1. 引言
E Arikan [1] 在2009年发现并分析了信道联合和信道极化的现象,并据此提出了Polar码和其使用的SC译码算法。Polar码在编码理论中作为容量可达的码字是一个很大的突破。在5G通信网络中,Polar码在短码长度的应用范围上可以代替LDPC码。Tae和A. Vardy [2] 针对Polar码的SC译码算法引入列表辅助验证,提出了SCL译码算法改善性能,并且该算法的性能在列表较大的时候可以达到最大似然(ML)译码性能。Li B [3] 提出了一类新的混合码字“RM-Polar”码。这类码字通过混合RM码和Polar码构造而成,其最小汉明距离比Polar码的最小汉明距离大,因此性能要优于Polar码。为了提升Polar码的最小距离,建议使用RM-Polar码或者将Polar码与CRC [4] 和PC [5] 串联以显著提高性能。最近,E. Arikan [6] 提出了一类新的PAC Polar码,通过在RM码之前进行卷积运算,可以提供比以前的纠错码更好的性能。Li B [7] 简单证明了预变换Polar码的最小距离不会变小,并且提出了一种通过分类和总结级联码的特性来设计上三角预变换的构造方法。2016年, [8] 提出,Polar码和RM码是很相近的,因为它们具有相同的代数结构,也就是说,他们可以组合单项式构成。特别的,这种构造提供了一种有效的方法去计算递减单项式码和Polar码的最小码字的数量。通过在Polar码编码器的中间的阶中加入交织器 [9],Chiu M C [10] 提出了一类新的Polar 码——交织Polar码(I-Polar码)。假设交织器是均匀分布的,他们衍生出重量枚举函数(WEF)来计算从I-Polar码集中随机选择的码的误块率(BLER)的上限。在 [11] 中,他们修正了之前关于Polar码的信息位的选择方式,并且提出了基于可靠度和和行重选择的方法。通过阅读大量文献,我们发现了很多改善Polar码和RM码码谱的方法。这些方法没有改变信息位的选择,而且易于实现。
2. 预备知识
2.1. Polar码
n阶Polar码由生成矩阵
构成,其中二元核矩阵定义为
n表示n阶克罗内克积。该Polar码的码长为
并且包含K个信息比特。
码字由
得到,其中
,
分别表示输入的信息序列和输出
的码字序列。B表示比特逆序排列操作。由于Polar码的特殊结构,其可以使用SC译码器来进行编译码操作,复杂度为
。随着码长N趋于无穷时,Polar码可以达到信道容量 [1]。
u中的N个比特可以根据它们在信道中的可靠度分为两组,K个最可靠的比特被看作信息比特用来传递信息,剩余的
个比特作为冻结比特被设置为固定值,该固定值在编译码器两端均已知。我们用
和
表示u的子集,分别包含对应信息比特和冻结比特的位置索引值。可靠度序列可以通过下列方法获得,比如,巴氏参数 [1],密度进化 [12],高斯近似 [13],遗传算法 [14],beta扩展 [15] 和深度学习 [16]。
2.2. RM码
RM码(Reed Muller),码长为
,包含
个信息比特,最小距离为
。RM码的K个信息比特是根据矩阵
中行的重量由大到小选取的,并且将重量为
的行全部选入信息集。行重最大的对应的K个比特作为信息比特,剩余的作为冻结比特,固定值为“0”。我们用
表示RM码,汉明距离d,最小汉明距离
。
2.3. 行的表示方法
假设一个Polar码的码长为
,我们将会得到一个明确的矩阵。通过 [1] 的比特索引法,可以得出一个长度为
的向量
。我们将其第i个元素表示为
,其中
,
是整数
的二元表示。也就是说,
,可以看作是行的另一种表示。同样的,一个
的矩阵A中的元素
可以表示为
,其中,
分别是
和
的二元表示。然后,就可以得到
中的元素为
。
基于上述的分析,我们提出了一个新的行表示,关于行号i与行中“1”的位置索引值集合的双射如下:
等号左侧的i为行号,等号右侧的集合是矩阵
第i行中“1”的位置索引值。例如,矩阵中的最后一行(全“1”行)的行号为
,则
包含所有的列索引值。在剩余的行中,重量为
的行的二元表示与全“1”行相比缺失了一项,也就是说,对应的
中的元素不包含缺失的项。我们将每一个
都看作一个事件。
为了方便理解,让我们通过以下例子来解释。
例:
,
行号16,
行号15,
行号14,
我们可以按行重将矩阵中所有的行分为以下几组,每组中的元素都是行重固定的长度为m的行的二元表示。
表示每一组元素的数量,w表示对应的行重。
3. 码谱分析
由假设Polar码码长为
,包含K个信息比特,是根据行重从大到小选取的。在K确定之后,如果满足
,码谱与RM码相同且信息位的选择是唯一的。如果不满足
,信息位的选择不唯一。那么不同的信息集产生的码谱有什么规律吗?
