1. 引言
随着科学发展的不断进步,智能交通不断发展,辅助驾驶技术成为研究学者重要的研究内容之一。据数据显示,色盲、色弱人群占比达到8%,城市环境中车辆拥堵导致的交通事故发生率高达30%。交通信号灯识别技术的提高可以帮助视力障碍人群更安全地驾驶汽车,同时有效减少行车过程中的交通拥堵问题。准确实时识别检测交通信号灯可以有效解决无人驾驶的安全问题。因此,研究交通信号灯的识别技术不仅具有重要意义,也是未来智能交通研究的热点。
近年来,利用深度学习的目标检测技术得到了广泛的运用。目标检测算法主要分为两大类:基于两阶段(Two-Stage)的目标检测算法,这类算法先通过区域提取(Region Proposal)阶段生成候选目标框(Region of Interest, ROI),然后对这些候选框进行分类和精确定位。典型的两阶段算法包括Faster R-CNN [1] 、R-CNN [2] 、Fast R-CNN [3] 、Mask R-CNN [4] 等。基于单阶段(One-Stage)的目标检测算法直接在图像上进行密集的检测预测,无需显式的区域提取步骤。这类算法直接在图像上进行密集的检测预测,无需显式的区域提取步骤。它们通过在不同位置和尺度上应用密集的锚点(Anchors)或默认框(Default Boxes)来预测目标的位置和类别。典型的单阶段算法包括YOLO (You Only Look Once) [5] 、SSD (Single Shot MultiBox Detector) [6] 、RetinaNet [7] 等。目前,国内外研究人员对已有的现有算法进行改进,以提高对交通信号灯小目标检测的精度和速度。文献 [8] 提出一种基于图像增强的交通信号灯识别方法,通过HSV颜色空间中对颜色通道进行分离并增强V通道分量再合并通道提取交通信号灯的颜色,与传统算法比较识别准确率提升了1.05%,并且有良好的实时性。文献 [9] 提出了基于Matlab的红绿灯识别系统,图片经过灰度化、图像锐化、滤波降噪等预处理,使用直方图阈值分割法有效分割红绿灯,通过二值化图像的矩阵进行红绿灯的定位,基于HSV色彩空间识别出红绿灯的颜色状态,通过样本检测与分析,该模型在普通条件下的红绿灯识别率达80%。文献 [10] 提出改进的Yolov4的交通信号灯倒计时数字检测与识别,通过将CSPResNet50代替主干网络CSPDarkNet53,增加卷积感受野,提高特征提取能力。文献 [11] 提出了一种改进的YOLOX网络来解决多目标情况下的小目标漏检率高、模型特征融合不充分问题,在骨干网络引入特征提取更加细粒度的Res2Block模块,同时嵌入了自注意力机制,增加隐性小目标的区域特征,减少漏检率。
虽然上述算法对于交通信号灯检测性能上取得了一些提升,但还是存在一些问题。首先模型中过多的参数,会使模型降低了推理速度并且很难优化到移动设备上进行使用。其次,交通信号灯周边又有较多的干扰物,模型也容易发生误检。最后,模型在检测精度和速度上很难取得一个平衡。
鉴于上述描述,YOLOv5s [12] 作为一种基于单阶段的目标检测算法,在交通信号灯识别任务中具有实时性、准确性和特征提取能力强的优势,并且YOLOv5s在工业界有大量的使用案例,其稳定性和可靠性都有保障,另一方面,该模型后续需要部署到移动设备,YOLOv5s在移动设备的部署上有一套完善的工具和充分的先验经验可以借鉴,所以选用YOLOv5s进行改进,提高对交通信号灯识别的精度和速度。设计出一种基于多层次跨通道 [13] 并结合倒残差结构的C3模块,替换特征提取网络中的模型,进而减少计算参数与加快网络收敛速度。同时,通过插入优化过后的ECA注意力模块 [14] ,加强网络通道上的相关性,提高对小目物体检测的精度。为了验证改进后YL-YOLOv5s算法的有效性,通过两个公开交通信号灯LaRa和BSTLD数据集 [15] 对模型进行验证,并做了大量对比实验证明了改进算法的有效性。
2. YOLOv5s算法介绍
