1. 引言
随着我国物联网、5G、区块链 [1]、新基建 [2]、数据湖 [3] 和大数据技术的发展,据IDC (International Data Corporation)预测全球数据圈2025年将增至175 ZB (1泽字节相当于1万亿GB),接近于2018年33 ZB的5.3倍 [4],并且到2025年我国将成为数据量最大的区域,如今的经济高度依赖数据,并且随着各公司在其供应链 [5] 的每一步都对数据进行采集、编目和利用,对数据的依赖在未来只会不断加强。
目前数据采集主要来自于自身内部数据,或者网上数据也就是网络爬虫,自身内部的数据我们无法改变,但在互联网上人们几乎可以获取任何想要的数据,从互联网上获取数据一般分为从网页上获取数据或者通过数据API (Application Programming Interface,应用程序编程接口) [6] 获取数据,与网页爬虫不同的是,数据API的设计更为简单高效,这个接口已经存储好大家所需要的数据,不需要再花过多的精力去解析网页。并且网页数据爬取往往会对服务器造成压力,如果代码没有设置好合理的类人的网页浏览频率,会有IP被封的风险 [7]。目前,API接口支持以下数据格式XLSX、JSON、XML、CSV、RDF等,在本文中选择了一种易于读写并广泛应用于Web的轻量级数据格式JSON,它可以被快速、高效地解析,也易于存储。
获取到API接口先不用忙着怎么去将数据采集下来,可以先对API接口的服务文档、响应示例、并发数、响应时间等进行分析,这些准备工作对大量API接口数据的采集是非常有必要的。服务文档可以帮助我们获取到网站的URL以及访问方式;响应示例可以看到接口响应的数据格式、内容、编码等;并发数可以看到API接口每秒并发运行的次数,接近这个次数网站就会预警,超过这个次数程序就会报错;接口响应时间是数据采集快慢的关键,虽然程序可以多线程或者多进程,但一次接口响应时间就花了近1秒,这个采集速度怎么能快呢!自动化测试的目的就是为了测试接口的响应时间,网上的API接口很多不会像“大厂”,比如百度API、阿里API、腾讯API、微博API那样规范稳定,而且接口响应速度还不会太快。百度API的单个响应接口速度可以达60 ms (1 s = 1000 ms)左右,多个线程一起跑响应速度成倍数下降,但像国家的政务查询接口,响应速度都在1秒左右,此速度是通过测试广东常住人口接口和国家企业信息接口而来,速度慢的原因应是数据量过大,查询费时多。
最优线程 [8] 是为了使数据采集速度达到最优化而加入的,既然API接口的响应速度无法改变,就通过运行多个线程变相地降低响应时间,但线程不能是无限增加的,所以计算出最优线程可以节约计算机的性能,还能使数据采集更加快。Python的简单,以及支持一系列的第三方库,使得Python在数据采集方面用途很广,但Python的速度慢,以及线程支持不友好,使得对有一定速度要求的数据采集接口变得不是很实用,而基于Java的ETL工具Kettle [9],可以自由调节线程数量,而且易于实现,故选择了它作为数据采集的工具,通过实验对比这两种数据采集的方式,可以看出基于Java的ETL工具Kettle采集速度更加快,还可以定时数据采集,本文提出的基于API接口的数据采集策略,符合常规的数据采集逻辑,而且数据采集快,易于发现数据采集中哪个环节出现问题。
2. 相关技术介绍
本文主要涉及到API接口、自动化接口测试、最优线程、Python、Kettle等技术,故在此进行一些介绍为后续的工作做好铺垫。
API是应用程序接口(Application Programming Interface)的简称,API是一些功能、定义或者协议的集合,提供应用程序或者程序开发人员基于软件访问一组例程的能力,对外封装完善,调用时无需学习API内部源码,依据API文档功能说明书来使用即可 [10]。针对API接口数据采集也是网络爬虫的一种,但从API中获取的数据格式更加规范,数据质量更加好,可以相对的避免复杂的数据清洗过程,随获随用,极大的节省时间,因为API设计的目的就是为了实现数据的共享,开放数据。
