1. 引言
在传统的基于RGB图像或者灰度图像的物体识别研究中,通常对图像提取各种人工定义的特征,例如HOG特征 [1] [2]、LBP特征 [3]、SIFT特征 [4]、Haar-like特征 [5] [6] 等。这些特征提取的方法只能在特定的识别任务下才能取得一定的效果,鲁棒性并不高。人工定义的特征只代表了图像特征的一部分,更多有效的、鉴别能力强的特征被忽略了。比如SIFT特征对特征点构造128维的向量,如果图像没有足够多的纹理将会造成误匹配或者是没有办法匹配,此外,SIFT特征完全忽略了色彩信息。对于光照变化不均匀的图像,LBP特征无法稳定提取,基于LBP特征的物体识别方法表现不佳。基于神经网络与深度学习的特征提取避免了人工定义的特征提取,通过神经网络可以提取到更有鉴别能力的特征。
传统的物体识别通常基于RGB图像,随着深度学习的深入研究,基于RGB图像的物体识别已经取得重要进展。在一些特定的应用场合,比如室内机器人或工业流水线上的物体识别任务中,使用RGB-D相机采集图像,除了在每个像素点获取RGB值之外,还能获得该像素点的深度值。深度值含有新的信息,有望为物体识别提供更多有用的特征。Kevin Lai等来自美国华盛顿大学的研究学者通过对于RGB-D图像的多年的研究,建立了一个具有多分类、多角度的RGB-D物体数据库 [7]。在国内,来自宁波大学的卢良峰等人提出的基于原始图像层 [8] 进行融合得到RGB-D物体的特征进行RGB-D物体识别。在2015年由来自合肥工业大学的胡良梅,杨慧等人 [9] 提出的通过多核学习以及自适应加权的方法进行3D目标识别方法。2018年同样来自合肥工业大学的张治安等人提出基于稀疏联结卷积递归神经网络的RGB-D图像识别算法 [10]。随着对于RGB-D物体的识别的研究,基于多模态深度学习的RGB-D物体识别等方法相继被提出。尽管近年来深度学习算法得到了广泛的研究,但是它们仍是主要基于RGB图像和灰度图像的研究,RGB颜色和深度数据属于多模态数据,RGB特征和深度特征的提取以及特征融合方法还没有得到充分的研究。本文主要研究了基于深度学习的RGB-D识别算法框架,以及RGB特征和深度特征的提取和融合方法。
2. RGB-D物体识别中的深度神经网络
ResNet卷积神经网络网络结构
ResNet网络 [11] 是在2015年由何凯明、张翔宇和任少卿共同提出的,该网络是基于VGG-19网络进行的改进,因为随着VGG网络深度的增加,会出现梯度爆炸或者梯度消失的问题,而ResNet网络的出现使得这个问题迎刃而解,并还减少了参数的数量。ResNet提出了一个全新的思想,假设需要涉及到一个网络层且存在最优化的网络层次结构,那么大多时候所设计出的深层次网络的很多层实际上是冗余层。如果冗余层的网络层可以完成恒等映射,能够保证所有经过这些恒等层的输入输出完全相同。ResNet网络由Building Block结构组成。Building Block结构使用了一个残差支路和一个Short Connection支路。
大量实验证明,残差网络的确解决了退化的问题,在训练集和测试集上都是网络层数越多,错误率越小。图1为两种残差网络层数不同的对比,其中横坐标指迭代的次数,纵坐标指错误率。在具有18层和34层残差网络的ResNet上,随着迭代次数的逐次增加,可以看到具有残差网络层数越多的ResNet发生错误率越小。

Figure 1. ResNet error rate trend graph [11]
图1. ResNet错误率趋势图 [11]
3. 基于ResNet的RGB-D物体识别算法
3.1. 算法流程
本文所提出的基于深度学习的RGB-D图像识别算法的基本思路是,分别使用两个ResNet网络实现对RGB特征和深度特征的提取,通过特征融合算法进行RGB特征和深度特征的融合,最终通过softmax分类器进行分类。算法的总体流程图如图2所示。
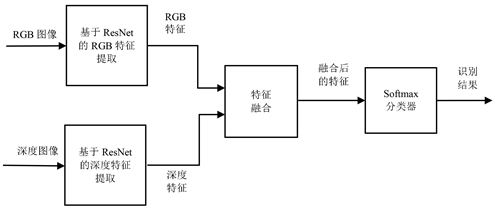
Figure 2. Overall flow chart of RGB-D object recognition algorithm based on ResNet
图2. 基于ResNet的RGB-D物体识别算法总体流程图
3.2. RGB特征提取
基于ResNet的RGB-D物体识别算法中提取RGB特征和深度特征的流程图如图3所示。