YOLOv5是一种用于目标检测的深度学习算法,由Ultralytics团队开发,它建立在YOLOv3的基础上通过一系列的改进和优化,提供了更高的检测性能和更快的推理速度。目前YOLOv5算法有五个版本分别是YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,每个版本的网络结构相同,不同的是网络的深度和宽度。考虑到实际的需求,该文检测的任务对检测精度和实时性要求较高,所以选择计算量和参数第二小的YOLOv5s作为改进模型,具体的网络结构图如图1所示。
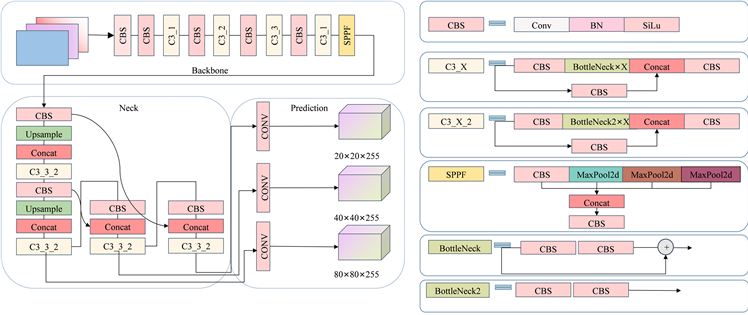
Figure 1. YOLOv5s network structure
图1. YOLOv5s网络结构
YOLOv5s网络结构 [16] 主要由三个部分组成分别是主干网络Backbone、颈部网络Neck和预测网络Prediction [17] 。主干网络采用的是CSPDarknet结构 [18] ,其是一种基于Darknet架构的改进版本,由CBS、C3_X和SPPF(Spatial Pyramid Pooling Fusion) [19] 构建。CBS由卷积、BN(Batch Normalization)层和SiLu激活函数组成,在主干网络中对特征图进行下采样处理。C3_X结构由多个CBS模块和一个BottleNeck模块组成,通过多个残差模块对特征图进行细节特征的提取。SPPF模块是一种通过空间池化实现多尺度特征融合的方法,通过对特征图进行多次最大池化,最后将所有池化层的特征图连接在一起,得到目标更多的语义信息。颈部网络Neck采用了FPN (Feature Pyramid Networks) [20] 与PAN (Path Aggregation Networks)结构,加强了模型的特征提取能力。颈部网络中所采用的C3_X_2特征提取模块与主干网络中有所区别,其中内部结构BottleNeck2结构不采用残差结构,如图1中结构所示。预测网络Prediction中,通过对三个1 × 1卷积对不同的特征图进行处理,就得到了三个不同的检测尺寸(20 × 20, 40 × 40, 80 × 80),每个分支都会输出一个边界框位置和目标类别概率。
2.1. C3_X_2残差结构改进
YOLOv5s颈部网络中运用了4组C3_X_2结构,用于对输入图片进行卷积操作并提取相对应的特征信息。C3_X_2结构中包含了3个标准卷积、1个BottleNeck2模块和连接层,可以有效提取输入图片的高层次特征,增加网络检测的准确性和鲁棒性。但是该结构由于输入特征图通道数较大,通常会需要大量的参数进行运算,并且网络收敛速度也较慢,C3_X_2网络结构如图2所示。
为了更好地解决网络发散和减少参数量的问题,设计了一种基于DenseNet结构的C3_D_2模块。在DenseNet网络中,通过在层之间引入密集连接来改善信息流动,这有助于缓解梯度消失的问题。密集链接允许高效地利用上层信息,使得网络能够在不同深度上重用特征,提高了参数效率并增强了特征传播。相比较于残差连接,DenseNet在更少的参数情况下实现了最先进的性能。密集连接使特征重用成为可能,减少了学习特征的冗余性,使得网络更加紧凑。其核心表达式如式(1)所示:
(1)
其中:xk表示第k层网络的输出;
第0层到第k − 1层网络提取地特征合并;Hk表示为卷积、归一化和ReLu激活函数层地组合方式。Densenet结构如下图3所示。
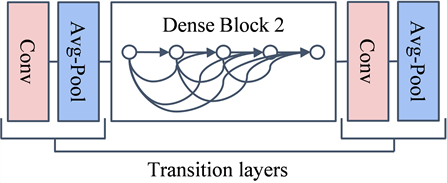
Figure 3. Densent structure diagram
图3. Densenet结构图
C3_D_2结构中采用了1 × 1卷积和3 × 3卷积进行特征提取,不同之处在于,该模块将BottleNeck2替换成了3组MobileNet [21] 进行特征提取。通过跨通道密集连接,使各个模块紧密连接,并且降低了输入通道的维度。这种设计更好地解决了深度学习网络模型退化问题并降低了计算参数 [22] 。C3_D_2网络结构如图4所示。