目前API接口支持XLSX、JSON、XML、CSV、RDF等数据格式,其中JSON和XML是主流的数据格式,几乎所有API接口都支持这两种数据格式,JSON (JavaScript Object Notation)是一种轻量级的数据交换格式,具有良好的可读和便于快速编写的特性,可在不同平台之间进行数据交换 [11]。XML是扩展标记语言(Extensible Markup Language),用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。JSON与XML相比是一种更加轻量级的数据格式,而且更加易于解析,支持多种语言,这使得JSON在大数据时代备受欢迎,而且随着应用程序和平台的不断发展,应用程序的功能变得越来越复杂,但为了保证用户体验的优化,需要通过重构代码,将复杂的逻辑封装在内部,保持其对外提供的API仍然简洁。JSON也正因为简洁这一优势逐渐超越了XML,成为了应用间的首选数据交换格式 [12]。
自动化接口测试是对接口测试的辅助手段,借助工具和测试用例达到模拟手工测试的效果,测试过程中无需人工干预 [13]。自动化接口测试,在很大程度上可以减轻测试人员的压力,大大提高了软件测试工作的效率。同时,避免了人为操作带来的失误,一定程度上提高了测试的准确性 [14]。在本文中自动化接口测试一方面是为了检测接口是否可用,另一方面是为了测试接口的响应速度,不同的API,由于性能和功能的不同响应速度相差很大,像类似于百度API的响应时间在60 ms左右,而像目前的政务信息资源共享的接口,目前响应速度在1 s以上,这个速度是通过多次测试广东常住人口接口和国家企业信息接口得来的,从省级接口和国家级接口采集数据的目的是为了完善某地市的自然人和法人库,使得数据可以互联互通互享,打破信息孤岛,使得人民群众,去政府办事真正做到只跑一次,提高政府的办事效率,真正的实现数字政府。
目前的自动化测试工具有很多,比如Postman、Appium、Selenium、QTP、Loadrunner、RobotFramework等,在本文中选择使用Postman作为接口自动化测试的工具,一是因为它提供功能强大的Web API和HTTP请求调试,二是因为开源,三是Postman可以很好的模拟并向API发送Request请求,接收API发回的Response,并可以自动生成Js函数对返回结果做断言,接口自动化测试实现比较容易。
通过接口自动化测试,可以知道API接口返回的数据内容以及格式,并且可以发现影响API数据采集快慢的关键,响应时间。接口的响应时间在数据采集时,接口就已经设定好了,采集方是不能进行修改,为了解决接口响应速度慢以及采集速度慢,引入了线程这个概念,本来采集时是一次采集一条,引入线程后一次可以采集多条,相当于成倍的缩短响应时间,进而提高采集的速度。通过设置多个线程可以加快采集速度,但过多的线程会造成阻塞和资源浪费,过少的线程达不到速度的优化,故需要计算采集的最佳线程 [15] 使得采集速度达到最佳,最佳线程计算公式如下:
(1)
指最佳线程数量,
指CPU的数量,
指线程等待时间,
指线程CPU时间。在平常的使用中用CPU的数量,即可达到较优的速度。
本文用到的采集工具是Python和Kettle,Python是目前最流行的爬虫语言,Python从本质上来说属于一种开源编程语言,其具有功能强大、语法简便、适用性良好等优势特性 [16]。Kettle是一款国外开源的ETL工具,使用图形界面进行可视化ETL操作,支持广泛的数据库类型与文本格式的输入与输出,同时支持定时和循环,具有跨平台、可拓展、可集成、高性能等优点 [17]。ETL是用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程 [18],本文创新性的用Kettle做数据采集工具,与Python编写的程序作对比,主要原因是Kettle数据采集相对简单,不需要复杂的代码进行调优,而且线程数量可控,采集比较稳定,如果采集的数据质量不好还能直接进行清洗,但在程序灵活度方面不如Python。
采集完成的数据需要进行保存以方便后续的使用,常用的保存格式有文本格式和数据库格式,文本格式主要有CSV、TXT、EXCEL,数据库格式又分为关系型数据库和非关系数据库(NoSQL),关系型数据库主要有MySQL、SQL server、Oracle等,非关系型数据库主要有MongoDB、Redis、Hbase等,因为采集下来的数据是JSON格式,选择非关系型数据库MongoDB,不需要解析JSON数据,直接存储进数据库里面,极大的方便了存储工作,而且MongoDB性能高效查询速度快,使用JSON风格进行存储易于理解和掌握。
