1. 引言
当前,心血管疾病已然成为中国乃至全球死亡率最高的疾病之一 [1] [2],而心律失常便是最为常见的一类心血管疾病。心律失常的危害在于,它不但可能加重原有的心脏疾病,如加快心力衰竭的发展,而且可以导致患者突然死亡,严重威胁人类的生命健康 [3]。对于心率失常患者来说,采取有效的诊断方式能使其尽早进行治疗,有助于提高患者的临床治疗效果 [4],但传统的心律失常诊断多依赖于动态心电图(Holter),需要由患者携带Holter一至三天的时间来进行长时间的心电监测,不仅影响患者的正常生活,而且后续数据处理极其繁琐,大大降低了诊断的效率,而花费时间较短的12导联心电图又易导致心律失常的漏诊 [5],因此,研究者们一直在寻求一种高效率、高准确率的心律失常诊断方法。
过去10年,许多研究者开始致力于将机器学习应用于包括心律失常在内的心血管疾病的诊断 [6]。机器学习可以广义地定义为一种利用数据来提高性能或进行准确预测的计算方法 [7],是人工智能的一个重要分支,通过机器学习对心电图(ECG)进行分析,我们可以快速且较为准确的完成心率失常患者的筛查。在以往的实验中,研究者们通过使用一些典型的机器学习方法,包括支持向量机(SVM) [8],决策树 [9],卷积神经网络 [10] 等,以较高正确率成功完成了心律失常的诊断,佐证了机器学习在心律失常诊断中的优越性。然而,当面对大数据量、大差异性的样本数据时,上述方法很难在准确率和效率之间取得平衡。
为了同时兼顾准确率与运算速度,本文提出了一种将瞬时功率和功率谱熵等特征以及小波变换相结合的心律失常诊断方法,并在SVM与Bi-LSTM模型下进行测试。结果表明该方法能够保证在良好的训练性能下,取得一个较好的识别结果。通过使用MIT-BIH心律失常ECG数据库进行验证,该方法在SVM中的准确率为98.33%,在Bi-LSTM中的准确率为99.37%,识别速度均在毫秒级,证明其拥有良好的效率和识别性能。
2. 数据与方法
2.1. 数据集构成
本文使用了MIT-BIH心律失常数据库以构成数据集,该数据库一共包含48个记录,每个记录包含两个导联的数据,每个导联时长约为30分钟,采样率为360 Hz,对应650,000个采样点。其中23个记录(100系列)是从4000多份动态心电图带随机选出,剩下的25个记录(200系列)是挑选出不常见但在临床上重要的心律失常数据,每个记录都人为标注了各个心拍对应疾病的类型 [11]。为定位心拍,本文使用了经典的Pan-Tompkins算法,然后对定位好的心拍分别向前取100个采样点,向后取150个采样点,组合成250个采样点的数据段 [12],从而实现ECG信号中QRS波群位置的确定,图1所示即为Pan-Tompkins心拍定位法结果示意图。
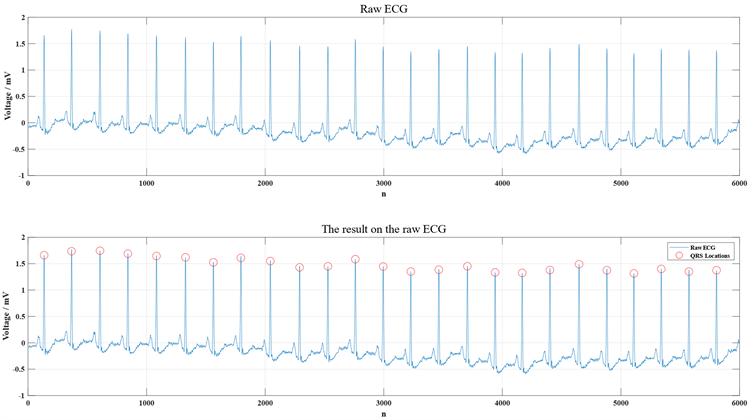
Figure 1. Schematic diagram of Pan-Tompkins cardiopap positioning method
图1. Pan-Tompkins心拍定位法示意图
在定位心拍后,依据标注好的标签,本文将数据分为四类,分别为正常心搏(Normal beat)、左束支传导阻滞心搏(LBBB, Left Bundle Branch Block Beat)、右束支传导阻滞心搏(RBBB, Right Bundle Branch Block Beat)、室性早搏(PVC, Premature Ventricular Contraction),四类数据的波形特点如图2所示。本文将两个导联的数据合并,每类随机选取了1200段长度为2500个采样点(约为7秒)的数据,构成数据集以用于之后的研究。
2.2. 降噪处理
在实际采集心电的过程中,信号常常会受到很多干扰,比如基线漂移、工频干扰、肌电干扰等。为了更好的去除干扰,并尽可能地保留更多的信息,本文选择使用小波分解进行降噪,且由于symN小波基所对应的尺度函数和心电信号的波段更为相似 [13],因此选取了sym8小波作为基函数。由于基线漂移频率基本在0.1 Hz附近,故要完全去除基线漂移应分解10层原信号,将包含高频噪声的D1和D2层,以及低频干扰的A10层去除。处理前后的心电信号对比如图3所示,可以看出,经过预处理的信号R波更加明显,信号更加平滑。
