1. 引言
在Web 2.0/3.0时代,社交媒体获得了前所未有的发展,“互动”是图像等社交多媒体最重要的传播特征和要求,用户常常自由地给予这些Web图像共享的文本社交标签(社会化标签) [1] 或者用户评论。这样的多媒体内容已经大量地出现在人们的日常生活中,所以亟须有效的检索方法帮助人们寻找到目标多媒体内容。Web图像往往伴随着若干个文本标签,它们是由图像用户即兴给定的关键字或者文本描述符,可能部分或者间接地描述了图像的内容,是带有高噪音的弱语义信息,存在着语义表达不完整、语义错误、语义歧义、语义重复等问题,所以其不同于由专业人士给出的强语义标注或者类标签。一个直截了当的图像检索方法是直接在图像社交标签上执行图像检索,然而图像社交标签往往在语义上是高噪音的,并且可能并不会直接地与图像内容有关联,从而导致较低的图像检索性能。如图1所示,在测试图像I中存在一些带下划线的社交标签例如“remember_dreams_come_true”和“bravo”并没有直接描述该图像I的视觉内容,而训练图像的社交标签例如“Houston”和“Barco”仅部分描述了图像内容。虽然这些噪音文本社交标签不适宜直接用于图像查询概念,但是可以把它们看作是额外的、有价值的低层文本特征即文本模态数据以用于图像的监督学习。
对于在线图像检索,传统的单模态方法要么仅使用了图像模态数据 [2] ,要么仅使用了文本模态数据 [3] 。由于文本模态数据例如社会化标签可以用来增强多概念图像检索的性能,因此一些多模态跨模态检索方法 [4] 研究了图像与文本等多个模态数据之间的关联以提升图像检索的性能。然而,这些传统的方法聚焦于基于单概念的图像检索而较少考虑多概念语义场景图像检索场景,这限制了其应用范围,因为用户使用检索系统的时候往往提交多概念的语义场景检索请求。为了处理语义场景图像检索,传统方法在单概念检索系统上执行多概念语义场景检索任务,这在一些场景中可能是低效的,这是因为多概念场景有其独特的视觉外观特性,这难以仅仅依靠单概念分类器去识别。于是,进一步研究语义场景图像检索有用且有必要。
近年来,卷积神经网络(CNNs) [5] 作为一种重要的深度学习技术已广泛应用于基于单概念的图像检索。CNNs占据了很多检索测试基线的排行榜,这表明通过CNNs学习到的深度特征能较好表征图像的内部结构。因此,考虑使用深度学习技术去提升语义场景图像检索的性能。我们提出的方法SSIR整合了两类分类器:1) 多概念场景分类器(有助于整体场景识别);2) 单概念目标分类器(有助于单概念识别)。从实
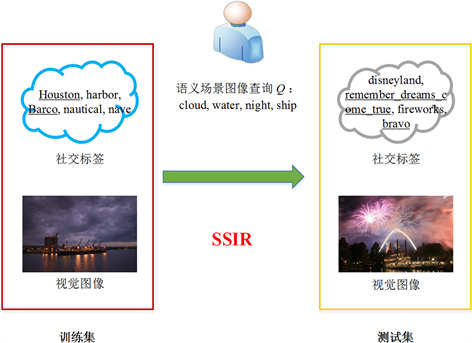
Figure 1. The graphical illustration of semantic scene image retrieval
图1. 语义场景图像检索示例图
验结果看,这种设计能显著提高分类器对多概念语义场景的判断识别能力。具体来说,首先,设计一个多模态CNN以识别多概念语义场景。每个CNN分为卷积块层与全连接分类器层。学习时,图像(视觉模态)与关联文本(文本模态)被分别送入各自模态的卷积块层与全连接分类器层。全连接分类器层包含两类分类器,即适合单概念识别的单概念目标分类器以及有助于整体场景识别的多概念场景分类器。第二,语义概念之间的依赖关系被用来计算概念的语义分数,以进一步增强分类器的判断识别能力。假若一个概念c与其关联概念们以较高的频率共现在图像集中,一旦发现关联概念们频繁出现,c的预测分数值将被提高。最后,通过融合运算,SSIR方法整合了视觉模态和文本模态的预测分数值。为改善对稀疏概念的检索性能,应用梯度下降算法来补偿在真实应用中不平衡图像集上语义概念的频率差。
2. 基于多模态深度学习的语义场景图像检索
2.1. 问题描述
设多模态图像训练集为
,多模态图像测试集为U。每个图像文本对
或者
表示一幅图像及其关联的若干个弱语义文本标签,分别由低层视觉特征和低层文本特征组成。给定一个包含有K个不同语义单概念的强语义单词表
,其中每一个语义概念
是一个语义单概念(例如“rainbow”或者“wedding”)。在训练集L中的每幅图像被标注若干个语义单概念ci,而测试集U中的图像没有任何强语义标注。每个语义场景多概念
是V的幂集中的一个元素即