上面是对本文用到的技术进行介绍,下面介绍具体的数据采集过程。
3. 数据采集思路及实现
3.1. 数据采集思路
好的数据采集思路,可以使目标明确,有条理,及时发现哪一步出现问题,有针对性的解决,本文设计如图1的数据采集思路流程图。
数据采集思路解释如下:
1) 确定API接口,根据需求确定采集的API接口,一般API接口都会有密钥或者发送方签名(appKey),这些在确定采集API接口的时候需要获取到,否则无法访问API接口。
2) 分析API接口文档,API接口文档会对API接口进行详细的介绍,包括请求参数、返回结果参数、服务状态和实例结果等,通过分析API接口文档,就可以对API接口有宏观的了解。
3) Postman单个接口测试,通过单个接口测试可以测试API是否可用,查看返回结果,除了返回结果还会返回状态码以及是否成功的信息,返回结果可以选择JSON、XML、HTML、TEXT等格式,默认是选择JSON格式,JSON格式简洁而且有着清晰的层次结构易于阅读。
4) 接口自动化测试,随机选择一批数据做接口自动化测试,并设定验证函数,以判断接口是否请求成功,导出自动化测试结果,在结果中可以看到接口访问成功数量以及每个接口的响应时间和接口的平均时间。
5) Python数据采集和Kettle数据采集,这是两种数据采集的方式,通过两种方式进行比较,选择较好的方式进行数据采集工作。
6) 确定最佳线程,在数据采集时,不使用线程数据采集相对较慢,使用线程可以使数据采集速度成倍的增加,但速度不能一直增加,在保持数据采集稳定以及占用资源相对合理的情况下,确定最佳的线程可以极大的提高采集的速度。
7) 存储到MongoDB,与其他数据库相比,比如MySQL,采集下来的JSON数据存到MySQL数据库里面,需要对JSON数据进行解析,获取相应的值存到MySQL数据库里面,而存到MongoDB就不需要对JSON数据进行解析,可以直接进行存储,极大的提高了存储效率还保持了JSON数据的层次结构。
3.2. 数据采集实现
主要从三个方面介绍数据采集的实现过程,分别是自动化测试、Python数据采集和Kettle数据采集,其中Python数据采集和Kettle数据采集是做对比实验。本实验数据选用百度天气查询API接口,也可以选用其他接口,比如政务数据接口,但不如百度API具有代表性。
3.2.1. 自动化测试实现
自动化测试实现的流程图如图2,结合流程图详解API接口自动化测试实现流程图。

Figure 2. Flow chart of automated testing
图2. 自动化测试实现流程图
1) 确定接口,这里选择的是百度国内天气查询服务API接口,接口地址如下: http://api.map.baidu.com/weather/v1/?district_id=222405&data_type=all&ak=你的ak,其中district_id是区县的行政区划编码,ak是百度开发者密钥,单个接口测试的返回结果如图3,政务接口返回的结果也类似于这样的JSON数据。
2) 随机选择测试数据,因为需要自动化测试多个接口所以需要随机的选择区县的行政区划编码,将接口地址的district_id改为随机变量,这时的接口变成这样 http://api.map.baidu.com/weather/v1/?district_id={{district_id}}&data_type=all&ak=你的ak,这里随机选择了102条数据作为测试数据。
3) 验证返回结果,自动化测试不需要人工再去验证接口返回结果是否正确,在Tests里写一个JS判断,就可以自动判断返回结果是否正确。
4) 分析结果,图4和图5分别是自动化测试运行图和自动化测试数据结果图,在图4中可以看到每个接口的URL和返回结果,还有运行时间以及返回结果的大小,图5是将这些结果导出,导出的结果会有运行的平均时间,成功多少失败多少,通过图5可以看到每条接口的平均响应时间是64 ms,成功了102条数据,也就是全部接口都成功了。
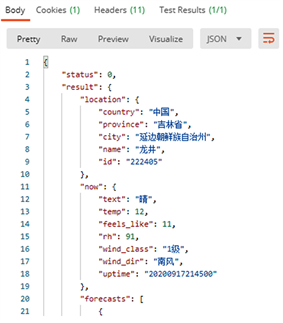
Figure 3. Return result of a single interface test
图3. 单个接口测试的返回结果

Figure 5. Automated test output results
