1. 引言
视觉问答(Visual Question Answering, VQA)代表着跨学科研究的前沿,融合了计算机视觉和自然语言处理领域。VQA系统旨在解释和回答关于数字图像的问题,这是一项需要对视觉内容和语言语义进行精准理解的任务。将图像离散化集成到VQA系统中已成为该领域的重要发展。图像离散化涉及将连续的图像数据转换为离散形式,从而促进更高效和准确的分析。这一方法显著增强了VQA系统处理复杂视觉数据的能力,带来了更好的性能和可靠性。
本文旨在深入探讨图像离散化在VQA中的应用。本文探讨这一方法如何将原始图像数据转换为更适合进行分析和与自然语言组件交互的格式。本文将从像素信息离散化和图像语义离散化两个角度分别建模,讨论将涵盖图像离散化的理论基础、在VQA中的应用、其带来的益处以及所面临的挑战。
现实世界的图像通常多变而复杂,包含各种颜色、纹理和物体。图像离散化有助于标准化这些数据,简化对多样化视觉输入进行分析和解释的任务。在图像质量、光照或构图方面不理想的场景中,这种标准化特别有益。图像离散化还提高了VQA系统的效率。处理连续的视觉数据可能会在计算上具有较大的消耗且耗时。通过将图像转换为离散格式,这些系统能够更快速地处理视觉信息,实现更快的响应时间。这种效率对于需要及时响应的应用非常关键。此外,图像离散化促进了先进的机器学习和深度学习模型在VQA中的整合。这些模型,尤其是卷积神经网络(CNNs),在分析离散化的图像方面非常有效。它们能够从这些图像中提取复杂的模式和特征,这对于回答复杂而详细的问题至关重要。图像离散化与深度学习之间的协同作用显著拓展了VQA系统的能力。
2. 背景
2.1. VQA概述
一个VQA模型需要多种技术、工具协作完成,根据这些技术、工具的作用不同可以将VQA模型分为四个阶段,分别为:特征提取阶段(提取图像特征和文本特征);多模态特征对齐阶段;多模态特征融合阶段以及答案预测阶段。提取图像特征需要用到卷积神经网络(Convolutional Neural Network, CNN),如 ResNet [1] 、Faster R-CNN [2] 等;提取文本特征需要用到Glove词嵌入 [3] ,循环神经网络(Recurrent Neural Network, RNN) [4] ,如长短期记忆网络(Long Short-Term Memory, LSTM) [5] 、门控循环网络(Gate Recurrent Unit, GRU) [6] 等;在多模态特征对齐阶段,为了充分的挖掘图像特征和文本特征的关系需要用到注意力机制(Attention Mechanism, AM) [7] ;对于多模态特征的融合需要用到加法、拼接、相乘、多模态低秩双线性池化(Multimodal Low-Rank Bilinear, MLB) [8] 等融合方法;在答案预测阶段选择多层感知机(Multi-Layer Perception, MLP) [9] 进行答案预测。上述的几个阶段中,目前的研究难点在于如何进行多模态特征对齐,也即如何充分的挖掘不同模态特征间的关系,最大程度减少不同模态信息间的语义鸿沟,因此如何搭建一个具有高效跨模态信息对齐能力的 VQA模型仍然是人工智能领域的一个热点问题。如图1所示,目前的基线模型在预测上仍然存在很大问题,即模型的预测分布极大程度依赖于问题,导致answer的分布非常容易向着高频率答案偏移。
2.2. 图像特征提取概述
目前绝大多数的方法,除去在融合部分的注意力机制的添加,都可以归纳为联合嵌入模型。基于联合嵌入的方法是指:将输入的图像和问题映射到相同的子空间进行答案的预测。对于该方法而言,如何将不同模态信息映射到相同的子空间变得十分重要。早期对不同模态特征大多采用线性融合方法,例如:相加、相乘、拼接等方式。Malinowski等人 [10] 提出了一种名为“Neural-Image-QA”的方法,该方法首先使用CNN [11] 提取图像特征,然后将提取出的图像特征与问题中每一个单词的词向量进行拼接产生联合特征,再将该联合特征依次送入到LSTM [5] 中预测答案。Ren等人 [12] 提出的“VIS + LSTM”模型使用了与上述相同的方法,区别在于特征拼接的时候将图像特征看作一个视觉单词,仅与第一个单词的词向量进行拼接,作为第0个时间步的特征输入到LSTM中,而不是每个时间步都进行拼接。大多数的视觉问答模型使用RNN处理文本信息,Ma等人 [13] 针对该特点进行了新的尝试,提出了一种完全基于CNN的视觉问答模型,该模型可以分为3个CNN模块,分别用于提取文本特征、提取图像特征以及多模态特征融合。虽然该方法在主流VQA数据集上表现不是很好,但是为视觉问答模型搭建提供了一种新的思路。
