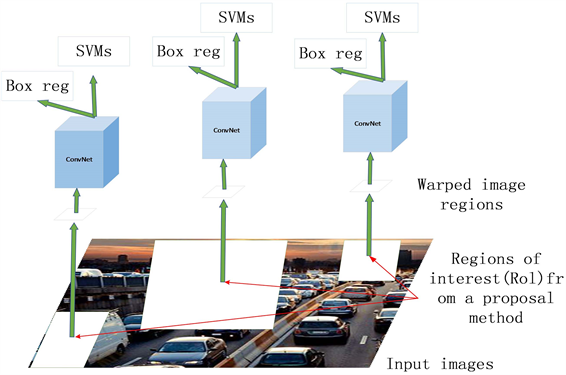
Figure 2. Overall flow chart of R-CNN
图2. R-CNN整体流程图
3.1.2. Faster R-CNN
继2014年Girshick等人提出R-CNN之后,Ross Girshick在第二年推出了Fast R-CNN,这一算法相比于之前的R-CNN,它的训练时间大幅度减少,速度明显提升,从八十四小时减少为九点五小时,同时测试时间也降低了很多,而对准确率几乎没有影响。由此可见,Faster R-CNN结构更精巧,流程更紧密,速度更快。Faster R-CNN没有使用传统的检测方法,而是采用RPN直接生成检测框的方式。所以,检测速度得到有效提升,这也成为它的显著优势。此外,Faster R-CNN采用的是非极大值抑制方法,这种方法可以优化候选框。并且相比之前的算法,该算法的最大的区别是将候选区域和目标分类回归任务集合在一起进行,实现了端到端的连接,但是Faster R-CNN在小目标检测方面精度很低,针对自动驾驶汽车检测方面也存在严重漏检现象。
李学军 [12] 等对Faster R-CNN进行了改进,将scSE注意力分别嵌入到FPN网络、RPN网络以及ROI head网络中,采用控制变量法,骨干网络均使用Mobilenet V2 + FPN,在扩充后的TT100K数据集上探索嵌入位置影响。结合上述改进方法构成KB-Faster-RCNN,其map达到了91.8%,相比传统模型提高了21.3%。
3.2. 单阶段目标检测算法
3.2.1. YOLO系列目标检测算法
伴随着人工智能的普及 [13] ,目标检测也越来越火热,当下对目标检测在精度等方面的要求也越来越高,传统的目标检测方法已经不能满足工业需求和实际应用,进而诞生了新的目标检测算法-YOLO,YOLO从YOLOv1系列已经逐步迭代到目前最新的YOLOv8。本文将详细讲述YOLOv3、YOLOv7和YOLOv8。YOLO系列的发展史如图3所示。
YOLOv1算法是典型的单阶段目标检测算法 [14] 。它是单阶段检测算法的开端,这一系列算法相较于之前的双阶段目标检测算法速度有了很大提升,但是在检测小目标和密集目标时精度会下降很多。
YOLOv3 [15] 是由Joseph Redmon、Ali Farhadi二人提出,相比于YOLO之前的系列 [16] ,YOLOv3模型更复杂,但是可以通过对模型的结构和大小进行改进,从而达到提升算法精度和速度的目的。
此外,YOLOv3在小目标检测方面也有改进,该模型 [17] 主要分为Darknet-53卷积神经网络特征提取和特征图预测识别两大部分,前者用来提取图像中所包含的多类特征,能够给特征通道升维,获得更多的图像信息,并传输到不同大小的特征图进行预测。Darknet-53用改变卷积核步长的方式控制张量的维度,逐步达到尺寸降维、通道升维的目的。YOLOv3算法模型拥有接近五十的图像传速帧数和92.2%的map。Vehicle-YOLO [18] 拥有五种不同规格的特征图共同进行目标预测,而且图像规格较之前增加很多,定位也更准确,检测的平均精度高达96.6%,对大目标的检测则有更高的定位精度。降低了误判率。但是YOLOv3也存在不足之处,网络结构非常复杂且体系规模宏大,因此,对设备的要求较高。YOLOv4 [19] 沿用了YOLOv3的head部分,唯一的区别就是YOLOv4采用了经过PANet网络加强处理后的特征信息来进行结果预测,除此之外与YOLOv3是没有区别的。YOLOv4诞生的同年提出了YOLOv5,YOLOv5与现在流行的YOLOv8接近,所以,在这里不展开讲述YOLOv5。
