1. 引言
在实际工作中收集的数据,由于收集方式和数据来源的不同,这些数据通常包含数值型、分类型、多媒体等多种类型,这给挖掘出有价值的信息时带来了挑战 [1]。为解决数据类型多样化问题,通过数据预处理,将原始数据编码为分类型、数值型或混合型数据(包括数值型和分类型),然后再应用于机器学习算法进一步开展数据挖掘任务 [2]。就我们所知,很多高性能的机器学习算法只能处理单一的数据类型(即分类型或数值型),例如,神经网络和回归等算法只能输入数值型数据,决策树和朴素贝叶斯等算法只能应用于分类型数据。但是这些机器学习算法中只有少数可以直接处理分类数据,并且数值数据比分类数据有更好的代数特性。因此,为了将混合数据广泛应用于支持数值输入的机器学习算法,在混合数据中把分类数据转化为数字数据是一种常见的方式 [3]。
然而,如果编码过程损失过多的信息,将得到低质量的数值数据,这会严重影响后续学习算法的性能和可靠性 [4],因此,寻找一种高质量的编码方法至关重要,如何将混合型数据编码为高质量的单一数据类型吸引了研究者的广泛关注 [5]。Kasif等人 [6] 提出了能够处理分类型数据的MBR转换(或称为条件概率转换,CPT),它在分类数据的距离度量(如值差度量 [7] )中取得了不错的性能。此外,我们针对CPT的不足,试图寻找对应的缓解策略。CPT是以条件独立性假设为前提,当数据的属性之间存在强相关关系时,该方法估计的条件概率是不准确的。为此,学者们提出了一系列的改进方法。Jiang等人 [8] 提出了隐藏朴素贝叶斯模型,它通过为每一个属性构造隐藏父属性改进条件概率公式,从而放松属性之间的条件独立性假设;Li等人 [8] 通过微调条件概率的方法提出了一个微调条件概率转换;Li等人 [9] 通过引入TAN-tree放宽条件独立性假设以改进条件概率,提出独依赖值差度量(ODVDM)。
此外,在实证研究中我们发现:转换后的数据集中,属性加权对数据挖掘起着重要作用,为此,需要设计一种适合于数据的属性加权方法。Zhang等人 [10] 提出属性和实例加权的朴素贝叶斯(AIWNB),它结合实例加权和属性加权,对于属性权重定义为互相关性和平均互关联度的差值,利用标准sigmod函数处理属性权重并加权 [11]。Wang等人 [12] 提出双重加权的平均独依赖估计(DWAODE),他们用属性加权和模型加权对平均独依赖估计器(AODE)进行优化,注意到以不同超父属性结点的超父独依赖估计器(SPODE)性能不同,对AODE中的每一个SPODE赋予一个权重,并且对SPODE中的每一个属性加权,两者结合后的模型可以提升准确性。Zhang等 [5] 提出多传递距离嵌入学习(MTDLE),这也是一种混合数据分类属性转换方法,它通过多传递距离学习得到任意两个样本之间的距离矩阵,再通过必连与勿连约束得到对应样本距离矩阵的权重并加权,作为最后的转换结果。以上运用属性加权方法都可以提升模型的性能,说明属性加权是有效的。因此,我们通过借鉴ODVDM和属性加权的构想,提出了一个属性加权的独依赖条件概率编码方法(AWODCPE),改进CPT以提高它的分类数据编码质量。
本文的组织结构如下。第2节介绍了一些预备知识,包括混合数据集介绍、条件概率转换方法、TAN-tree和属性加权方法的主要内容。第3节介绍属性加权的独依赖条件概率编码方法的主要内容。第4节设计实验来证明我们方法的数据编码性能。最后在第5节总结。
2. 预备知识
2.1. 混合数据集
混合数据集是指包含分类属性和数值属性的结构化数据集,如表1 (“Automobile”数据集所示)。其中,“engine type”、“aspiration”和“fuel-type”是分类属性,“width”、“horsepower”是数值属性,“class”为分类标签。

Table 1. Description of mixed datasets