首先,特征图经过右侧1 × 1卷积处理,将特征通道降低为原来的1/4大小,再经过第一个MobileNet模块进行特征处理,卷积后的得到的特征图信息与输入信息进行特征融合Concat操作,再送入第二个MobileNet模块,按照上面的流程完成三次MobileNet特征提取。最后,经过卷积处理的四个不同层级的特征图被通过Concat操作合并,以恢复特征图的通道数到原来的大小,并与经过左侧1 × 1卷积处理的图像进行特征相加,从而得到最终的特征图。相比较原模型,引入后的MobileNet结构通过跨通道结构,对不同的特征图进行特征融合,能提高对小目标信号灯检测的效果,因为参数的降低也能够提高网络的运行速度。
2.2. 采用MobileNetV2结构
交通信号灯实时检测对于模型速度和精度都有一定的要求,而且网络模型通常需要部署在嵌入式系统或移动设备上。此外,MobileNetV2 结构通过引入一系列轻量级的操作,设计宗旨在保持较高精度的同时减少模型的参数量和计算复杂图,如深度可分离卷积Depthwise Seperable Convolution [23] 和线性瓶颈,加快了模型的推理速度。这对于交通信号灯检测任务至关重要,因为需要在实时场景中快速、准确地检测和分类交通信号灯的状态。MobileNetV2的结构如图5所示。
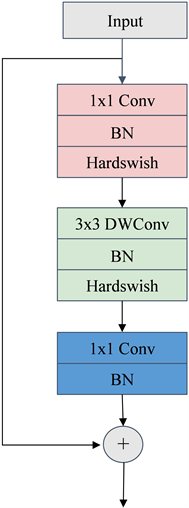
Figure 5. MobileNetV2 structure diagram
图5. MobileNetV2网络结构
在MobileNetV2结构中 [24] ,因为网络使用3 × 3深度可分离卷积,所以减少计算参数量。假设输入特征图片大小为C × H × W,那么网络的总参数量计算公式如(2)所示:
(2)
使用BottleNeck2模块的时候,网络中总参数量计算公式如(3)所示:
(3)
上式中因为C是大于0的整数,可以看出,当特征图输入通道大于1的时候,使用MobileNetV2结构的网络总参数就会比BottleNeck2中正常3 × 3卷积和1 × 1卷积少。
采用MobileNetV2结构的C3_D_2模块,经实验验证在仅扩展两倍输入特征通道层下,也可以提高较大的性能,并且带来较少的计算量。对交通信号灯检测性能提高的同时,也不会增加模型的计算量,加快了网络检测的运行速度。
2.3. 引入改进注意力机制ECANet
交通信号灯图像通常属于小目标检测,其在整幅图片中所占比例较小,因此容易受到复杂背景因素的影响。原YOLOv5s网络在深层次卷积时容易丢失小目标的特征信息,这不利于小目标检测。为了进一步增强图像中的通道信息与交通信号灯的关联程度,丰富关键通道的特征表达,引入了能够将通道信息嵌入特征图的ECANet注意力机制。该注意力机制模块能够提升了模型的表达能力,通过引入通道注意力机制,可以动态地调整不同通道的重要性,使得模型能够更好地捕捉输入数据的重要特征。增强了模型的感知能力,通道注意力机制可以自适应地学习每个通道的权重,使得模型更关注对当前任务有意义的通道。减少了参数数量和计算复杂度,相比于传统的注意力机制,ECANet引入了一个全局的池化操作,通过一个简单的线性变换来学习通道的注意力权重。为了能够使注意力机制更好发挥作用,该文对注意力机制进行了以下两种优化,另外,将全局平均局池化操作替换为全局最大池化 [25] ,利用最大值突出感兴趣区域,突出小目标关键特征。此外,注意力机制中的自适应跨通道信息交互卷积被标准的3 × 3卷积所取代,以进一步优化机制。改进后的ECANet结构如图6所示。
改进后ECANet通道注意力计算流程如下:假设输入特征图为X,大小为W × H × C,其中W表示宽度,H表示高度,C表示通道数。通道维度的全局最大池化可以表现为公式(4)所示:
(4)
其中,Y(c)表示输出特征图中通道c的值,
表示输入特征图在位置(i, j)和通道c上的像素值。则通道注意力模块对通道间权重的计算可以通过式(5)得到。
(5)
其中,
是Sigmoid激活函数,Wk是ECANet中计算通道注意力的参数矩阵。
的计算公式(6),Wk参数矩阵定义式(7)。