或者
,其中k是Ci的长度即
。给定一个多概念语义场景查询
和带强语义标注的训练集L以及未标注图像测试集U,目标是寻找包含所有t个目标单概念的最相关图像
。
2.2. 系统框架
SSIR检索框架如图2所示,包含3个部分:卷积块层、分类器层、在线检索。卷积块层学习出两类特征:深度视觉特征与深度文本特征。通过视觉卷积块层,将图像像素转换为视觉特征向量;通过文本卷积块层,将关联的文本社交标签转换为词嵌入 [6] ,然后学习出文本特征向量。分类器层学习出从特征到概念的映射函数,包含两种分类器:单概念目标分类器和多概念场景分类器。这里,需要生成多概念单词表V*。由于V*中的概念分为语义单概念和场景多概念两类,所以共有四类映射函数:单概念视觉映射函数、多概念视觉映射函数、单概念文本映射函数、多概念文本映射函数。在线检索根据给定的多概念语义场景查询Q从测试集中检索到最相关的图像结果。由于要使用多概念之间的语义依赖关系,因此需要生成查询上下文Rrc(Q)。
每个多概念
可视为单个抽象场景概念Ci,也可视为k个分离的单概念ci。对于多概念单词表V*的生成,为避免产生无意义的语义概念排列组合,SSIR模型基于训练集L上的共现规则选择出有场景语境的多概念Ci用以生成一个强语义多概念单词表V*:
(1)
(2)
其中
表示所有k个语义概念ci在训练集L中的共现总数,即多概念频率。如果集合V*太大,可以控制共现阈值s以减少训练开销。
2.3. 多模态CNN结构
任何CNN网络都可融入我们的检索模型,不失一般性,我们选择了近年来一个有影响力的高效CNN模型ResNet [7] 来作为我们的视觉模态CNN分类器。由于传统CNN分类器网络聚焦于单概念分类,而我们的语义场景检索任务是一个多概念分类任务,因此为ResNet模型定义了一个新的多概念softmax损失函数使之适应多概念语义场景检索任务。首先,第i张图片I与第j个概念
的归一化关联概率可定义为:
(3)
其中,
是图像I在第j个概念Cj的离散概率分布,它由ResNet分类器产生。为最小化ResNet预测概率与真实概率的KL距离,我们使用如下场景多概念softmax损失函数:
(4)
其中,
是一个图片I的指示器函数:当概念Cj在图片I中存在则
否则
;N是图像总数。传统的单概念CNN基本结构为卷积块层后接分类器层。卷积块层学习出深度特征,而分类器层执行从I到Cj的映射,识别出语义概念Cj。我们设计的SSIR场景检索模型包含两类分类器:单概念分类器和多概念场景分类器。当
时,Cj为一个传统的单概念;当
时,Cj为一个场景多概念,其作为一个整体概念参加学习。
对于文本CNN网络,很多适合自然语言处理的CNN网络都可融入我们的场景检索模型,不失一般性,我们选择了一个有影响力的高效CNN模型SentenceCNN [8] 作为我们的文本模态CNN分类器。为训练SentenceCNN,将一副图像所有的文本标签视为一个输入语句加以学习。类似视觉模态CNN分类器,修改分类器层,增加一种多概念场景分类器,于是,文本模态CNN分类器也包含两类分类器:单概念分类器和多概念场景分类器。
2.4. 语义场景查询上下文Rrc(Q)的生成
首先生成语义邻居集
,通过选择出概率p(Q|Ci) > 0的邻居概念Ci,这个对称的语义概率p(Q|Ci)表示两个概念Q和Ci之间的相关性,它可以基于多模态图像训练集L如下定义:
(5)
其中Nr(Q)与Nr(Ci)表示多概念Q与Ci的共现频率,Nr(Q, Ci)表示同时包含有两个概念Q与Ci的图像数,每一个多概念Ci被看做是自己的语义邻居并且服从约束条件p(Ci|Ci) = 1。
其次,选择出所有的查询零件
到集合Rrc(Q)。最后从剩余的语义概念中选择出最相关的r个概念Cr到集合Rrc(Q),于是包含Krc个元素的查询上下文Rrc(Q)就生成了。后续实验中,在验证集上将Krc试验取值范围为2~20执行交叉验证,发现当设置Krc = 8时性能最佳,因此Krc = 8作为后续实验的默认值。为了保持语义相关性的概率属性,语义关联概率p(Q|Ci)被如下归一化:
(6)
2.5. 多模态场景语义映射
对于查询概念Q,上述Krc个有语义相关性的元素
联合参与未标注多模态图像文本对(I, T)的相关性计算,输出相关性估值
:
(7)