表1. 混合数据集介绍
2.2. 条件概率转换方法
令
是一个混合数据集,
是所有属性
的总数,这里
和
分别是
个分类属性和
个数值属性。数值属性可表示为:
(1)
这里
是第i个实例第j个数值属性的属性值,其中
。同理分类属性可表示为
(2)
这里
是第i个实例第j个分类属性的属性值。CPT将分类属性值
转换为数值行向量
:
(3)
其中,
,这里l是标签个数,
是给定标签
属性值
的概率。由公式(3)可知,CPT是以属性条件独立性假设为前提,然而在所有的属性之间可能存在依赖关系,例如表1中“engine type”和“aspiration”或“fuel-type”之间存在联系,如果忽略这种依赖关系可能会导致估计的概率不准确 [9]。
2.3. TAN-tree
独依赖值差度量 [9] 实行与贝叶斯分类器 [13] 相同的策略学习属性之间的网络结构,生成一棵TAN-tree以获得不同属性的依赖关系,具体步骤如下:
1) 使用下式计算任意两个分类属性之间的条件互信息
; (4)
2) 以属性为结点构建完全图,将图中任意两个结点之间无向边的权重设为
;
3) 构建完全图的最大带权生成树,挑选根变量,将边设置为有向;
4) 加入标签结点c,增加从c到每个属性的有向边。
2.4. 属性加权方法
属性加权 [14] 为0到1之间的每个属性分配连续的权重。在AIWNB [10] 中,通过以下公式计算权重,首先计算属性与标签之间和属性与属性之间的条件互信息:
(5)
(6)
再将公式(5)和公式(6)的条件互信息归一化:
(7)
(8)
最后由属性权重定义为互相关性和平均互关联度的差值(即公式(9)),并利用sigmoid函数将权重映射到[0, 1]中(即公式(10)):
(9)
(10)
AIWNB [10] 中的实验证明属性加权确实取得了不错的效果,每个属性的权重被纳入到公式(11)所示的朴素贝叶斯分类公式中:
(11)
上式中,
是标签为c时的先验概率,
是标签为c时分类属性值为
的条件概率。除了上述的加权方式,在MTDLE中,通过判别嵌入的方法为不同共现行为得到的距离矩阵加权,具体用公式(12)为距离矩阵加权:
(12)
上式中,Dj是由不同共现行为得到的距离矩阵,D是加权后的距离矩阵。而我们的方法借鉴MTDLE的加权方式为转换后的数据加权。因此,我们结合独依赖值差度量放松属性依赖性的方法和属性加权对条件概率编码进行改进,提出属性加权的独依赖条件概率编码方法(AWODCPE)。
3. 属性加权的独依赖条件概率编码方法
3.1. 算法框架
AWODCPE具体的编码过程分为两个部分:
根据图1第一部分提出了一个独依赖条件概率编码方法,将混合属性数据中的分类数据转换为数值数据。首先,计算每个数据集所有分类属性之间的TAN-tree得到分类属性之间的依赖性,改进CPT的公式,将一个分类属性值转换成一条条件概率向量,并替换原分类属性
中对应的分类属性值得到数值属性
,以此提高混合数据的转换质量。
第二部分是基于属性之间的条件互信息的属性加权方法。由于公式(6)和公式(8)中没有考虑标签对属性与属性之间条件互信息的影响,所有我们对这两个公式进行改进,求出每个数据集的所有分类属性的权重之后并加权,表示为:
(13)
3.2. 独依赖条件概率编码
由前面所述,CPT具有现实中不成立的条件独立性假设,因此,我们使用独依赖值差度量相同的方法进行改进。经过计算TAN-tree的四个步骤,我们能够获得每个数据集中分类属性依赖关系,但仅保留了最相关属性之间的依赖性,并没有包括所有的分类属性信息。我们从TAN-tree中得到除根结点之外所有分类属性的父属性之后,再将分类属性值
转换成数值向量
:
(14)
上式中
为父属性
的属性值个数,则第j个分类属性值可转换成
(15)
其中,