2.3. 特征选取
心电信号包含许多冗余信息,不利于机器学习的进行,因此本文需要进行恰当的特征选取。常见的特征选择包括计算信号频谱图用作特征来输入二维卷积神经网络 [14],但本次研究特征均为一维变量,因此本文提出在频谱图中提取瞬时频率和功率谱熵,并进行组合,以作为特征。瞬时频率可以评价四类心电信号时变频率变化的特点,其将短时傅里叶变换计算出的频谱图时间窗的中心数据作为输出,即每秒对应一个瞬时频率值,如图4所示。而功率谱熵可以测量信号的频谱的稳定性,若信号具有尖峰频谱(如正弦波之和)则拥有低谱熵,若信号具有平坦频谱(如白噪声)则拥有高谱熵,如图5所示。
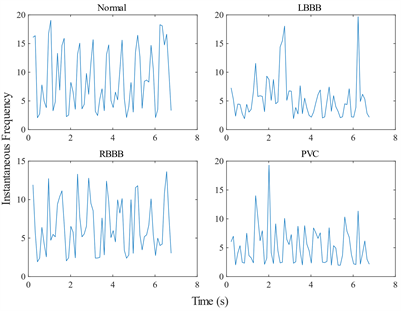
Figure 4. Comparison of instantaneous frequency of four types of ECG signal
图4. 四种心电信号瞬时频率对比
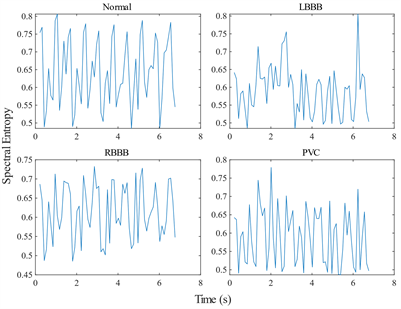
Figure 5. Comparison of spectral entropy of four types of ECG signal
图5. 四种心电信号功率谱熵对比
同时,本文依据SVM和Bi-LSTM网络的特点为其选择了不同的特征组合。由于瞬时频率和功率谱熵的输出值较多,为减少SVM的特征维数,本文选择以二者的平均值作为输入,如表1所示。

Table 1. Features combination of SVM and Bi-LSTM
表1. SVM和Bi-LSTM特征组合
3. 性能测试
3.1. SVM模型构建
支持向量机(SVM)是从广义肖像算法发展而来的一种二分类算法,其根据监督学习方式对数据进行二分类。其基于统计理论,以最优分类超平面作为决策边界,在模式识别、数据分类等问题中被广泛使用。在SVM算法中,通过核函数来把非线性可分问题从原始特征空间映射至高维空间中,以区分正类和负类,从而增强其可分性。一般采用的核函数包括:拉普拉斯核函数、高斯核函数、多项式核函数和SIGMOID核函数 [17]。
在本研究中,使用的SVM模型是由MATLAB中的Classification Leaner实现。在所有模型中,二次SVM表现最为优异,核函数为二次,且对数据进行了标准化。本文使用的验证方法为留出验证法,训练集与测试集之比为9:1。
3.2. Bi-LSTM模型构建
传统的机器学习算法较易受限于特征值,泛化能力较弱,而深度学习具有从数据中自我学习有用特征的能力 [18],因此,本文在SVM的基础上,利用双向长短期记忆网络(Bi-LSTM)进行测试。得益于深度学习具有较大的数据包容性,本文将训练集数据使用sym8小波分解重构出5个频段的信号,并计算了每个频段的瞬时频率和功率谱熵,以作为Bi-LSTM网络的输入。为了加快学习和收敛的速度,本文也对输入数据进行了标准化处理。
长短期记忆网络(LSTM)是对循环神经网络(RNN)的改进,具有RNN的记忆性优点,其通过用存储单元和门机制代替隐藏层更新,解决了常规RNN梯度消失的局限性。LSTM单元内有三个门,分别为输入门、遗忘门和输出门,其中,输入门决定是否用输入序列更新LSTM单元的状态,遗忘门可以选择性的遗忘或保留LSTM单元的当前状态,而输出门负责信息输出,并确定当前的隐藏状态是否传递给下一个迭代 [19]。详细的LSTM单元结构如图6所示。
而Bi-LSTM是LSTM的改进,是由两个LSTM反向组成的,使其神经网络能够双向传输 [20]。当向输入层输入一个向量时,双向LSTM模型会分别从前后两个方向进行运算。传入隐藏层的值由两个LSTM计算出的值共同决定 [21]。
本次研究使用的Bi-LSTM结构如图7所示。为提高学习深度,本文使用了2层bilstmlayer。为防止过拟合,本文在第1层后增加1层dropout,最后输入到4层全连接网络中,通过softmax激活函数实现信号的分类。此外,由于内存需求小,计算性能更好 [22],本文选择使用Adam求解器。该Bi-LSTM模型的其余参数如表2所示。