(6)
(7)
根据公式(7)可知,yi的计算权重只考虑其周边邻近k个通道。
(8)
公式(8)中,表示yi周边k个临近的集合,所有通道共享相同的学习参数可以提高网络的性能。注意力机制特征通道权重可以通过内核大小为3的一维卷积实现,如公式(9)所示。
(9)
公式(9)中,C1Dk表示卷积核大小为3的一维卷积,使用内核为3的卷积可以加快模型的运算速度。
改进后的ECA注意力机制分别嵌入到4组C3_D_2模块所构成的网络架构中。改进的措施旨在特征融合的阶段对特征图进行处理,从而极大地提升网络在搜索交通信号灯这类微小目标物体时的效能。网络的感知力和定位准确度得到了有益的增强,从而有效地增进了对这类挑战性目标的探测能力。在3.4章节中,提出了2种不同插入方式,并通过实验讨论了不同插入方式对网络检测性能的影响。
3. 实验结果与分析
3.1. 实验数据集介绍
实验使用了BSTLD、LaRa两个交通信号灯数据集进行模型性能验证。LaRa数据集有9168张图片,包含三种不同类别的标签,分别是Green (绿灯)、Yellow (黄灯)、Red (红灯)。由于数据集中有大量重复与模糊的图片,且数据集中Yellow (黄灯)标签类别数量过少,经过处理后保留了5340张图片并添加了192张Yellow (黄灯)图片数据。BSTLD数据集有8334张图片,标签类别跟LaRa数据一样,数据集中也添加了192张Yellow (黄灯)图片数据。上述两个数据集的图片和标签都按8:1:1的比例分为训练集、测试集和验证集。
3.2. 实验环境
实验的操作系统为Windows10,CPU型号为AMD R7 5700X,运行内存32 GB,GPU型号NVIDIA GeForce RTX 3090,显存大小24 GB。模型基于Pytorch1.11.0深度学习框架,编程语言使用Python3.9,使用CUDA11.3进行GPU加速。算法输入大小为640 × 640,batch_size为32,模型优化器选用的是随机梯度下降优化器SGD,初始训练学习率为0.01,权重衰减率为0.0001,学习动量为0.9,训练迭代次数epoch设定为100次。
3.3. 评价指标
实验选取以下指标作为评判标准:mAP@0.5" target="_self">mAP@0.5,是一种通过计算不同类别下,检测算法IoU阈值为0.5时平均精度(Average-Precision);mAP@0.5" target="_self">mAP@0.5:0.95,是将IOU阈值从0.5到0.95,将其以0.05个步长分成若干份,计算各个AP的平均值,AP可以通过P-R曲线面积计算得出;mAP@0.5" target="_self">mAP@0.50:0.95 (small),是数据集中目标像素面积小于32 × 32对应的mAP值,通过这个数值可以反映出模型对小目标物体检测的能力;Frames Per Second是用于评估模型的实时性能和推理速度,较高的FPS值意味着模型能够更快地处理输入数据,从而实现更高的实时性能;GFlops,是指浮点运算数,可以用来衡量算法模型的复杂度。相关计算公式如下:
(10)
(11)
(12)
(13)
(14)
上述公式中,TP代表真阳性(True Positive),指的是被模型正确地预测为正类的样本数量;FP代表假阳性(False Positive),指的是被模型错误地预测为正类的负类样本数量;FN代表假阴性(False Negative),指的是被模型错误地预测为负类的正类样本数量;Cin代表卷积输入张量的通道数,Cout代表卷积层输出张量的通道数,K代表卷积核大小。
3.4. 实验结果和分析
3.4.1. C3_D_2结构改进实验
为了验证不同特征融合对输出特征图的影响,设计了另外两种不同的特征融合方式进行对比实验以C3_D2_2和C3_D3_2表示,验证C3_D_2结构的有效性,各特征融合方式的结构图如图7所示。
