1. 概述
自动驾驶中对环境的感知是个技术难关,并且与道路、设施以及其它交通参与者的协调存在困难 [1]。其中需要准确快速地识别交通信号灯,但实际的交通环境信息复杂多变以及天气等因素的影响使得对交信号灯的识别难度大大增加,这给行车安全造成了安全隐患。孙学聪用形状和色彩来识别交通信号灯但模型简单,不能在复杂情况下进行准确识别 [2];田谨等人采用亮度分割和几何形态滤波对交通信号灯进行定位,但其对于信号灯区域面积过小的图像检测错误率较高且算法耗时 [3];潘卫国等人用FasterRCNN框架实现了对交通信号灯的识别,但其识别速率达不到实时性要求 [4]。本文使用了基于RCNN的基础上发展出来的SSD算法在交通信号灯识别方面的应用。提出了基于SSD的检测方法,在其基础上添加了特征融合的方法,使得SSD对小物体的检测能力提高,同时在不大幅增加计算量的情况下使之可以实现实时检测识别,保证了实时性与准确性。
2. PyTorch深度学习框架
PyTorch用计算图来对神经网络具体实现形式的描述,包括每一个数据Tensor及Tensor直接的函数function。计算图构建方法如图1所示。
在图1中,x、ω和b都是用户自己创建的,因此都为叶节点,ω,x首先经过乘法算子产生中间节点y,然后与b经过加法算法产生最终输出z,并作为根节点。而且PyTorch是自动求导,其梯度计算遵循链式求导法则,简化了编程的环节,更注重网络框架结构。与其他框架不同的是PyTorch的计算图是动态的,动态图是指程序运行时,每次前向传播时从头开始构建计算图,这样不同前向传播有不同的计算图,不需要事先把所有的图都构建出来,并且可以很方便的查看计算过程中的中间变量。在进行网络初始化,节点参数的跟新,权重偏移量的更新采用反向传播的方法。每次选取小批量数据进行迭代计算,不仅减少了计算资源的浪费更加快了迭代的速度。反向传播优化流程图见图2。
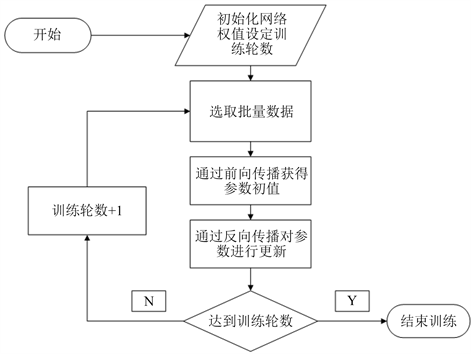
Figure 2. Neural network back propagation optimization process
图2. 神经网络反向传播优化过程
3. 交通信号灯的识别方法
本文提出的交通信号灯识别方法主要对数据图像的预处理,数据的增强,网络结构的搭建和反卷积模块的搭建。
3.1. 图像预处理
为了提升数据集的多样性,满足训练的实际要求以及对小物体的识别度。总体上包括光学变换与几何变换两个过程 [5] 见图3。光学变换是对亮度和对比度进行调整,可以改变像素值的大小但不对尺寸进行更改;几何变换是对图像进行扩展,裁剪和镜像的操作,先进行尺度上的变化在进行去均值的操作。所有操作过程都是随机的,目的是尽可能的保证数据的丰富性。
3.1.1. 光学变换
首先是亮度的调节,以0.5概率进行对图中每一个点加一个实数,实数范围取[−32,32]。然后是对比度,色相与饱和度随机调整,色相是随机加一个数而对比度与饱和度是随机的乘一个数。光学变换最后一项是增加光照的噪声,具体做法是随机交换RGB三个通道的值。
3.1.2. 几何变换
在几何变换中首先是对原图像进行随机扩展,扩展比例可以取[1,4]之间。
随机扩展之后进行随机裁剪见图4,随机裁剪的好处是可以滤掉不包含明显真实物体的图像,同时丰富看训练集尤其对于物体遮挡的情况。而镜像基本是对图像进行左右翻转。最后一步为了使输入为特定大小的图像,对图像进行固定缩放。最后一步是对图像进行去均值的处理。部分代码如下:
class SubtractMeans(object):
def _init_(self,mean):
self.mean = np.array(mean, dtype=np.floa32)
def _call_(self, image, boxes=None,labels=None)
image = image.astype(np.float32)
image -= self.mean
return image.astype(np.float32),boxes,labels
3.2. 网络架构
总框架搭建
首先是基于VGGNet为基础,使用VGGNet网络结构对图像进行特征的提取。总框架结构图见图5。
