1. 问题的提出
矩阵Cholesky分解的算法是数值线性代数的一个重要内容,其在最小二乘、线性回归、非线性优化等科学计算问题中具有广泛的应用。Cholesky分解 [1] 源于矩阵的LU分解,即对对称正定矩阵
,存在唯一的对角元素皆为正的下三角矩阵
,使得A可以分解为
。为了增强数值稳定性,2002年,Hammarling [2] 提出了全主元的Cholesky分解。2004年,Gu和Miranian [3] 又提出了Cholesky分解的秩显算法。2016年,Xiao和Gu [4] 提出了Cholesky分解在分块形式下的低秩逼近算法,进一步给出了谱显分解算法,从而使得算法变得高效稳定。然而,这些确定性算法在矩阵的低秩逼近分解中时间成本过高,导致算法的效率较低。为了改进这些不足,文献 [5] 提出的主元随机Cholesky分解算法不仅有很好的低秩逼近效果,而且节省了大量时间成本。
但是这类随机算法的通病都是至少需要读取输入矩阵两次。而面对存储在内存外部的大规模数据和流型数据时,往往只有一次读取数据的机会。于是就有学者提出将单pass随机算法应用到矩阵分解的低秩逼近随机算法中。2011年,Halko和Martinsson等 [6] 首次提出了将单pass随机算法应用到矩阵的特征值分解,而后Tropp和Yurtsever等 [7] [8] 提出了一种新的SVD分解的单pass随机算法。接着,在2020年Li和Yin [5] 提出了LU分解的单pass随机算法。在此基础上,本文从随机矩阵投影的角度构造了一种新的随机算法——Cholesky分解的单pass随机算法,并给出了相应的误差上界。同时通过数值实验对Cholesky分解的几种算法进行了比较。
2. 预备知识
定义1 [9] 设
,
,
,亚高斯随机矩阵
是一个由所有
阶随机矩阵
所构成的矩阵集,A中的元素皆为服从i.i.d.的随机变量,且满足下述三个条件:
1)
;
2)
;
3)
。
注1 从文献 [9] 可知,如果A是
阶亚高斯随机矩阵,则有
,且
,若矩阵
其中
,有
,且
。
引理1 [9] 若矩阵
,参数m,n满足
,则存在正常数c1,c2使得
成立。
注2 由文献 [10] ,可知引理1中参数c1,c2的确切值:
,
,
其中,
,
,
,
。
引理2 [11] 设矩阵
的SVD分解为
,随机矩阵
列满秩,
有thin-QR分解
,
的分块形式为
,其中
,
。设
行满秩,r是目标秩且满足
,
,则有
3. Cholesky分解的单Pass随机算法(SPRCH)和误差界
3.1. Cholesky分解的单Pass随机算法
本节基于LU分解的单pass随机算法,介绍了一种新的Cholesky分解的单pass随机算法,与算法1相比,它即保留了在低秩逼近算法中较好的效果,又只需对A访问一次,大大的节约了计算成本。类似于算法1的构造,我们可以给出算法2的具体思想如下:
我们可以根据
,然后考虑将算法1中的
的A替换掉,我们将等式两边同时左乘
,右乘
得到:
因此我们得到
又因为
将等式两边同时左乘
,右乘
,我们得到:
然后我们得到B的一个近似值:
因此我们就得到了一个新的算法Cholesky分解的单pass随机算法(SPRCH)
取流型数据
,
,则可通过以下更新公式计算:
,
,
.
3.2. 误差分析
接下来估计
的上界,取特殊的p值0,首先对
做thin-svd分解
,其中
,
,
,即可得到
由于P是置换矩阵,且
为列正交矩阵,因此,
是一个Gaussian随机矩阵,由引理1,有
成立的概率不低于
。
类似地,有
成立的概率不低于
,则
成立的概率不低于
。接下来估计
的上界。
对算法2,考虑对PY进行QR分解,即
,则相应的可以得到
,此外将引理2中的
用算法2中的
替换,同时取特殊的p值0,则有以下结论成立:
综上所述,可以得到算法2的误差界有如下结论。
定理1 在算法2的假设条件下,Cholesky分解的随机算法误差界满足:
成立的概率不低于
。
4. 数值结果
4.1. 不同过采样参数选取对于算法的精度及运行时间的影响
取固定阶数为1000 × 1000的奇异值快速下降的数据矩阵A,对于不同的参数用两种随机算法做十次独立的实验,并记录误差和运行时间分别取平均值为
和
,
和
。
从图1中可以看出两种算法的误差精度都很高。但随着p值增加,SPRCH的误差逐渐减小而RCH的误差逐渐增大。图2中可以发现SPRCH在时间成本上更有优势。需要指出的是,大规模数据计算中读取成本比算法运行成本高很多,新算法SPRCH只需要读取原始矩阵A一次,而RCH至少要读取两次,新算法总体成本比RCH算法成本低。
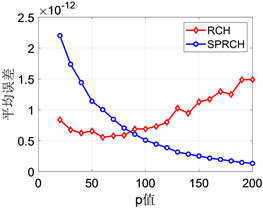
Figure 1. Error line chart for two algorithms for p from 20 to 200
图1. 参数p从20到200时两种不同算法的误差折线图

Figure 2. Line chart of running time for two algorithms for p from 20 to 200
图2. 参数p从20到200时两种不同算法的运行时间折线图
4.2. 不同规模矩阵对于算法的精度及运行时间的影响
根据上节选取合适的过采样参数,将这两种不同的算法和matlab中自带的Cholesky分解作比较,进行独立的十次实验,然后记录运行时间及误差分别取平均值为
、
、
和
、
、
。

Table 1. Comparison of three algorithms under different scale matrices
表1. 不同规模矩阵下三种算法的比较
从表1可以看出,随着矩阵规模不断增大,本文所提算法——Cholesky分解的单pass随机算法相对于传统的Cholesky分解以及主元随机Cholesky分解(RCH)算法在时间成本和误差上有着较大的优势。故新算法在应对大规模数据和流型数据矩阵的问题中有更好的应用前景。