,式中l是标签个数,
是示性函数(当函
数中的两个元素相等时,返回1,否则返回0),
是第j个属性
的父属性
同一行的属性值,
是给定标签
和父属性值
的
的概率。通过公式(14)和公式(15),我们就能将分类属性转换为数值属性。
3.3. 属性加权
因为不同的属性的重要性不同,需要为其分配权重并加权。我们借鉴AIWNB [10] 的方法计算权重,但是他们的公式(6)中没有考虑标签的信息,这可能导致计算权重时出现偏差。在DWAODE [12] 中,他们通过使用属性与标签之间的条件概率计算条件互信息,我们借鉴他们的方法改进AIWNB的权重计算公式(6)。对公式改进如下:
(16)
其中,
(17)
(18)
(19)
公式(17)(18)(19)中的概率又由以下四个公式计算:
(20)
(21)
(22)
(23)
这里q是标签数量,
和
分别是是第j个和第k个分类属性中属性值的数量,N是实例个数。由以上四个公式计算出任意两个属性之间给定标签情况下的条件信息值后,我们归一化条件互信息:
(24)
(25)
公式(9)可变为:
(26)
然而,通过公式(26)计算的权重可能为负,所以我们通过公式(10)将权重映射在区间[0, 1]中,得到分类属性的Mc个权重:
,并对编码后的分类属性
加权,可表示为:
(27)
原始的数值数据不做任何处理,并与式(27)的数据拼接获得最后的转换数据:
(28)
3.4. 算法设计与时间复杂度分析
我们的数据编码算法设计见表2,对于Algorithm 1的时间复杂度如下:步骤1和步骤8至步骤12中计算考虑标签后的任意两个属性之间的条件互信息值花费时间按复杂度为
(这里c是标签数量,
是类别属性数量,nj和nk分别是第j个分类属性的属性数量和第k个分类属性的属性数量);步骤2至步骤6计算每个属性对应的概率向量,时间复杂度为
(这里njp是第j个分类属性的父属性属性值数量)。
4. 实验设计和评估
4.1. 实验设置
4.1.1. 参数设置
在我们的实验中,我们使用多重感知机分类器 [15] (Multilayer Perceptron, MLP)评估后续数据转换学习算法的质量,构造一层隐藏层,最大迭代次数(max iter)设置为1000,激活函数为“relu”函数。
本节给出的所有实验都是在Intel(R) Core(TM) i5-10500 CPU @ 3.10GHz 3.10GHz处理器上执行的,内存为8GB,在Windows 10 Professional x64上运行。MLP和22个编码方法是从scikit-learn的程序包中调用的,scikit-learn是一个广泛使用的用Python实现的机器学习库。实验在Python 3.10环境下运行。
4.1.2. 数据集和预处理
我们基于以下原因使用来自加州大学机器学习领域UCI数据库的18个数据集:1) 这些数据集的样本实例数量差距较大,方便我们比较方法之间的转换效率;2) 它们包括两种属性,即分类属性和数值属性;3) 它们来源广泛,比如医学和商业等。
我们对这些数据集有如下处理:1) 缺失值替换处理,数值属性用平均值替换缺失值,分类属性用出现次数最多的属性值替换缺失值;2) 删除数据集中的重复对象;3) 移除属性值太多或因数据缺失导致只有一个属性值的无用属性(比如“Zoo”数据集中的属性“animal”有100个以上的属性值,“Anneal”数据集中的“exptl”和“ferro”属性只有一个属性值)。我们将经过以上处理后的18个数据集信息总结在表中(见表3)。
Table 3. Description of 18 UCI datasets used in the experiments
表3. 实验中18个UCI数据集介绍
4.1.3. 评估标准