VGGNet采用了五组卷积层和三个全连接层,最后使用Softmax做分类。每次经过池化层后特征图的尺寸减小一倍,而通道数增加一倍。
本文构建的VGGNet卷积神经网络主要由五种结构组成:
1) 输入层。输入层是整个神经网络的输入,在处理图像的卷积神经网络中,它一般代表了一张图片的像素矩阵 [6]。在输入层可以对较小的数据集进行数据增强,包括光学变换与几何变换等,极大限度地扩充了数据集的丰富性,从而有效的提升了模型的精度。
2) 卷积层。卷积层是整个网络最重要的部分,对图像进行特征提取,卷积核的大小通常有3 × 3和5 × 5,卷积核越大运算量越大但精度会有所提高。VGG16相比AlexNet中使用的卷积核基本都是3 × 3,这种结构优点在于首先从感受野来看,两个3 × 3的卷积核的感受野与一个5 × 5卷积核的感受野相同但参数量更少。更为重要的是两个3 × 3卷积核可以使用两个激活函数,使其非线性能力大大增强,可大大提高网络的学习能力。
3) 池化层。神经网络池化可分为最大池化和均值池化,其首要作用是下采样,降维去除冗余信息,对特征进行压缩,简化网络的复杂度。其次可以扩大感受野以及实现非线性。
4) 全连接层。在经过之前卷积层池化层的数据处理后,将所有参数经过三个全连接层展开成为1维张量,便于Softmax函数进行分类 [7]。
5) Softmax层。该层主要用于分类问题。通过softmax层,可以得到当前样例属于不同种类的概率。
与Faster RCNN的Anchor类似SSD是采用PriorBox来进行区域生成,以固定大小宽高的PiorBox来进行对感兴趣的区域搜索,而本文交通信号灯的识别PiorBox可以集中在图片的中上区域。PiorBox图见图6。为了最优的选择尺度和高宽比,采用一种平铺的方法,对每个默认边框尺度进行计算:
(1)
其中k的取值为1,2,3,4,5,6分别与SSD中第4,7,8,9,10,11个卷积层。为了得到正确的边框预测值,还需进行匹配与损失计算,保证每一个框都有一定的Recall率。将IoU值大于0.7的视为正样本;IoU值小于0.3的视为负样本,为了防止过拟合将正负样本比例维持在1:3附近。
(2)
偏移值的计算根据下列公式:
(3)
(4)
(5)
(6)
定位损失和loss值的定义
本文使用了smooth函数作为定位损失函数且只对正样本进行计算。smooth函数表达式如下:
(7)
其总体目标损失函数是位置损失与置信度损失的加权和:
(8)
(9)
(10)
(11)
SSD特征融合
将深层与浅层的每一个元素在对应位置相乘,在上述说明中k取六个值,将这六个值之后的特征图保留,进行融合处理,再将融合结果传递给后续分类与回归网络。

Figure 7. DSSD network structure diagram
图7. DSSD网络结构图
下分支为VGGNet网络结构图,上分支是一个反卷积模块,深层特征图
经过反卷积使之大小与浅层特征图
一致。两者进行逐元素相乘最后经过ReLU模块得到最终所融合的特征图。见图7。
3.3. 模型训练与预测结果
模型优化方法采用SGD随机梯度下降算法,又称最速下降算法,是在无约束条件下计算连续可微函数极小值的基本方法。最后经过softmax函数进行伪概率分类,其表达式如下:
(12)
通过模型的搭建之后加载Nxear红绿灯数据集使之模型准确率达到86%。但在对雨天夜晚是由于环境因素干扰大,无法达到准确的预测和分类。在此可以添加辅助设备如可转动摄像头,进行角度变动使提高预测结果。
4. 结语
本文构建了SSD的卷积神经网络图像识别方法,尝试了由SSD基础上加入特征融合的方式对交通信号灯进行分类预测,由输入层、卷积层、池化层、全连接层构成,准确率还有提升的空间,为了提高准确率可以采用随机森林的思想训练多种模型,然后取其均值或者对数据集进行扩充。其次不同数据集在同种模型下表现不同,数据量大的数据集可以使模型有着较充分的学习,使之提高准确率。本文尝试了将SSD与特征融合的方法应用于交通信号灯的识别上,之后可以进行网络压缩来进一步缩小网络模型的大小,使之更方便运用于移动端。