基于仿真结果,我们可以得到以下定理。
定理3.1:码长为
的Polar码若选用RM码选择信息位的方式,则当K的范围满足
时,可以得到唯一的重量谱。
证明:假设我们按照RM码的方法选择信息位,也就是说,根据行重从大到小(分组中从左到右)。
如果K满足
,码谱和信息位的选择都是唯一的,与RM码相同。在其他情况下,
K个信息位的选择方式是不唯一的。因为会出现在相同重量的组中只选取一部分行作为信息位。我们可以定义从这个组取出的元素数量为
,这些元素进行线性组合时的系数为“1”的数量为s,码字的重量为
,重量为
的码字数量为
。首先,我们刻画同组内的线性组合的情况。
1) 当
时,
2) 当
时,
m) 当
时,
接下来,我们刻画不同组之间的线性组合的情况。我们首先解释说明
的情况。
因为选择方法的要求,全“1”行一定会被选入信息集的K行中。
情况1:对于
和
,信息集的选择方式唯一,码重量谱自然唯一。
情况2:对于
,
组中有
行,其中的
行被选择。与全“1”行相比
较,被选择的行的二元表示均缺少一项。我们可以得知被选择的K行的线性组合满足:
在这个情形下,所得到的码字重量是相同的。在上述两种情况下,该重量所对应的数量是相同的,均为
。如果K值确定,码谱唯一。
情况3:对于
,在
的基础上,要从重量为
的组中取出一行,有
种取法。与全“1”行相比,被选择的行的二元表示缺失两项,这样的行有
个。我们可以这样考虑:
首先我们固定之前的线性组合,将其看作一个码字,然后将这样的码字按照是否与新选择的行具有相同的缺失项分类。
很明显,因为组合排列的随机性,会出现新的重量的码字。通过行的二元表示的规则,我们可以知道从
组中选择的每一行都会出现上述的情况。所以在这样的情况下,同样会出现这样重量的码字。最终,将会获得一个唯一的码谱。
情况4:对于
,也就是,在情况3的基础上再从
中再选取一行。此时,我们从(2)中得知,从
中选取的两行会根据彼此之间的关系将会形成不同的重量和码谱。同理,如果从该组中抽取更多的行,将会出现更多的组合和不同的码谱。
情况5:对于
,我们可以在
得到唯一码谱的基础上考虑。因为二元域的计算特性(假设
都是二元码字,则
),该情况等同于在
的情况下从
组
中选择一行相加,即等效于情况3,最终得到一个唯一的码谱。
情况6:同理可得,
和
的情况可以按照排列
组合和重量分布的对称性解释。
定理成立。
上述方法只能列出一些简单情况,我们可以应用组合数学中的容斥原理及其推论来刻画一般情况,见图1。
定理3.2:(容斥原理) 假设S是一个有限集,
,则
推论3.3:假设S是一个有限集,
,则
定理3.4:假设S是一个有限集,
是n条性质。对于任意
个正整数,
,以
表示S中同时具有性质
的元素个数,以
表示S中不具有
中任一个性质的元素个数,则
我们将上述定理应用到二元域
上,得到一个新的定理。在
上,偶数次重复的部分被消除,奇数次重复的部分被保留一份。我们将每一个事件
记为
。
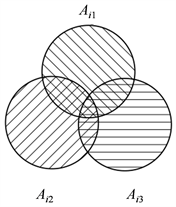
Figure 1. The graph of Inclusion and exclusion principle
图1. 容斥原理例图
定理3.5:假设S是二元域上的一个有限集,
,则
证明:当
时,
当
时,
假设当
时,该结论成立。
那么当
时,
综上所述,定理成立
。
推论3.6:假设S是二元域上的一个有限集,
是n条性质。对于任意
个正整数,
,以
表示S中同时具有性质
的元素个数,以
表示S中不具有
中任一个性质的元素个数,则
证明:我们将
看作S中具有性质
的全部元素所成之集,则
表示S中不具有
中任一个性质的全部元素所成之集,所以
因为
表示S中同时具有性质
的全部元素所成之集,所以
,从而
综上所述,定理成立。
这里,我们认为更好的码谱是具有更少的最小距离码字数量。那么当信息集选择不唯一的时候,什么样的信息集选择方式可以有更好的码谱呢?
通过上述定理3.5和3.6,我们可以得到可能出现的码字重量及其补集。如果我们想要得到更好的码谱,我们需要选择在相同事件的条件下具有最小重量码字的数量较少的情况。也就是说,我们需要将定理3.5的结果进行量化,选择最小重量最少的情况所对应的选择方式。
通过图1,如果想要码字的最小距离最大,即使得重复奇数次的部分尽可能大,重复偶数次的部分
尽可能小。让我们定义一个函数为
作为线性组合的结果。在
中,出现偶数次的项被消除,
出现奇数次的项被保留一次。虽然不甚准确,但是可以用它来衡量得到的码字重量。因此F中的项越多,说明这样组合后得到的码字重量越大,即所选择的行的二元表示尽可能不同。虽然没有给出具体的结果,但逻辑具有一定的意义,因此该衡量函数将在后续工作中进行实验。
4. 总结与展望
在本文中,我们已经刻画了原Polar码的重量谱分布规则,给出了一些结构化改善的想法。目前大部分的码谱优化方法也可以从这个角度进行分析。已经证明PAC-Polar码的结构和在阶之间添加交织器可以改善码谱。我们可以利用F函数的计算结果来分析优化后的结果,甚至可以根据一些已知的结果来预测哪个交织器可以获得更好的码谱。我们也可以根据定理3.5设计阶之间的交织器。通过定理3.5得到某些码字的具体形式,然后通过交织器将其他码字的“1”置于已知码字的“0”位置,得到一个更大权重的码字。我们可以使用一个符合条件的线性组合以获得更好的码谱的方法,想一想,有没有可能基于这个想法来设计动态交织器?
例如Polar码的生成矩阵可以表示为:
其中
。
因为信息集的不同选择方式,我们定义
构成的码字
重量为
,
构成的码字
重量为
,
构成的码字
重量为
,
和
中共同为“1”的位置的数量为c。如果我们想要在
中设计一个交织器,我们需要将
中的“1”尽可能放置在
中“0”的位置上,
中多余的“1”可以随机放置在
中“0”的位置上。然后原始重量为
的码字,现在重量为
,即这是可能达到的最大重量。