图5. 自动化测试输出结果
上述完成了API接口自动化测试,下面介绍两种具体的数据采集方式。
3.2.2. Python数据采集实现
Python有着丰富的内置库和外部库,内置库可以直接引用,外部库需要安装才能使用,安装方式也比较简单,在命令窗口输入pip install库名即可安装。本文主要用到的库有requests、json、pymongo、csv、datetime、threading、multiprocessing,其中requests是一个Python的HTTP客户端库,用来发送请求与接收响应;json是一种轻量级的数据交换格式,json库将已编码的json字符串解码为Python对象;pymongo是MongoDB数据库的驱动,用来连接MongoDB数据库;csv是用来存储或者打开表格数据的,这里是用来打开csv文件;datetime是一个时间库这里是用来计算数据采集用的时间;threading是多线程库,用来给程序开多个线程;multiprocessing是多进程管理包,它和threading一样都是为了加快采集的速度。
Python数据采集的伪代码如下:
输入:API接口URL和密钥
输出:接口返回结果,并存到MongoDB,程序运行时间
1. 引入Python库,requests、json、pymongo、csv、datetime、threading等;
2. 程序开始时间;
3. 引入线程和线程池;
4. 循环读取区县行政区划编码;
5. 采集API接口数据;
6. JSON数据解析;
7 保存进MongoDB数据库;
8. 程序结束时间;
9. 程序运行时间。
采集到的数据存到MongoDB数据库的结果如图6。
3.2.3. Kettle数据采集实现
Kettle里面有着丰富的控件,用到哪一个可以直接拖拉出来,这里共选择了五个控件,分别是CSV文本输入、字段选择、JavaScript代码、HTTP Client和MongoDB output控件,CSV文本输入控件是用来读取CSV文本文件的,字段选择控件是用来选择需要的字段,JavaScript代码控件是用来定义变量,HTTP client是用来获取API接口URL,MongoDB output是将采集的数据存储到MongoDB数据库,数据采集过程流程图如图7。

Figure 7. Kettle data acquisition process
图7. Kettle数据采集过程
数据采集过程解释:
1) CSV文件输入,因为是以国内天气查询服务API接口为例,故CSV文件选择了国内城市行政区划代码,若是国家企业信息接口应以统一社会编码或者企业名称作为查询条件,广东省常住人口信息应以身份证号码作为查询条件。
2) 字段选择,因为上一步里面可能有很多字段,有些字段是不需要的,字段选择可以帮我们选择出需要的字段进入下一个流程。
3) JavaScript代码是用来获取上一步的字段选择变量,并重新定义一个接口URL变量。
4) HTTP client是用来获取上一步的URL变量,进而采集数据,这里使用了10个线程也就是一次可以采集十条数据,这个线程是可以修改的,在线程使用上Kettle比Python更灵活更容易实现。
5) MongoDB output是将数据存到MongoDB数据库里面,类似于图6,但这里没对JSON数据进行解析,而是选择了直接存储,如若需要解析引入json控件按照jsonpath解析即可。
图8是数据采集运行图,采集3400条数据用时23.6 s。

Figure 8. Data acquisition operation diagram
图8. 数据采集运行图
4. 数据采集对比及结果分析
本文的数据采集环境为Windows 7旗舰版64位操作系统,处理器为Intel(R)CoreTM i7-4790 CPU @ 3.60 GHz (8 CPUs),~3.6 GHz,内存为16 G,Python版本为3.7.0,Python编译器为PyCharm Community Edition 2018.2.4 ×64,Kettle版本为8.2,MongoDB版本为4.0.2,MongoDB可视化工具为Robo 3T 1.2.1。