Figure 7. The net structure of Bi-LSTM
图7. Bi-LSTM网络结构
该Bi-LSTM验证方法与前文介绍的SVM验证方法相同,二者的测试平台均为MATLAB R2020b。
4. 实验结果与分析
在模型测试中,本文分别对有标签的ECG样本特征进行四分类训练,其中训练集与测试集共包含480个采样数据,该四分类将心电数据划分为正常心搏(Normal)、左束支传导阻滞心搏(LBBB)、右束支传导阻滞心搏(RBBB)与室性早搏(PVC)。最终,本文得到了SVM与Bi-LSTM两种模型下分类结果的混淆矩阵,如图8所示。
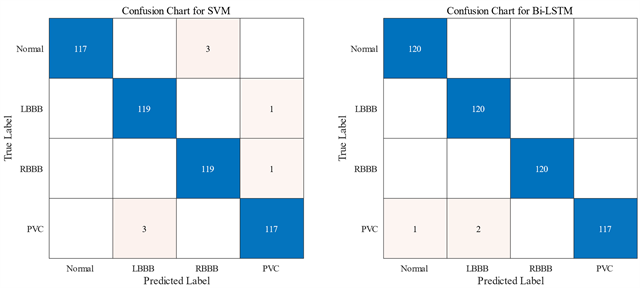
Figure 8. Confusion matrix of classification results of SVM (left) and Bi-LSTM (right) algorithms
图8. SVM (图左)与Bi-LSTM (图右)算法所得分类结果的混淆矩阵
在该混淆矩阵中,实际标签(True Label)与预测标签(Predicted Label)分别代表实际数据与算法预测数据分布。根据混淆矩阵数据,本文计算了两种分类算法的准确率(Accuracy)、灵敏度(Sensitivity)、召回率(Recall)与F1-score,具体数值如表3所示。
Table 3. Algorithm evaluation index
表3. 算法评价指标
在混淆矩阵之外,本文也对两种模型的受试者工作特征曲线(ROC curve)进行了计算,其结果如图9与图10所示。ROC曲线可反映模型的区分能力,X轴方向表示假阳性率(False Positive Rate),Y轴方向表示真阳性率(True Positive Rate)。ROC曲线下方包络面积大小为AUC (Area Under Curve),AUC面积在0.9以上则表示模型性能优异。由此ROC曲线可知,本方法在SVM与Bi-LSTM模型下都具备对于心律失常ECG信号的高准度分类能力,而Bi-LSTM模型相较于SVM模型具有更好的时域结构特点,也具有更好的分类性能,可有效区分出正常心搏、左束支传导阻滞心搏、右束支传导阻滞心搏与室性早搏四种心律信号。
此外,本文也对该方法的时间损耗进行测试,并与传统的非线性动力学特征进行比较。本文计算并统计了SVM和Bi-LSTM方法下计算特征并完成识别的时间,与传统的非线性特征(包括排列熵、Lyaouniv指数等)消耗的时间进行对比,其结果如图11所示。由此可知,在使用本文所提出的瞬时频率与功率谱熵融合特征的情况下,SVM模型与Bi-LSTM模型的时间损耗缩短至6.92%左右,识别速率达到毫秒级,因此本文所提出的方法具有更好的时间性能。
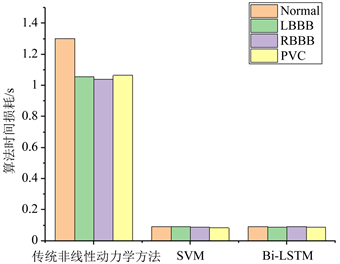
Figure 11. Comparison of four classifications task time loss of the proposed method and traditional nonlinear dynamics methods
图11. 本文提出方法与传统非线性动力学方法的四分类任务时间损耗对比
5. 结束语
本文针对心律异常信号的特点,通过应用瞬时频率和功率谱熵融合特征以及Pan-Tompkins算法,对基于机器学习的心律失常诊断方法进行改进。在使用MIT-BIH数据库构建的数据集的测试中,该方法在SVM和Bi-LSTM下的准确率分别为98.3%和99%,相对于使用传统的非线性动力学特征,二者的都得到了更高的分类精准水平与更快的时间响应性能。该方法弥补了当前心律失常诊断方法的不足,为高效率、高准度的心律失常诊断提供了一种可能。
致谢
感谢东北大学医学与生物信息工程学院石晶晶副教授、刘海莲同学、张嘉玉同学,以及人体通信实验室其他成员的指导与帮助。
基金项目
本项目得到了东北大学医学与生物信息工程学院SIVI计划的资助,项目编号为191186。