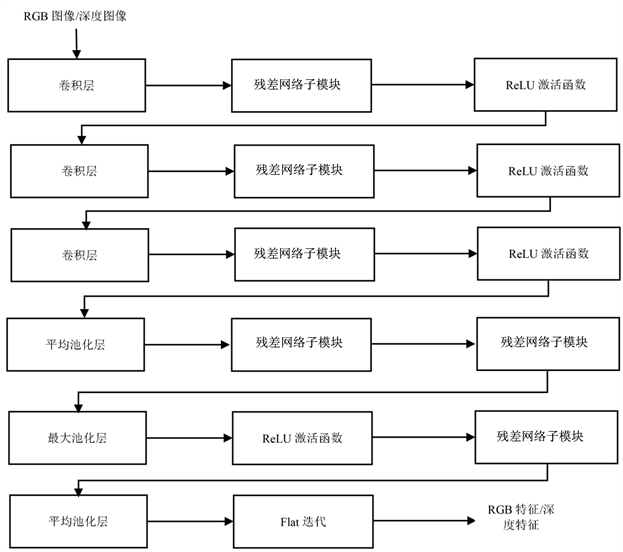
Figure 3. RGB features/depth features extraction flow chart
图3. RGB特征/深度特征提取流程图
要提取到RGB特征需要将RGB图像数据输入到ResNet中得到,首先在卷积层中对输入的图像做2D卷积,其中要将图像数据进行升维,为了能够最大程度上的提取到特征数目并且做一个线性变换,降低参数的数量,其数学公式如表达式(1)所示。
(1)
其中,N意为Batch Size,C意为Channels。
RGB图像数据通过卷积层经过升维后,提取到的特征数目是众多的,之后进入到残差网络子模块中,残差网络子模块流程图如图3所示,即输入到三层残差网络,分别为1 × 1、3 × 3、1 × 1卷积,经过了先降维在升维的操作,相当于对特征值进行了二次筛选,去掉了部分没有区别力的RGB特征,再次减少了参数的数量而且不会出现退化的现象,另外错误率亦大大的降低了,再通过ReLU函数的激活,因为线性模型的表达能力是远远不够的,其原因是如果输入和输出都是线性组合的话,其效果和没有隐藏层是一样的结果,无论网络叠加多少层数,其结果不过是矩阵相乘,故经过ReLU函数的激活从线性变为非线性可以将特征保留并能够映射出来,即将每个节点的输入映射到输出端。
ReLU函数的表达式为:
(2)
由表达式(2)所示,激活函数ReLU的本质是取最大值,当输入的值是负数的时候,节点不会被激活,故输出的值为0,这说明了在同一时间内只有部分的节点被激活,所以网络会变得很稀疏,进而使得计算变得更加有效率。RGB图像数据在经过重复多次的卷积层和残差网络子模块以及ReLU的激活后,其中提取到的RGB特征值进入到MaxPooling进行最大池化作用于RGB图像中的不重合区域,使RGB特征能够保持平移、旋转以及尺度的不变性和增大感受野的范围,MaxPooling的作用如图4所示。
通过相同的多个特征提取和ReLU函数以及最大池化层,图像进入到平均池化层进行特征提取,可以减小邻域大小受限后直接造成的估计值的方差值,从而能够更多的保留图像的重要信息,随后进行flat迭代,是为对RGB图像的特征的扁平化排序的处理,使得其RGB特征能够便于更快地索引随后输出,至此完成RGB特征提取。
3.3. 深度特征提取
要提取到深度特征需要将深度图像数据输入到ResNet中得到,其具体的流程与RGB特征通过将RGB图像数据输入到ResNet中提取相似,流程图如图3所示。其不同点在于将深度图像输入到卷积层的时候,有N个卷积层可以去进行循环的卷积,进行循环的卷积可以充分地提取到深度特征,有利于之后的物体识别的准确率的提升。从N个卷积层输出后,依次输入到与RGB特征提取的相同的多个残差网络子模块、ReLU函数、最大池化层以及平均池化层和flat迭代进行特征提取。
当上一层的输出作为输入进入残差网络子模块时,首先进行下采样,采用下采样的作用主要是经过处理之后让图像变得符合一定的大小并且可以成为物体所对应的图像的缩略图,而且还可以相应的减少计算量。下采样的原理是对于一幅像素大小为A*B的图像,对该图像进行C倍的下采样,下采样过后得到的图像的像素大小为(A/C)*(B/C),该步骤中最重要的一点是C必须要为A和B的公约数。另外当图像以矩阵的形式呈现时,即为把最初的图像C*C大小的窗口内的图像变成一个像素点,且该像素点的值的大小与C*C窗口内所有像素的平均值相等。所以,经过下采样后,应该输出的为RGB图像或者深度图像的一个小的缩略图。该输出进而经过平均池化层进行RGB图像或者深度图像的平均特征值的提取和卷积层的对于RGB图像或者深度图像的特征值的再卷积之后输入到残差网络的1 × 1、3 × 3、1 × 1三层卷积,先降维再升维对特征值进行二次筛选,去掉部分没有区别力的RGB特征,再减少了参数的数量而且不会出现退化的现象之后再进行空洞卷积。空洞卷积的作用是在不做池化的情况下保持信息的完整不再损失和扩大了其感受野的面积,使得每次卷积之后的输出都可以含有大范围的信息,从而可以简洁的提高RGB-D物体的图像的识别的准确率。另外通过查阅文献中的理论知识可以复现出一个7 × 7的卷积层,其的正则等效于3个3 × 3卷积层还可以大幅度的减少参数的设置。
经过残差网络子模块时内部详细流程图如图5所示。