以采集百度国内天气查询服务API接口为例,采集其他API接口原理同样,此接口共有3400条数据,主要从Python无线程、Python有线程、Kettle不同线程等在数据采集时间上对比,以体现线程对数据采集速度提升的重要性并验证最优线程,数据采集时间如表1,这里选择每组五次实验求平均值,以验证实验结果。

Table 1. Experimental data comparison table
表1. 实验数据对比表
为了更加直观的展示不同采集方式所用的平均采集时间,建了如图9的平均采集时间对比图。
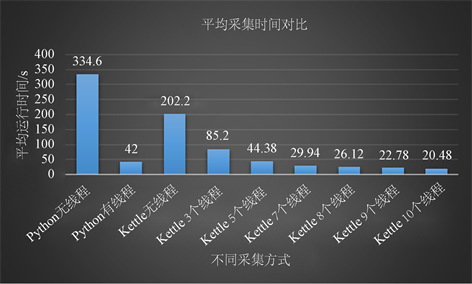
Figure 9. Comparison of average acquisition time
图9. 平均采集时间对比
图中和表中的无线程并非是没有线程,而是没有人为的设置线程,不能并发的采集数据,可以看到两个无线程的采集方式所用时间都是相对较长的,与有线程的相比,最大相差接近10倍,相当于在数据采集时快了十倍。
Python在设置线程时灵活度不够,因此引入了线程池,通过计算可以看到Python无线程和有线程在采集速度上差了8倍,而差的这8倍正好是计算机的CPU逻辑核心数,也是理论上最优线程数,最优线程数并不是指采集速度最快的线程数,而是综合各个方面最优的指数,这一点在Kettle数据采集上得到了很好的验证,随着线程数的增加Kettle的数据采集速度越来越快,在7~10个线程时采集速度逐渐趋于水平,而且在使用10个线程进行采集时,API就开始发布预警通知,并发量已接近约定上限,理论上如果没有并发量的限制,线程数是可以随意调节的,只不过会占用过多计算机资源,甚至导致程序运行失败。
数据采集时间在理论情况下可以通过以下公式计算:
(2)
数据采集时间,
数据采集数量,
接口响应时间,
线程数量,其中
接口响应时间是可以通过自动化测试计算出来的,
在这里不是指最佳线程数量,而是指实际采集中的线程数量。此公式在5个线程以上准确率达90%以上,在7~8个线程准确率达97%,在9~10个线程准确率可达99%,如表2:
Table 2. Formula prediction accuracy
表2. 公式预测准确性
这是因为一个线程在数据采集数量已经稳定,一个线程在实验中每秒平均采集17条数据,每条约58 ms,这个采集速度已经接近于接口的响应速度,上述公式也可以改成如下:
(3)
数据采集时间,
数据采集数量,
单个线程采集数量,
线程数量。这两个公式在计算采集时间上误差不是很大,一个适用于知道接口响应时间,一个适用于知道单个线程采集速度。
5. 结束语
数据的开放共享有利于打破信息孤岛,让数据真正地为人民服务,目前各地都在建立“数字政府”,目的是使政务数据互联互通互享,真正地做到“一网通办”和企业群众办事“只进一扇门”“最多跑一次”。在目前的数据开放共享中,API接口是数据开放的主流方式,如何快速高效地从API接口采集数据是本文研究的重点。本文融合自动化测试、最优线程、Python以及ETL技术等构建了多种技术融合的API接口采集策略,该策略表明在有无线程的时候都比Python数据采集高效,而且线程可调节,实现简单,并推导出数据采集时间公式,该公式在5个线程以上准确率达90%以上,在7~8个线程准确率达97%,在9~10个线程准确率可达99%,在采集之前就可通过该公式以最合理的线程计算出最合理的采集时间,极大地节省采集时间。
但目前的API接口良莠不齐,规范性不够,使得在数据采集时经常性采集失败,应重点加强API接口的管理以及开放接口API的安全性,这样才能使开放共享的数据真正为人们服务,而不是为了共享而共享,同时在数据开放共享的时候,应确保数据的质量,开放的数据应经过清洗后才共享的,“脏”数据共享出来,采集时还得进行复杂的数据清洗过程,这违反了数据开放共享的初衷。
基金项目
国家自然科学基金资助项目(No. 11801081);广东省自然科学基金资助项目(No. 2018A030313063);广东省教育厅重大项目(No. 2014KZDXM055);广东省大数据分析与处理重点实验室开放基金资助项目(No. 2017018);研究生教育创新计划项目(No. 2016SFKC_42,YJS-PYJD-17-03);教育部“云数融合科教创新”基金项目(No. 2017B02101);江门市基础与理论科学研究类科技计划项目(No. 2019030101870008915);五邑大学教学质量与教学改革项目(JX2020054)。
NOTES
*通讯作者。