1. 引言
新冠肺炎(COVID-19)作为流行的疾病,严重威胁着人们的身体健康。世界各国也正在积极应对,但是面对传播快,传播途径多样等问题,给各国防疫工作带来了不少预防困难。随着病例数逐渐增多,对于各国医生来说,根据CT胸片判断是否是新冠肺炎患者也带来了不少压力。因此本文采用计算机辅助检测CT胸片的方式帮助医生进行对COVID-19的诊断,这对筛查具有重大的意义与价值。
随着科技的发展与医学研究的不断深入,使得计算机与医学也变得密不可分了。先进的医学知识随着计算机共享功能的全球化,为医学者提供了更多更宽广的学习与交流的平台。近年来,人工智能等技术飞速发展,有效促进了科技成果在医疗领域的落地 [1] - [6]。
新冠肺炎的检测通常利用CT扫描得出结论,随着疫情的发展对于医生来说每天的工作量巨大,很有可能会有误诊,误判的情况;并且对于医学影像中的重要目标往往尺寸过小,并伴有一定的形态学特征,因此针对图像的小目标区域的目标检测意义非凡 [7];因此引入图像处理技术对所有的CT图像进行判断。本文针对COVID-19患者和Normal健康数据集利用YOLOv5进行CT胸片检测有效地提高检测效率与准确率并降低了医生的工作任务,并且有效的决策对于医生做出正确的临床判断和制定有效的治疗方案有重要作用。
2. YOLO算法
2.1. YOLO模型
YOLO模型 [1] [2] [3] [6] [8] 可以在一幅图像中检测到物体并识别出物体在图像中所在的位置,YOLO是一种带有建议框的神经网络,训练速度快。已有YOLOv1-v7,表1是对v1~v5的描述 [9]。从表中可知YOLO的v5的性能远远优于v1。YOLOv5相比YOLOv4而言,在检测平均精度降低不多的基础上,具有均值权重文件更小,训练时间和推理速度更短的特点。
2.2. YOLOv5
YOLOv5是一步的目标检测算法,只需要提取一次特征即可实现目标检测,提升了检测速度,是在YOLOv4的基础上添加了一些新的改进,使得其速度与精度都得到了极大的性能提升,具体改进包括:输入端的Mosaic数据增强、自适应锚框计算、自适应图片缩放操作、Focus结构、CSP结构、SPP结构、FPN + PAN结构、GIOU_Loss [10] [11] 等。

Table 1. YOLOv1-v5 relationship and performance table
表1. YOLOv1-v5关系及性能表
首先,YOLOv5的输入端采用了和YOLOv4一样的Mosaic数据增强的方式。随机缩放、随机裁剪、随机排布的方式进行拼接。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框进行对比,计算二者的差再进行反向更新,重设框架参数,自适应训练不同数据集。其中YOLOv5算法在自适应图片放缩上也采用了一种新的方法,根据图片大小去自适应的添加最少的黑边到放缩之后的效果图上去,即网络会根据原始图片大小和输入到网络的图片大小进行计算缩放比例,进而计算黑边填充数值;这样不仅减少了黑边框带来的数据冗余也提高了之后数据训练的速度。
其次,YOLOv5的Backbone包含了Focus模块、BottleneckCSP和SPP。处理时,先对输入的图片进进行切片处理:将图片进行网格分块,在一张图片中每隔一个像素取到一个值,将取到了四张图片,四张图片互补,不会信息丢失。将图像的宽度和高度信息集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了3*4 = 12个通道,并将得到的新图片联系起来再经过卷积操作,得到没有信息丢失情况下的二倍下采样特征图。Focus的使用减少了原始信息的丢失,减少FLOPS (计算量)并加快运行速度。YOLOv5采用了两种CSP设计,分别为CSP1_X结构和CSP2_X结构,区分为是否采用了shortcut。CSP1_X应用于backbone主干网络部分,CSP2_X则应用在Neck结构中。BottleneckCSP利用CSP1_X,通过它解决了Backbone中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸。通过SPPF进行特征抽取和特征融合,相较于SPP训练速度又进一步提升。