YOLOv7算法诞生于2022年7月,YOLOv7 [20] 网络分为以下四部分:输入、主干、颈部和检测头,整体流程:第一,先对输入图像进行图像增强处理,调整图像大小,处理好图像后在进行特征提取。第二,对上述提取到的特征头部融合,得到不同尺寸的特征。第三,输出过程,将融合的结果传送至检测头,再进行输出。YOLOv7的主干网络包含着很多模块,如ELAN模块,这些都提高了网络的准确率。YOLOV7的优点有:1) 模型重参数化。2) 标签分配策略;YOLOV7的分配策略采用标签式,综合前面YOLOV5和YOLOX的一些匹配策略的一种新的分配策略。3) ELAN高效网络架构;YOLOV7的最新网络架构以高效为主。4) 带辅助头的训练;辅助头训练不仅不会延误推理过程需要花费的时间,而且能够提高精度。此外,YOLOV7引入了重参数化卷积、模型缩放等方法,可以优化目标特征的表达能力,其结构主要分为Input,Backbone,Neck,Head四个部分,YOLOV7网络结构图如图4所示。
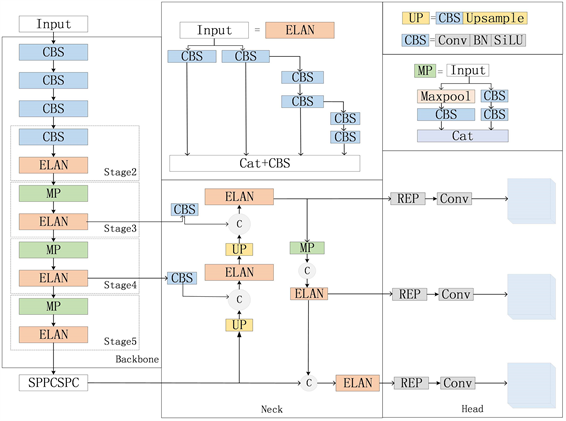
Figure 4. YOLOv7 network structure
图4. YOLOv7 网络结构图
胡淼 [21] 等对KITTI数据集进行检测,提出使用EIOU损失替换CIOU损失使模型实验检测精度提升0.4%。此外,还使用SPPFCSPC模块替换成SPPCSPC模块使模型实验检测精度提升2.2%。增加了BRA注意力机制的消融实验。综合了所有改进方法的优点,实验检测精度达到对比结果中的最高,实验检测精度结果为94.7%,相比于原始模型YOLOv7算法提升3.1%。
YOLOv8算法的核心延续了YOLOv5,也对应了 [22] N、S、M、L、X等不同尺度模型,可以应用到各个复杂场景中,且在精度上较之前的算法有了大幅度提升,而且安装更加方便,训练也更流畅。相比于前面的YOLOv7和YOLOv5,YOLOv8有更小的权重文件,仅仅只有6 MB,所以,可以非常方便的在嵌入式设备中使用,也能更快更好的满足实时检测需求。它的特性和改动可以归结为如下:提供了一个全新的SOTA模型,包括P5640和P6 1280分辨率的目标检测网络和基于YOLACT的实例分割模型。其中,缩放系数参考了YOLOv5提供了不同尺度模型。骨干网络和Neck参考了YOLOv7 ELAN的思想。YOLOv8算法更换成梯度流更丰富的C2f结构,调整了通道数,模型的性能有效提升。其中,改动最大的部分是Head部分,换成了解耦头的结构及Anchor-Free,分类与检测头分开,采用TaskAlignedAssigner正样本分配策略的Loss计算,引入YOLOX中的最后10epoch关闭Mosiac增强的操作,提升了精度。整体更偏向于工程实践。YOLOV8n模型结构图如图5所示。
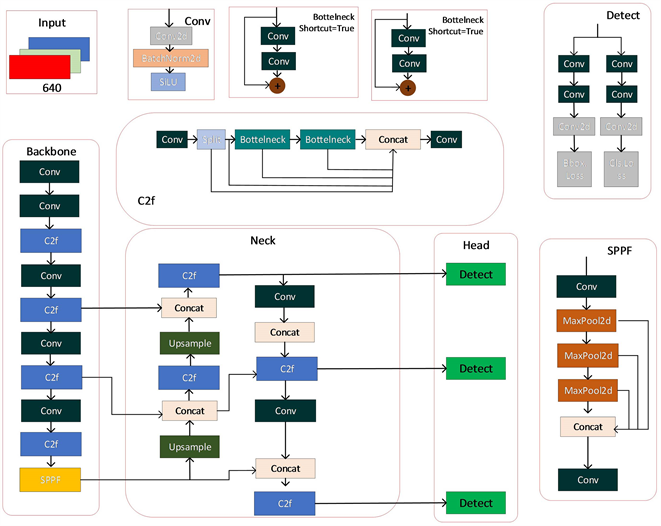
Figure 5. YOLOv8n model structure diagram
图5. YOLOv8n 模型结构图
熊恩杰 [23] 等提出Ghost-YOLOv8算法,对TT100K数据集进行了目标检测。在他们的实验中添加了小目标检测层的模型相比原始的YOLOv8n模型,Precision、Recall、mAP@0.5分别提高了7.4%、2.2%;添加了GAM注意力机制和轻量化模型。
3.2.2. SSD算法
Wei Liu等在2016年提出了SSD这种目标检测算法,用SSD输入一张图像,可以达到输出多个位置信息和类别信息的效果,该待检测图像到达SSD后,网络会输出一个多维矩阵,对这个多维的矩阵进行处理就能得到标签信息及位置信息等,一般使用非极大值抑制处理的方法对矩阵进行处理。
4. YOLO算法在自动驾驶中的应用
基于深度学习的YOLO系列算法越来越热门,在多个领域中得到广泛应用,本文主要讲述在自动驾驶领域的应用。在自动驾驶的场景中,需要对交通情况,例如:交通标志、交通灯、行人识别、交通车辆等方面进行检测,此时YOLO算法的优势显而易见,YOLO算法具有更快的速度和更高的精确度等特点,对其改进可以更好的应用于自动驾驶的复杂多变的情景中。