三种特征融合方式在LaRa和BSTLD数据集上的评价指标如表1所示(加粗文字表示相同评价指标下的最优结构)。通过对比可以发现,使用ADD进行特征融合方式的C3_D_2模块在不同的数据集上相比其他两种方法表现最优。在LaRa数据集上,与使用Concat进行特征融合方式的C3_D2_2模块相比,使用ADD进行特征融合的C3_D_2模块在GFlops减少了0.53同时,mAP@0.5" target="_self">mAP@0.5、mAP@0.5" target="_self">mAP@0.50:0.95和mAP@0.5" target="_self">mAP@0.50:0.95(small)分别提高了9.2%,5.7%和6.9%。在BSTLD数据集上,使用ADD进行特征融合的C3_D_2模块,mAP@0.5" target="_self">mAP@0.5、mAP@0.5" target="_self">mAP@0.50:0.95和mAP@0.5" target="_self">mAP@0.50:0.95(small)也分别提高了9.6%,4.3%和5.4%。而使用了相乘进行特征融合的C3_D3_2模块,各项性能指标和计算参数量都不及C3_D_2模块。在性能指标上这表明在网络中使用ADD进行特征融合不仅可以减少网络的计算量,还能够增强小目标检测的能力。
进一步分析图8中三种特征融合方式的Loss曲线后发现,C3_D_2模块在第5个epoch之后表现出了更快的Loss下降速度。这表明该模块在结构和参数上更适合解决小目标检测的问题,并具备更强大的表示能力。它能够更好地拟合训练数据并降低损失,同时也能减少网络模型的训练时间。从而证明C3_D_2模块在小目标检测任务中具有较高的性能和效率。经过改进后的模块在其结构和参数方面更为适合解决小目标检测的难题,并且具备更为强大的特征表示能力。这样的模块能够更有效地拟合训练数据,从而降低损失函数的值。与此同时,它还能够显著减少网络模型的训练时间,为模型的训练和优化过程带来明显的加速效果。

Table 1. Performance comparison (%) of three feature fusion methods in YOLOv5s model for object detection
表1. 三种特征融合方式在YOLOv5s模型中检测性能(%)对比
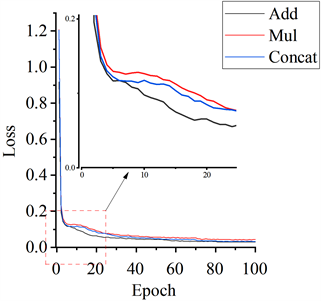
Figure 8. Loss curves for three feature fusion methods
图8. 三种特征融合方式Loss曲线
3.4.2. ECANet结构改进实验
基于ECANet的C3_D_2结构能够通过特征图不同通道,有效选择出有用的特征,并且只使用了很少的计算参数。为了研究ECANet模块对C3_D_2性能上的影响,设计了两组不同的插入方式,如图9所示。
 (a) 插入方式A
(a) 插入方式A (b) 插入方式B
(b) 插入方式B
Figure 9. Two integration approaches for the ECANet module
图9. ECANet模块两种插入方式
两组插入方式在LaRa和BSTLD数据集上的评价指标如表2所示。通过对比可以发现,ECANet模块的插入和池化方式选择的不同,对网络性能指标都有影响。插入方式对性能有显著影响,在数据集LaRa和BSTLD中,网络如果使用了A插入方式,不管是使用了全局平均池化还是全局最大池化,检测性能指标都是优于使用B插入方式。其中数据集LaRa上池化方式相同的情况下都使用了全局平均池化,但选择了不同的插入方式,两者mAP@0.5" target="_self">mAP@0.5的性能最多提升了29.7%。不同池化方式也能提高网络的性能,在两种数据集中,使用了MaxPool2d池化方式相对于AvgPool2d池化方式表现更好。MaxPool2d池化方式mAP@0.5" target="_self">mAP@0.5、mAP@0.5" target="_self">mAP@0.50:0.95和mAP@0.5" target="_self">mAP@0.50:0.95(small)指标上获得了较高的得分。因此,MaxPool2d池化方式可以更好地保留重要的特征信息,提高目标检测性能。所以使用插入方式A和MaxPool2d池化方式的结构可以取得更好的性能。