我们使用20折交叉验证的F1得分 [16] 对实验结果的性能进行评价,并在每个单元格中标出平均值 ±标准差,使用置信水平为0.95的双尾t检验 [17] 在统计意义上比较在所有数据集上所有方法之间的显著性差异,并且单元格中的○和●的意义分别是我们的方法与对比方法相比在统计学意义上有显著的退化和改善。每个数据集最好的F1得分加粗。表底部还总结了在所有数据集上的平均值(average),最优F1得分(# of best),Win/Tie/Loss (W/T/L)和平均序值(AR)。W/T/L意义是我们的方法与对比方法相比,赢W个数据集,平T个数据集,输L个数据集。我们还使用箱线图总结F1-score,每个箱体中的直线是该方法的中位线,并且将我们的方法(AWODCPE)的中位线用红色虚线延伸,并标出数值,直观地确定方法的优缺点。
除了以上评估方法之外,我们为了进一步分析AWODCPE在多个数据集上的泛化性能,使用Friedman 检验及其后续Nemenyi检验的统计假设检验 [18]。在使用Friedman检验时,
对应的分布服从自由度为
和
的F分布(这里k是算法个数,
是数据集个数)。若在95%显著性水平下,
值大于对应F分布临界值,则拒绝原假设,表明不同方法之间有显著性差异。最后,我们使用后验Nemenyi检验直观的确定方法之间是否有显著差异。在p值小于0.05时,Nemenyi检验的平均序值差别的临界值为:
(29)
其中
为Tukey分布的临界值。
4.2. 编码算法性能评估
我们从scikit-learn的Category Encoder库中选出4种编码方法与CPT和AWODCPE比较数据编码性能,这4种编码方法如下:
· Ordinal Encoder:顺序编码将分类属性值映射为连续的整数值。
· Target Encoder [19]:由Micci等人于2001年提出,使用参数函数作为加权因子计算对应的数值标签均值和总标签均值的加权平均值作为最后的数值估计。
· Catboost Encoder [20]:由Prokhorenkova等人于2018年提出,计算当前所在行的标签平均值与总标签数之比,并使用先验概率进行平滑处理,处理后的值作为最后的数值估计。
· Quatile Encoder [21]:由Mougan等人于2021年提出,利用对应属性的样本数和正则化参数定义权重,对具有相同标签的样本的p分位数和全局p分位数进行加权,加权后的值作为最后的数值估计。
AWODCPE与以上6种方法的比较结果被总结在表4、图2和图3中,我们将重点做如下总结:
1) 在表4中,AWODCPE的平均的F1得分是最高的(86.87%),与CPT(84.92%)相比高1.95%。我们的方法比其它4种方法高至少3%。我们方法的最高成绩数为12个,远高于其它比较方法。在统计学意义上,我们方法与CPT相比,赢7个数据集,平10个数据集,输1个数据集,明显优于CPT,并且也显著由于其它4个方法。平均排序为1.72在所有方法中最小,仅以平均排序来看CPT与AWODCPE的差距最小。
2) 从图2中可以看出,AWODCPE的箱体上下限差距最小区别于其它5种方法,这说明我们的方法有更优秀的稳定性。并且我们的方法比其他方法有更高的箱体位置和中位线,说明拥有更好的转换性能。
3) 在95%显著性水平下,Friedman检验的 大于临界值
,说明各方法之间有显著区别。因此,我们计算CD值为1.78,并以表4中的平均排序(AR)为基础,在图3中直观表现各个编码方法之间的区别。可以看出AWODCPE最佳,各方法之间有显著性差异,显著优于Ordinal、Target、catboost和Quatile。
大于临界值
,说明各方法之间有显著区别。因此,我们计算CD值为1.78,并以表4中的平均排序(AR)为基础,在图3中直观表现各个编码方法之间的区别。可以看出AWODCPE最佳,各方法之间有显著性差异,显著优于Ordinal、Target、catboost和Quatile。