特征提取上,通过grid-feature和通过bounding-box各自的问题。grid-feature会导致图像的语义丢失,而bounding-box的问题则更为隐蔽,如下图2所示,其实图像以bounding-box为基元进行分类会出现一个弊端,即图像的bounding-box存在大量的互相遮掩的情形。

Figure 1. Baseline model prediction and labeling for location issues
图1. Baseline模型对于地点问题的预测和标签

Figure 2. Statistical chart of bounding-box label overlap in Coco dataset
图2. Coco数据集bounding-box标签重叠情况统计图
但是仅仅通过连续神经网络映射辅助以注意力机制去做信息颗粒度的对齐,仍然是困难的。图像离散化,尽管在概念上是一个简单的过程,却在这一领域带来了转变性的变革。通过将连续的视觉数据转换为离散的、可量化的单元,图像离散化使得对视觉元素进行更细粒度和精确的分析成为可能。这种离散化过程在数字图像处理和计算机图形等领域是基础性的,而且在VQA中同样至关重要。
图像离散化的基本前提在于将图像分割成不同的区域或像素,每个区域代表特定的视觉特征。这种分割有助于更有结构的图像分析,使得VQA系统能够以更高的精度解释和回答复杂的视觉问题。这种方法起源于传统的图像处理技术,但随着计算能力和算法效率的进步而有了显著的发展。

Figure 3. Similar semantic image combination
图3. 相似图像语义组合
如上六张图所示(图3),六张图依次为原图,亮度1.5倍,亮度0.5倍,轻微旋转,加高斯噪声,加椒盐噪声的情况。考虑实际图像的获取情况,随着一天时间的光照变化、摄像头的平稳程度,摄像头的清晰程度会依次出现上述这些情况。而这些图像输入进一个连续神经网络的编码器后获取到的特征向量是存在巨大差异的,而从实际的最终VQA模型的推理角度出发,这些图像所包含的语义是十分接近的。这就要求了我们需要以一个全新的方式去看待图像,即怎么能够将这些在像素层面上数值相差巨大的像素基元建模成相同的输入,或者在特征编码阶段完成特征聚类和抽象。
3. 视觉特征离散化
图像离散化建立在涉及数学、计算机视觉和机器学习等多个领域的理论基础之上。其核心概念涉及将图像从其连续形式(与人类视觉感知相一致的表示)转换为更适合计算处理的离散格式。在VQA系统中,这种转换对于对视觉数据的高效分析和解释至关重要。
在VQA的背景下,图像离散化通常涉及将图像分解为像素或段,每个表示不同的属性,如颜色、纹理或强度。这些离散元素成为特征提取的构建块,是解释图像内容的关键步骤。特别是基于卷积神经网络(CNNs)的特征提取算法利用这些离散元素来识别和分类与提出的问题相关的视觉模式。
3.1. 像素离散化
本文使用了基于颜色的离散化、基于纹理的离散化、基于强度的离散化和基于空间的离散化。
3.2.1. 颜色离散化
对RGB颜色进行量化可以使用以下公式:
(1)
其中,
是量化后的颜色,
是原始颜色,Q是量化级别。
3.2.2. 纹理离散化
当涉及到局部二值模式(Local Binary Pattrns,简称LBP)时,其计算过程可以用一下的方式表示:
假设我们考虑一个图像中的一个特定像素点P,并以其为中心,选择一个半径为R的圆形邻域。在这个邻域内,选择P周围的N个像素点(通常均匀分布在圆周上),然后比较这些像素的灰度值与中心像素P的灰度值。