再次,YOLOv5采用借鉴CSPnet设计的CSP2_X结构,加强网络特征融合的能力。YOLOv5的Neck的网络结构设计沿用了FPN + PAN的结构。FPN是自顶向下的模式,将高层特征传下来,而底层特征却无法影响高层特征,并且FPN中的这种方法中,顶部信息流往下传,是逐层地传,计算量比较大。PAN则就解决了这一问题。FPN中间经过多层的网络后,底层的目标信息已经非常模糊了,因此PAN又加入了自底向上的路线,使得顶层feature map也可以享受到底层带来的丰富的位置信息,从而提升了大物体的检测效果,弥补并加强了定位信息。FPN + PAN的结构提高了特征提取的能力。
最后,YOLOv5中的输出端采用了GIOU_Loss函数做Bounding box的损失函数,并且采用加权NMS方式进行对边框的优化处理,选出置信度较高的候选框,又进一步提高了检测的准确程度。
基于该网络模型优势,本文采用YOLOv5对新冠肺炎疾病进行检测。
3. YOLOv5新型冠状病肺炎疾病检测
新型冠状病毒肺炎在CT上有典型的CT表现,因此可通过YOLOv5对肺CT辅助诊断新型冠状病毒肺炎。在CT上早期的新型冠状病毒肺炎呈现多发的小斑片影和间质改变,以肺外带明显,进而发展为双肺多发磨玻璃影、浸润影,有一些严重者在CT上则表现出现肺实变,胸腔积液少见。
随着国内外医学工作者对新型冠状病毒肺炎的研究,COVID-19有不同分期,在CT影像学表现也不同,早期多为单侧或双侧肺外带、胸膜下,呈小叶中心分布斑片状、小条状、磨玻璃影,甚至单纯的磨玻璃结节。但有也有部分患者早期症状出现后,肺部CT检查可完全正常,故需要动态CT检测。随着感染进一步加重,肺CT范围逐渐扩大,可表现为双侧多叶或双肺叶中外带分布病变,病变成分增多,可以表现为磨玻璃样结节,磨玻璃样结节伴实变影或单纯实变影,可以出现小叶间隔增厚,还有铺路石征、反晕征、血管增粗等。针对以上COVID-19在CT上的典型特征,采用YOLOv5可以辅助医生对冠状病肺炎疾病检测。
检测流程
首先,进行Mosaic数据增强,它是采用4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接,这样做可以丰富COVID-19检测数据集,随机缩放增加了很多CT中小COVID-19特征目标,让检测的鲁棒性更好;并且可以做到一个GPU就可以直接计算4张图片的数据(如图1),使得Mini-batch大小并不需要很大,就可以得到一个很好的检测效果。
其次,在初始锚框的基础上输出COVID-19预测框,进而和真实框Groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数,采用缩减黑边的方式,来提高推理CT中COVID-19特征的速度,自适应地计算出最佳锚框值。
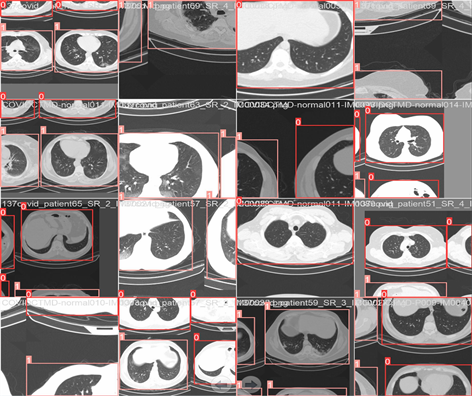
Figure 1. Image transformation in data enhancement
图1. 数据增强中的图像变换
再次,将剪切好统一尺寸信息的肺部CT图像输入进Backbone (如图2)。通过Focus模块后将图像进行切片工作,得到切片后的图像降低了FLOPS (计算量)加快整体运行速度。YOLOv5使用CSPDarknet作为Backbone的另一部分,从输入图像中提取丰富的信息特征,这提高了对于小的COVID-19特征检测。通过CSPNet,使得网络的梯度信息重复问题得到解决,将梯度的变化集成到特征图中,既保证了推理COVID-19速度和准确率,又减小了训练模型尺寸。最后通过SPPF进行特征COVID-19抽取和COVID-19特征融合。