4.1. 交通标志的检测
在日常驾驶的交通情景中,交通标志的识别与检测准确度对驾驶员及自动驾驶有着至关重要的作用。
朱宁可等 [24] 自制中国多类交通标志数据集CMTSD,提出改进Yolov5算法。通过将Mobilenetv3中的倒残差结构的升维度去除降低参数量,再使用输入输出同一通道分离卷积去提取特征,替换轻量级上采样通用算子,降低信息损失,最后融合注意力,最终检测精度提升了2.58%,检测速度提升7.41帧。
刘海斌等 [25] 提出了一种改进方法,使用YOLOV5-S并改进,对实时交通标志进行检测,通过构建目标长范围来捕获位置,是算法聚焦于重点特征,在网络中融合轻量级卷积技术GSConv,降低模型的计算量。增加新的小目标检测层,提升小尺寸标志检测效果。最终mAP@0.5提升到88.1%,检测速度达到83FPS。
石镇岳等 [26] 提出一种基于注意力机制的交通标志检测模型YOLOv7-PC。通过K-means++聚类算法对交通标志的整个数据集进行聚类,获得适用于检测交通标志的锚框;其次引入坐标注意力机制;最后引入空洞空间金字塔化,既保证了小目标分辨率,又进一步扩大卷积的感受野。最终达到mAP提升5.22%、召回率提高9.01%的效果。
在使用YOLO算法对交通标志进行目标检测的过程中,改进的方法常常有很多,最为常见的有下面这几种方式:1) 扩展更新或者自己制作数据集。2) 运用倒残差结构的升维度去除降低参数量,文献 [24] 将Mobilenetv3中的倒残差结构的升维度去除降低参数量。3) 添加注意力机制,文献 [26] 引入坐标注意力机制。4) 添加常见的模块,如:SPP模块,或者添加池化层等,结合空间金字塔池化,在最大池化层中得到最优特征。
4.2. 交通灯的检测
交通灯作为整个驾驶过程中需要注意的关键信息,对其进行精准的目标检测显得尤为重要。
钱伍等 [27] 提出了一种改进YOLOV5的交通灯检测方法,运用复合数据对交通灯输入模型进行增强操作,设计多尺度代替固定尺度训练,建立多尺度检测层。此外,运用远跳链接传送信息,该方法对小目标检测特别友好,最终改进的mAP增加了6.5%。
李江天等 [28] 对大型车辆遮挡驾驶员视线的问题进行了研究,构建了一种共享系统,该系统是基于YOLO创建,用于实时监测路口交通灯信息车辆。在基于YOLO V3的交通灯识别模型的基础上又开发了基于YOLO Lite的轻量化模型,该模型可以较流畅地运行于CPUi5-750之上,并证明了方案实施效果较好。
孙迎春等 [29] 做出了一种基于YOLOv3的交通灯检测,能够解决该算法在检测时漏检的问题,运用了K-means算法对数据集进行聚类处理,简化了YOLOv3的网络结构,解决了召回率低的问题,最后,在损失函数中,利用高斯分布特性评估边界框的准确性,改进后的YOLOv3检测结果的fps可达30 frame/s,精准度也提升了9%。
4.3. 行人识别的检测
在自动驾驶的研究领域中,行人识别检测也是一项非常重要的研究任务。行人检测主要是判断是否有行人存在并研究对于行人小尺寸和遮挡的问题。
Xu等 [30] 替换了YOLOv5中的C3模块,添加了Grey-C3模块,并且添加了新的探测头,相较于YOLOv5s模型检测行人的准确率增加了2.6%。
Hsu等 [31] 提出比例和尺度感应的YOLO算法,解决了行人所占比例小,尺寸小的问题,此外还引入了ratio-aware注意力机制,精简了网络结构,引入SPP模块等进行多尺度特征融合。解决了原模型遮挡行人导致检测准确率低的问题。
Li等 [32] 提出一种运用轻量级特征提取网络对YOLOv7算法进行改进的方法,摒弃原有的YOLOv7骨干部分的网络,挑选出MobileNet这种网络结构作为骨干,并设计高分辨率特征金字塔结构和基于注意力机制的检测头,其mAP达到89.75%,比原YOLOv7算法提高了9.5%。