1) 对于这些邻域像素点中的每一个像素Pi,其中
;
2) 计算Pi的灰度值与中心像素P的灰度值的差异。
3) 如果Pi的灰度值大于或等于中心像素P的灰度值,则将Pi对应的位置记为1,否则记为0。
4) 将所有的0和1连接成一个二进制数串(可能的长度是N),形成一个二进制模式。
5) 将这个二进制模式转换为十进制数值,作为中心像素P的新值。
这个过程可以用一个数学公式表示为:
(2)
其中
是一个函数,表示与中心像素P相邻的像素点的灰度值与中心像素的比对结果。如果Pi的灰度值大于或等于中心像素P的贵渎职,则
,否则
。
P是中心像素,R是邻域半径,N是选取的邻域像素点数。
LBP的公式描述了如何从图像中提取局部纹理特征,并将其编码为具有不同模式的整数值,这些特征可以用于图像识别、纹理分析以及其他计算机视觉任务。
3.2.3. 强度离散化
对图像强度进行二值化(Binarization)是一种基本的离散话方法。一种简单的二值化公式是:
(3)
其中,
是二值化后的图像,
是原始图像的强度,T是阈值。
3.2.4. 空间离散化
本文中,使用卷积函数辅助硬编码池化层完成空间离散化。
3.3. 语义离散化
卷积神经网络(CNN)特征提取:
(4)
其中,
是卷积后的特种图中的一个元素,
是输入图像中的像素,
是卷积核中的权重,
是区别于常规sigmoid函数以外的硬编码激活函数,用于离散化。
在VQA中,有时需要将图像和问题的信息联合表示。一种方式是使用注意力机制,其中图像特质和问题特质被赋予不同的权重。注意力机制的公式可以表示为:
(5)
其中,
是第i个特征的注意力权重,
是与该特征相关的能量分数。
4. 基于图像离散化的VQA模型
将上述图像离散化技术以并行方式融合到本文的VQA模型中,模型整体结构如下流程图4所示。
本文输入来自COCO数据集的图像进行编码,首先经过图像像素离散化模块,在该模块,PDID模型会并行的进行空间离散化、纹理离散化、强度离散化。空间离散化本质来说是将临近像素进行聚类,强度离散化则是让图像在整张图的层面上分离出光照度等亮度信息,而纹理离散化则是侧重于图像共性的局部细节并作保留。随后联合编码得到的特征向量会输入进图像语义离散化模块,在该模块,图像一方面通过常规的卷积神经网络和RPN网络完成特征提取,另一方面通过grid-feature的形式对图像的语义进行权重的再分配,最终通过模态内的注意力融合以上两种视觉特征,再通过跨模态注意力融合图像和文本特征,最终完成输出。模型的模态内和模态间注意力结构如图5所示。
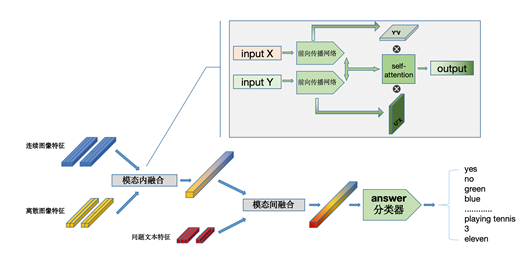
Figure 5. Structure diagram of intra-modal attention and inter-modal attention
图5. 模态内注意力和模态间注意力的结构图
注意力机制的结构如上所示,我们定义了一种双线性融合的方式,该注意力能够很好的平衡所有特征向量之间的关系,这种双向的权重再加权保证了最终每一个特征都能融合尽可能多的不同层次的信息和不同模态的信息。
5. 实验
5.1. 实验数据集
VQA v1是第一个广泛采用的VQA数据集。它包含248,349个训练问题、244,302个测试问题和121,512个验证问题。从Microsoft COCO数据集中获取了204,721张自然图像。VQA v1中的问答对是基于人类注释者进行注释的,包含三种类型的对应答案,即“是/否”、“数字”和“其他”。VQA v1数据集由开放式和多项选择两个子任务组成。VQA v2是VQA v1的扩展版本,其重点是通过平衡对减少数据集偏差。整个数据集包含443,757个训练问题、214,354个验证问题和447,793个测试标准问题。每个问题都会由人工注释者生成10个自由回答答案。提供基于准确率的评估指标来预测。回答评分根据以下公式给出:
(6)