Figure 2. Backbone structure diagram
图2. Backbone结构图
最后,输出预测采用损失函数GIOU_LOSS的基础上,预测COVID-19框筛选采用加权NMS方式去提取最终最为准确的预测框去输出COVID-19结果,检测新冠肺炎疾病所在的位置区域。检测结构图如图3所示。
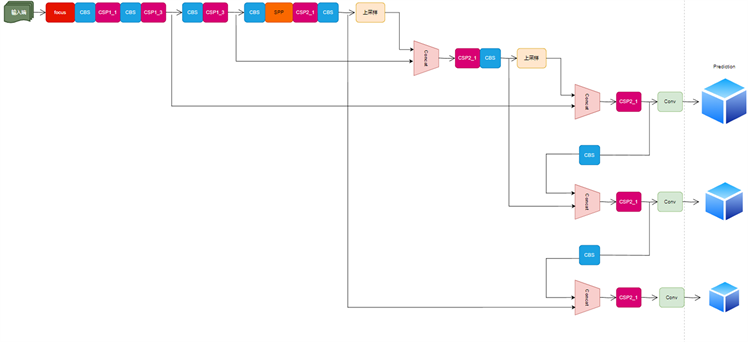
Figure 3. YOLOv5 detail structure diagram
图3. YOLOv5细节结构图
4. 实验平台及结果分析
4.1. 实验数据来源以及配置环境
实验数据来自于COVID-Net全球疫情实时数据库。该数据集包含两类胸部的CT图像,分别为:COVID-19类和Normal正常类。该数据集分训练集和验证集。测试集和验证集共2800张,其中训练集为了减少泛化误差,使得模型能过更好地接近真实数据训练好的模型用测试集进行模型准确度的预测;最终实验结果由验证集得出,验证集共2000张图像。
实验环境配置为:实验环境:cpu:i7-11700h,GPU:nvidia RTX 3060(12G),python库:pytorch,matplotlib。
4.2. 评价指标
实验采用mAP (mean Average Precision)即各类别AP (Average Precision)的平均值,来衡量本实验算法的准确度与置信度。首先计算图像的精确度(Precision)和召回率(Recall) [12]:
(1)
(2)
其中TP是正类判定为正类、FP是负类判定为正类、FN是正类判定为负类、TN是负类判定为负类。
根据Precision-Recall曲线图通过式(3)计算出AP结果:
(3)
其中ri为召回率,Pinter为对应的准确率。r是按升序排序的Precision插值段的第一个插值处对应的Recall值。
所有类别的AP就是mAP,为式(4):
(4)
4.3. 训练细节及结果
新冠肺炎疾病的CT具有典型的影像学表现,采用YOLOv5模型训练得出图4,图5结果。图4是在人工标注的结果,图5为本实验检测标注结果,从图4和图5可以知YOLOv5检测标注的结果与人工标注的结果一致。进一步观察可知YOLOv5能检测到早期可以呈现出多发小斑片状的间质性改变阴影。
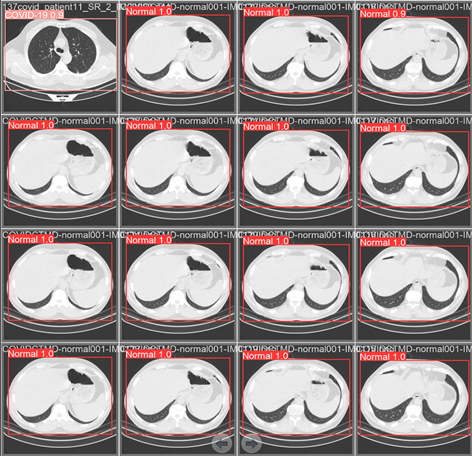
Figure 5. YOLOv5 training result chart
图5. YOLOv5训练结果图
本实验采用YOLOv5模型进行分批次多次重复循环实验(如图6)最后得到相应的实验结果。用训练集进行实验得到的实验结显示COVID-19检测框损失值(图6中box_loss)从原来0.05开始降为从0.02开始,稳定后的收敛值也从0.003降低为0.001;COVID-19目标损失值(图6中obj_loss)从原来0.025开始降为从0.006开始,稳定后的收敛值也从0.002左右降低为0.0006左右;COVID-19类别损失值(图6中cls_loss)从0.0200下降为0.0004左右;精度则提升到0.99以上,召回率也显著提高,最终mAP_0.5达到了99.5%,有效精准地对COVID-19的CT图像与正常CT进行了有效地区分。
5. 结语
本文基于YOLOv5的优势针对新冠肺炎患者的CT与正常肺部进行了准确有效地区分,快速准确的识别给医生减轻了极大的负担。YOLOv5采用以cell为中心的多尺度区域取代region proposal,舍弃了一些精确度以换取检测速度的大幅提升,检测速度可以达到45 f/s,满足了检测实时要求,同时通过实验可知检测精度为mAP_0.5达到99.5%。但是,YOLO在极大提高检测速度的情况下,也存在一定的问题,由于YOLO关于定位框的确定略显粗糙,因此其目标位置定位准确度不高,仍需不断提升改进以提高定位尺度精度。