Table 4. F1-score comparisons for our method versus 6 encoding methods
表4. 我们的方法与6个编码方法的F1得分比较
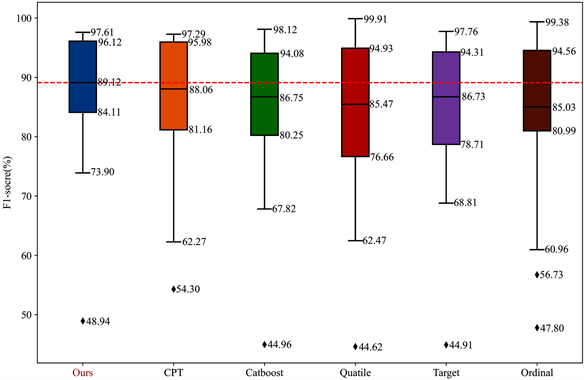
Figure 2. Comparison of AWODCPE with its competitors in terms of F1-score
图2. 我们的方法与竞争者在F1得分方面的比较

Figure 3. F1-score comparison of our method versus its competitors per Nemenyi test
图3. 根据Nemenyi检验,我们的方法与竞争者的F1得分比较
4.3. 时间开销评估
我们将本节实验中,将转换后的数据集输入多重感知机分类器,记录分类器在这些数据集上的时间花费,并结果总结在了表5中。同样地,每个数据集最好的时间花费加粗。从表中可以看出,我们的方法由于维度扩张造成在“census”数据集上的时间花费远高于其他方法,导致拉高了平均值。在其他数据集上,比其他方法的花间花费稍高。
进一步地,我们在95%显著性水平下,计算Friedman检验的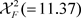 大于临界值
,说明各方法之间有显著区别。因此,我们计算CD值为1.78。同样地,根据表5中的平均排序(AR)画出图4。从图中可以看出,我们方法的时间开销不算理想,但在转换性能和时间成本的权衡之下,是可以接受的。
大于临界值
,说明各方法之间有显著区别。因此,我们计算CD值为1.78。同样地,根据表5中的平均排序(AR)画出图4。从图中可以看出,我们方法的时间开销不算理想,但在转换性能和时间成本的权衡之下,是可以接受的。
Table 5. F1-score comparisons for our method versus 6 encoding methods
表5. 我们的方法与6个编码方法的F1得分比较

Figure 4. Time Cost comparison of our method versus its competitors per Nemenyi test
图4. 根据Nemenyi检验,我们的方法与竞争者的时间花费比较
5. 结论
为了将混合数据应用于数值输入的机器学习算法,需要将分类属性数据转换为数值属性数据,而如何高质量地完成转换,这对于学者们是一大挑战。对于这个问题,本文提出了一种属性加权的独依赖条件概率编码算法(AWODCPE)。它通过建立TAN-tree达到放松条件独立性假设的目的,通过放松后的依赖关系求出条件概率向量,再通过所有属性之间的条件互信息值求出每一个分类属性对应的权重并加权,得到最终的转换数据。在18个数据集上的实验说明了AWODCPE的转换性能比其它5个竞争者更优秀。
虽然AWODCPE从总体上已经取得了很好的效果,然而在如下的部分还可以做进一步改进。例如,在一个数据集中有些属性并不依赖于其他属性,然而为它赋予一个父属性后,可能会降低数据转换质量,所以我们可以寻找最先进的放松条件独立性假设的方法进行改进。或者是寻找一套求每个属性值权重的更有效的方法,从而降低转换过程的时间成本,使其具有更高的转换效率,这些都是我们将来的工作方向。
基金项目
本研究由国家自然科学基金(No. 62166009)、贵州省科技厅自然科学基金ZK [2021]333, ZK [2022]350资助;贵州省卫健委科学基金(No. gzwkj2023-258)、贵州医科大学博士研究启动基金(No. 2020-051)资助。
NOTES
*通讯作者。