其中A是不同注释者提供的答案的数量。如果预测答案由三个以上注释者给出,则相应得分为“1”。COCO-QA是根据Microsoft COCO数据集创建的,该数据集小于VQA v1和VQA v2。该数据集包含66.9%的训练集和33.1%的测试集。整个数据集包含69,172张图像、92,396个问题和435个答案。问题分为四种类型:“物体(69.84%)”、“数字(16.59%)”、“颜色(7.47%)”和“位置(6.10%)”。此外,采用Wu-Palmer相似度(WUPS)作为附加指标来测量真实答案与预测答案之间的语义距离。WUPS分数设置为0.0和0.9。VQA-CP v2是从VQA v2重组而来的,它改变了答案的先验分布,以减少训练和测试分割中面向问题的偏差。具体来说,它包含121k个图像、438k个问题和440万个训练集答案。VQA-CP v2的测试集有98k张图像、220k个问题和220万个答案。
5.2. 实验参数
本文模型使用Resnet-101作为backbone来初始化整个网络,该网络加载来自ImageNet上预训练后的模型参数辅助训练。对于单词特征,我们将所有问题用0填充到最大长度14,并通过BERT提取14 × 768作为问题嵌入Q。BERT模型在Wikipedia (2500M)和Books Corpus (800M Words)上进行了预训练。融合视觉和文字特征后,我们通过全连接层将它们转换为1024维。多头注意力的数量设置为8。对于优化模型,所有全连接层使用0.5的dropout率。所有梯度均被裁剪为0.5,批量大小固定为128。所有模型均训练200个epoch,初始学习率为lr = 0.001,并且预热比率设置为1/3。选择随机梯度下降(SGD)作为优化器,动量为0.8,权重衰减为10−3。我们的操作是通过PyTorch 1.11.2和Tensorflow 2.4.0实现的。所有代码都在四个NVIDIA A100 GPU上运行。训练网格单元时每张图像花费0.026秒。每个图像的像素离散化计算时间为0.012秒。在整个训练过程中,每一步需要0.29秒,30个epoch总共需要11.3小时。
5.3. 实验结果
模型的训练准确率和损失函数值如图6所示,模型在30个epoch后逐渐平稳,证明模型收敛。
表1、表2、表3是模型在VQA-v2.0,COCO-QA,VQA-CP v2数据集上的表现结果,模型基本都取得了sota的效果。

Figure 6. Model training accuracy and loss value chart
图6. 模型训练准确率和损失值图

Table 1. Comparative experimental results of PDID model on VQA-v2.0 data set
表1. PDID模型在VQA-v2.0数据集上的对比实验结果
Table 2. Comparative experimental results of PDID model on COCO-QA data set
表2. PDID模型在COCO-QA数据集上的对比实验结果
Table 3. Comparative experimental results of PDID model on VQA-CP v2 data set
表3. PDID模型在VQA-CP v2数据集上的对比实验结果
5.4. 消融实验
5.4.1. 离散模块消融实验
本文对PDID做了三组消融实验,分别验证了backbone对模型结果的影响,注意力头数的影响以及离散化模块有效性的验证。
5.4.2. backbone结构消融实验
数量问题的解决没有能够得到很好的处理,因为对于vqa-cpv2数据集,数量问题的准确率一向很低,而本文的离散化模块,并不会对数量问题造成太大的影响,所以本文认为对于数量问题是需要一些更新颖的架构,仅仅通过对实例背景的分割等途径对于数量问题依然不是一个很好的解决思路。根据表4可知,resnet101比resnet50,能够更有效的提取图像的深层特征,所以效果都有不同程度的细小的上升。本文的方法在vqa1.0上的提升最小,原因可能是vqa1.0本身的数据集的回答就比较依赖文本特征,对于图像特征的提取要求不算高。而后续的新的数据集如vqa2.0 vqa-cp等,都是对数据集分布做过调整的,需要更好的提取并融合图像特征。