(8)
(9)
其中,r(Q, I)和r(Q, T)分别表示图像I和文本T各自模态关于查询概念Q的相关性估值;
和
分别表示CNN单概念分类器和CNN多概念分类器输出的单模态相关性估值;
是SSIR场景检索方法的待优化参数,且服从约束条件:
。公式(7)体现了多模态预测数据的后期融合,公式(8)与(9)体现了单概念分类器与多概念场景分类器预测数据的后期融合。
和
相关性估值的计算如下,体现了SSIR场景检索方法对于语义相关性的利用。
(10)
(11)
(12)
(13)
其中,后验概率p(Ci|I)和p(Ci|T)经由视觉CNN多概念分类器和文本CNN多概念分类器计算;语义相关性p(Q|Cr)可以看做是后验概率p(Ci|I)和p(Ci|T)的权重。
2.6. SSIR参数估算
为找出较好的参数
,使用在训练数据上的极大对数似然函数方法。令
表示语义场景多概念Q是否出现在多模态图像数据
中,相关性预测值p(yQi)如下给出:
(14)
(15)
(16)
因此,检索概念Q的对数似然函数被如下改写:
(17)
其中nQi是正反例数目N+和N−的不平衡性惩罚因子。假若yQi = 1,设置nQi = 1/N+;否则,nQi = 1/N−。将公式(17)中的p(yQi)项用公式(14)到(16)替换,可以获得下列对数似然函数:
(18)
其中,
通过梯度下降法 [9] 最大化对数似然函数LQ求出
优化值。
3. 实验和评价
3.1. 数据集
评价实验采用了公开数据集MIR Flickr 2011 [10] 。它包含有18,000张图像,每张图像含有3~26个标注,单词表V含有99个语义概念。每个图像I与其关联的文本标签T组成了多模态图像,即图像文本对(I, T)。采用随机抽样,8000张图像作为训练集,余下10,000张图像作为测试集,约70%概念频率低于平均概念频率。很明显,这是非平衡图像数据集,增大了场景识别难度。当一幅图像I包含Q中所有的单概念ci时,则I是相关的,否则I是不相关的。采用平均准确率均值(MAP)分数作为性能评价指标,所有指标值越高表示场景检索性能越好。
3.2. 实验结果与分析
由于MIR Flickr 2011数据集中的概念最高频数是11,因此设定公式(1)的参数t = 11。s控制计算V*的计算开销,经验设置s = 200。于是,V*含有15,970个场景多概念。为测试语义场景检索性能,我们构建了检索测试集Q*:所有的单概念
加入Q*;随机生成500个双概念场景查询;随机生成500个三概念场景查询;随机生成500个四概念场景查询。这样,Q*共计包含1599个语义场景查询。
表1列出了与最新图像标注方法的对比实验结果。对于被比较的传统单概念检索方法,采用公式(10)和(12)计算语义多概念估值。

Table 1. Performance comparisons of semantic scene image retrieval
表1. 语义场景图像检索性能比较
从该表中可见,我们的SSIR方法超越了其他对比方法,获得了更好的场景检索性能。与表中最好的对比检索方法GResNets比较,提出的SSIR方法的全部场景概念MAP提高了13%。一方面,多概念场景分类器有助于识别语义场景,另一方面,概念间语义依赖关联性更能准确判断多概念形成的语义场景,缓解误判率。在图像检索任务中,这两种类型的相关性都提供了有用的信息,具有一定的互补性,从这个角度上说我们的SSIR方法可提高图像检索的性能。此外,应用梯度下降算法来补偿在真实应用中不平衡图像集上语义概念的频率差,缓解了稀疏场景概念的误判率,所以,在不平衡数据集MIR Flickr 2011上,我们的SSIR方法具有更好的场景检索效果。
基金项目
2019年广东第二师范学院校级教学质量与教学改革工程项目(编号:2019jxgg18);广东第二师范学院软件工程重点学科建设项目(编号:9030-1700207);广东省自然科学基金项目(编号:2018A0303130169);广东省科技计划项目(编号:粤财农[2017]94号,2016A010106007);广东省应用型科技研发专项资金资助项目(编号:2016B090927010);2019年广东第二师范学院大学生创新创业训练计划项目(编号:201914278146)。