刘丽等 [33] 也引入SPP网络增强多尺度特征融合,但是她是基于YOLOv3网络结构去改进的,改进后的结构更加简单,对行人检测的精度更高。
Li等 [34] 设计了一种空间金字塔卷积洗牌模块,可以提取被遮挡物体可见像素中的精细信息带有该模块的YOLO检测器在遮挡行人时检测的准确率高达94.11%。
4.4. 交通车辆的检测
随着交通工具越来越多样化,交通压力与日俱增,对不同的交通工具行驶的道路进行了限制,分为了机动车和非机动车道路,这就需要我们对车辆类型做出检测。
周勇等 [35] 以YOLOv5目标检测器为依托,对道路交通场景下的车辆进行目标检测实现车辆识别,同时利用DeepSORT目标跟踪算法对检测到的目标车辆进行跟踪,通过特征识别网络实现跟踪目标的ID跟随,以防止重复报警。最后,在高速公路的真实视频中进行了算法测试,识别准确率可达到78.4%。
杨志军等 [36] 提出改进型YOLOv4-Tiny交通车辆图像实时检测模型。首先改进模型CSPResNet和空间金字塔池化(Spatial Pyramid Pooling, SPP),减少模型的计算量;其次改进特征金字塔网络(Feature Pyramid Network, FPN)及使用池化特征增强方法,增加少量计算量,获取模型的多尺度特征图提升精度。最终,模型mAP提升了4.67%,检测速度提升了2.5FPS,模型大小减少了52.74%。
王承梅等 [37] 提出一种基于YOLOv5算法的轻量化车辆视觉检测方法,可用于边缘计算平台的构建。算法方面添加卷积块注意力机制模块,融入到骨干网络结构中,提高模型特征提取能力,有效克服收敛慢、迭代次数多的问题。最后,通过公开数据集进行对比实验,验证了设计方法在关键指标方面有所提升,并通过搭载边缘计算平台完成在自建数据集实拍道路场景的有效性测试。
叶佳林等 [38] 提出一种基于YOLOv3的非机动车漏检的研究,他创设了一种特征融合的特殊结构,并且添加了GIOU损失函数,最终,解决了非机动车漏检的问题,提高了检测精度及准确率。
Zhou等 [39] 提出一种基于YOLOv2算法的车辆目标检测方法,运用了深度融合的方式对车辆进行识别。其中,是将摄像机拍摄到的信息与毫米波雷达获得的信息进行深度融合的。最终,提升了车辆识别的准确率。
Takahashi等 [40] 做出了一种轻量级目标检测器,是基于YOLOv3进行改进的,对YOLOv3的网络结构进行修改,从2D扩展到3D,此外,在深度方向也有输出信息,可以检测到被遮挡目标,提升了检测精度。
5. 总结与展望
在自动驾驶领域最广泛应用的算法是YOLO算法,对YOLO算法的改进都是采用增加注意力机制、修改网络结构参数、设计模块、运用损失函数及特征增强等方法。其实YOLO算法可以与其它算法相结合使用如Transformer算法;或者使用其他技术如领域自适应、强化学习等。同时,YOLO等目标检测算法在小物体、遮挡、实时性等方面还有待提高。在采集交通标志时存在数据采集不够清晰,标注有残缺和遗漏的问题,对于三种交通灯中的某一种数据集采集样本过小,影响了检测的准确度。对车辆和行人等的检测,改进方法单一,仅采用了更改网络结构和损失函数的方法。虽然后面也尝试了很多方法改进,但仍存在一定的局限。同时,现阶段YOLO系列的算法持续在更新,目前有越来越多的新的版本,需要进一步从不同角度运用YOLO算法对自动驾驶车辆进行研究。提出实用性高的 [41] 量化指标,对自动驾驶的数据集进行优化,并加强训练,使其能更好的模仿驾驶员驾驶场景。此外,可以使用弱监督目标检测 [42] 。目前的检测算法大部分是需要进行大量的数据集标注的,数据集的建立会消耗很多时间和人工成本,因此,可以运用弱监督目标检测,或者是无监督和混合监督目标检测等方法去进行检测,在使用少量及大量未标注的数据进行检测时,目标检测的研究将更具有挑战性。
项目基金
天津市科委科技计划项目(20YDTPJC01110)和天津市大学生创新创业计划训练项目(202210066064)。
NOTES
*通讯作者。