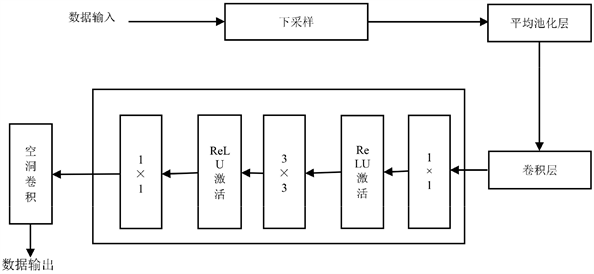
Figure 5. Detailed internal flowchart when passing through the residual network
图5. 经过残差网络子模块时内部详细流程图
3.4. RGB特征和深度特征融合
RGB特征和深度特征融合流程图如图6所示。在对RGB特征和深度特征进行融合时,首先通过决策树算法将融合网络参数初始化,对提取的RGB特征和深度特征所输入的网络赋予不同的参数,这些参数确定了RGB特征和深度特征在融合时的比例系数,反映了两种特征对分类结果的影响权重。然后选择最大池化法提取更有效的RGB-D特征,再经过softmax分类器进行分类,获得RGB-D物体的识别结果。
采用决策树算法的原因是,决策树算法具有较高的分类精度,而且生成的模式简单,其数学表达公式如表达式(3)所示。
(3)
由表达式(3)条件熵表达式可知,在知道X值时可以有效的减少Y值的不确定性,从而有效地提高分类的准确率。
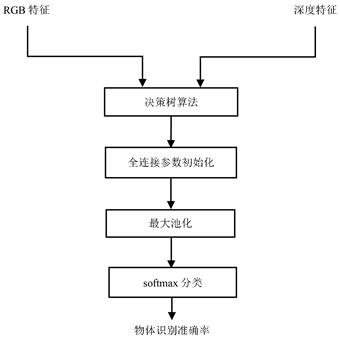
Figure 6. Flowchart of feature fusion of RGB and depth features in the image layer
图6. RGB特征和深度特征在图像层进行特征融合流程图
4. 实验结果及分析
4.1. 基于2D3D数据库的实验结果及分析
为了验证本文算法的有效性,采用与文献 [7] 相同的实验过程,在2D3D数据库 [12] 上进行了实验。在每一次实验中,随机的按照7:3的比例将2D3D数据库分为训练集和测试集两部分。最终确定的训练集为110个实例,约为4200张图片,测试集为46个实例,约为1800张图片。此次实验共计重复50次,2D3D数据库在每一次实验中都会被随机切割,最终的实验结果为50次实验结果的平均值。
表1将本文算法和其它典型算法在2D3D数据库进行物体识别的准确率进行对比。本文提出的基于ResNet的RGB-D物体识别算法取得了较好的识别率,对比实验证明,本文算法能较好地实现RGB特征和深度特征的提取与融合。

Table 1. Accuracy results and comparison of various algorithms for object recognition (%)
表1. 多种算法物体识别的准确率结果和对比(%)
4.2. 基于RGB-D数据库的实验结果及分析
采用与4.1节相同的实验过程,对本文算法在华盛顿大学RGB-D数据集上进行了物体识别实验。最终确定的训练集为210个实例,约为3000张图片,测试集为90个实例,约为12,000张图片。此次实验共计重复50次,RGB-D数据库在每一次实验中都会被随机切割,最终的实验结果为50次实验结果的平均值。
表2将本文中提出的基于ResNet的RGB-D物体识别算法和其它典型算法进行了对比。本文的算法取得了较好的分类效果,证明了基于ResNet的RGB特征与深度特征提取和融合方法对于RGB-D物体识别是有效的。
Table 2. Various algorithms based on RGB-D dataset object recognition accuracy results (%)
表2. 多种算法基于RGB-D数据库的物体识别的准确率结果(%)
以上通过分别将RGB-D数据集和2D3D数据集输入到基于ResNet的RGB-D物体识别算法来测试得到算法的准确率,经实验证明,空洞卷积的引入使得RGB-D物体识别率提高了0.7%~1.2%。经分析,空洞卷积之所有能有效提高识别率,在于它可以使神经元的感受野变大,从而在特征提取时能提取到更全面、有效的特征。
5. 结论
本文给出了一种基于ResNet的RGB-D物体识别算法,利用ResNet从RGB图像和深度图像中提取有效的特征,并采用了决策树算法和全连接方式将RGB特征和深度特征进行融合;为了提高特征提取的有效性,在残差网络子模块中引入了空洞卷积。实验结果表明,该算法在RGB-D物体识别的准确率方面取得了较好的效果。将来需要对网络结构和特征融合方法进一步优化,以进一步提高识别正确率。
基金项目
徐州市科技计划项目(KC17078)。
NOTES
*通讯作者。