Table 2. Performance (%) comparison of two integration approaches for ECANet module in YOLOv5 model
表2. 两种ECANet模块插入方式在YOLOv5模型中检测性能(%)对比
为了进一步验证不同ECANet模块对网络的影响,分别绘制了采用不同池化方式的YOLOv5模型的Grad-CAM图像。图像对不同算法在输入图片上进行了可视化处理,以便更好地了解模型在做出决策时的核心图形区域内容。从图10中可以看出,使用了ECA + MaxPool模块进行预测的网络,在感兴趣区域的范围上相较于使用ECA + AvgPool和原始网络更广且更加集中,网络的感兴区域如果更集中于交通信号灯上,这样就能够提供更多有用的特征信息,并排除无关区域的干扰。因此使用了最大池化的ECANet模块,对于小目标信号灯检测特征图更为突出,从而获得更优的检测性能指标。

Figure 10. Grad-CAM images of ECANet with different pooling methods for the same input image
图10. ECANet不同池化方式相同输入图像下的Grad-CAM图
3.4.3. 网络模型消融实验
通过实验分析,对原网络结构分步骤进行改进,改进后的网络模型进行训练并测试,消融实验结构如表3所示。由表3可以看出:在采用了C3_D_2模块和ECA模块替换了原来的C3结构,各项性能指标都有较大的提升,其中用于检测小目标物体的mAP@0.50:0.95(small)提升了9.9%,并且模型计算量还降低了2.74个GFlops,检测速度也提高了5个FPS。由此可见,改进的网络能够较好地实现对交通信号灯的检测与识别,并且满足实时性的要求。
为了进一步验证该文算法对小目标检测的性能优化,在LaRA数据集上将该文的方法与Faster-RCNN、SSD300、YOLO系列等主流算法进行算法性能对比实验,并对不同方法的目标检测性能进行比较分析。表4是不同的实验结果;与两阶段目标检测算法Faster-RCNN相比,单阶段检测算法SSD300和YOLO系列在计算量GFlops上更小,检测速度也更快。与YOLOv7相比,该文算法帧率FPS减少了13帧,但是mAP@0.5提升了0.7%,减少了43.51GFlops,大大减少了算法的计算复杂度。实验数据表明,改进后的YL-YOLOv5s算法可以满足交通信号灯小目标检测的准确性和实时性。
Table 3. Performance (%) comparison of ablation experiments in YOLOv5s model for object detection
表3. 消融实验在YOLOv5s模型中检测性能(%)对比
Table 4. Performance (%) comparison of several detection methods
表4. 几种方法检测性能(%)对比
4. 结束语
在交通信号灯检测领域,复杂的背景环境和高实时性需求一直是一项具有挑战性的任务,导致了现有目标检测算法存在漏检、误检和较慢的检测速度等问题。本文针对这一问题,提出了YL-YOLOv5s的轻量级交通信号灯目标检测算法。该算法引入C3_D_2结构以增强YOLOv5s网络的特征提取能力,采用MobileNetV2替代传统卷积结构以简化卷积过程降低模型参数计算量,以及引入ECANet注意力机制以提高小目标物体的检测精度,同时保持计算效率。实验结果表明,YL-YOLOv5s相较于传统YOLOv5s算法,在减少了23.3%的参数计算量的同时,mAP@50提高了8.5%。尽管该方法在交通信号灯检测方面取得了显著成果,但仍存在一定程度的漏检问题,同时还存在模型大小进一步优化的潜力。