5.4.3. 注意力头数量测试
如图7所示,注意力的头数越多,模型表现越好,但是同时需要综合考虑模型训练的参数量和训练时间。
Table 4. Test-dev and test-std indicators of the PDID model under different backbones on four data sets
表4. 不同backbone下的PDID模型在四个数据集上的test-dev和test-std指标

Figure 7. Number of attention heads on model performance on different datasets
图7. 注意力头数在不同数据集上对模型表现的影响
5.4.4. 离散模块的消融测试
Table 5. Test-dev and test-std indicators of the PDID model with PD or ID on four data sets
表5. 有无离散模块的PDID模型在四个数据集上的test-dev和test-std指标
PD模型指的是只有pixel-discretization的模型,而ID模型相应的指的是只有instance-discretization的模型,而PDID则是本文的原模型,我们通过消融实验表5来观察像素离散化模块和语义离散化模块的有效性。最终发现像素离散化是十分重要的,如果没有像素离散化,只有语义离散化模型表现极差,这是因为语义离散化依赖于像素离散化模块得到的输出,离散的端到端输入输出是重要的。而没有语义离散化的模块表现相较来说差异不大,这说明对于语义的离散化仍然需要更精细的模型来建模。
5. 总结与展望
在视觉问答(Visual Question Answering, VQA)系统中实施图像离散化带来了几项显著的优势。首先,它提高了VQA系统的准确性。另一个优势是对复杂视觉数据的改进处理。现实世界的图像通常多变而复杂,包含各种颜色、纹理和物体。图像离散化有助于标准化这些数据。
尽管存在这些优势,但在VQA系统中实施图像离散化也面临挑战。其中一个主要挑战是平衡离散化过程中保留的细节水平。过多的细节可能导致计算效率低下,而过少则可能导致丢失对于准确解释所必要的关键信息。此外,将多样且复杂的现实世界图像离散化为标准化格式的过程可能具有挑战性,需要精密的算法和谨慎的校准。
另一个挑战是在多样化和不受控制的环境中准确解释离散化图像。现实世界中的图像在质量、光照、透视和构图方面可能有很大的变化。确保离散化过程始终捕捉到这些不同图像的关键特征是一项复杂的任务。这种变异性可能影响系统的泛化能力,使其在不同类型的图像上准确回答问题的能力受到影响。
图像离散化与VQA系统的其他组件(如自然语言处理和深度学习算法)的整合也带来挑战。确保这些组件之间的无缝交互对系统的整体性能至关重要。视觉和文本数据表示的不一致可能导致误解和错误答案。实现有效地将视觉分析与语言解释相结合的和谐整合仍然是研究和发展的一个关键领域。
总的来说,图像离散化显著提升了VQA系统的性能。它提高了准确性,更有效地处理复杂的视觉数据,提高了计算效率,并使先进的机器学习技术得以整合。这些优势使图像离散化成为VQA技术持续发展和完善中的关键组成部分。
致谢
在完成本论文的过程中,我要衷心感谢所有给予我支持和帮助的人。首先,我要感谢我的导师孙杳如教授,他给予了我宝贵的建议、专业的指导和无私的支持,使得我能够顺利完成这篇论文。他们的耐心指导和鼓励对我在研究过程中起到了至关重要的作用。我还要感谢实验室的同事和其他教授/同学们,在研究和讨论中给予了我很多启发和帮助,使我的研究更加丰富和深入。此外,我要感谢我的家人和朋友,他们在我写作过程中给予了我精神上的支持和鼓励,让我能够专注于论文的完成。最后,我要感谢所有曾经为本论文提供帮助的人,尽管我无法一一列举,但你们的支持对我而言是非常宝贵的。感谢你们在我学术道路上的陪伴和支持。
参考文献