1. 引言
根据CNNIC第52次《中国互联网发展状况统计报告》表示,截至2023我国网络购物用户规模达8.84亿人,较2022年12月增加3880万人,占网民整体的82.0% [1] 。而接近饱和的网购渗透率意味着消费者的需求将开始从低端基础服务向高端定制化服务转变,面对市场红海,电商企业更需要围绕顾客需求对自身产品进行更加精细的改进优化 [2] 。
目前,KANO与IPA被普遍用于满意度相关研究中。Kano模型基于顾客满意度感知情况来反映不同需求和顾客满意度之间的关系 [3] 。然而,KANO模型由于受访者对某要素的感知和其占比的影响,存在主观性的不确定性,因此有时候难以准确反映出该要素的真实满意度 [4] [5] [6] [7] [8] 。而IPA根据用户的满意度及产品的重要度评价满意度,并制定产品/服务的改进优先次序及策略 [9] ,尽管IPA广受欢迎,但仍存在若干缺点影响受访者对要素重要性的判断:产品属性重要度和客户满意度之间线性对称关系的错误假设、产品属性重要度测量存在误差、产品属性之间独立的错误假设等 [10] [11] [12] 。由于IPA与KANO均基于满意程度对指标进行分析,也有很多学者将两者进行结合 [13] ,但相比机械组合两种模型在一起,Kuo等提出了一种IPA-KANO模型 [14] ,杜煜则利用该模型对地铁出入口设计要素进行了研究。IPA-KANO模型结合了KANO模型对要素进行分类和IPA模型判定改进次序的优势,虽然提高了分析效率和决策效果,但分类规则模糊、自述评价度较主观等问题仍然存在。
而针对顾客需求研究,具有规模大且自发性特点的在线评论则为其提供了天然的理想数据,比起基础的调查问卷收集数据,在线评论作为用户直接生成内容更真实地反映了其体验 [15] ,大大提高了研究可信度,已有研究通过在线评论挖掘完成了对消费者偏好的测度 [16] - [21] 。一些学者在对在线评论进行分析时结合了Kano模型来判断顾客需求,如赵宇晴等先将基于模糊理论的Kano模型与情感分析结合构建需求–满意量化模型,完成了客户需求的分类 [22] 。李贺等用LDA模型挖掘手机在线评论特征,有效识别需求要素,再根据Kano模型设计调查问卷,确定顾客各类需求重要度和供给优先顺序 [23] 。Bi等基于LDA模型提取产品属性,使用SVM模型对产品属性进行情感分析,再使用神经网络模型来分析不同的产品属性对消费者满意度的影响,最后根据Kano模型将消费者进行产品属性的需求划分 [24] 。Xiao等提出一个基于产品在线评论来衡量消费者需求偏好的经济计量模型。通过对手机在线评论内容的情感分析和改进的有序选择模型来确定消费者的总体偏好,并提出基于边际效应的Kano模型,增加了发散型需求、逆向需求和需创新的需求类型 [25] 。而孙玲玲等在LSTM-LDA融合算法的基础上加入时间参数,通过在IPA模型中计算主题热点的满意度和关注度得到了相关发展趋势 [26] 。Bi等则通过IOVO-SVM确定用户需求及相应情感值,以分析结果为依据带入IPA模型,为酒店服务制定个性化改进建议及对策 [27] 。
基于此,为改善传统满意度模型分类受主观影响的缺点,本文结合Ying F K等人在2012年提出的IPA-KANO模型研究成果,基于在线评论提出一种新的IPA-KANO模型改进方法,旨在优化其指标分类能力,并通过与在线评论的结合,在特征挖掘的基础上研究电商产品顾客需求挖掘问题,并设计对应改进方案。
2. 基于情感分析的IPA-KANO模型构建
本研究爬取相关在线评论数据,并通过逆文档频率和Word2vec深入语义层面生成词向量,利用改进后的K-means算法进行特征提取,结合评论情感分析结果设计IPA-Kano模型指标,最后结合情感度和关注度进行电商产品需求分析,再针对模型结果给出相应的设计改进。具体设计流程如图1所示。
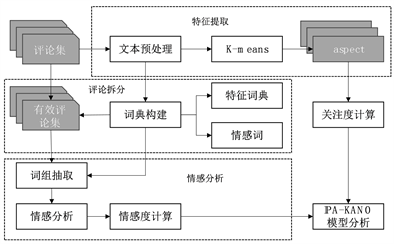
Figure 1. Text mining and requirements analysis process based on online reviews
图1. 基于在线评论的文本挖掘及需求分析流程
2.1. 改进后的K-means特征属性提取
在通过初步的在线评论数据预处理后,在使用K-means进行文本聚类时,K-means的聚类结果受初始簇中心的随机确定的巨大影响,聚类结果有时可能会收敛到局部最小,产生空簇,所以为防止聚类过迭代,对传统K-means确定k簇的方法做出了改进,简单概括就是:依次选取k个簇中心,判定依据为距离之前选定的簇中心越大的点被选为下一个簇中心的可能性越高。具体步骤为:
a. 初始化质心,从输入集合中随机选择一点作为第一个聚类中心;
b. 对于剩余每一点xi,计算它与最近聚类中心的距离Txi;
c. 为使聚类中心尽可能分散,选择Txi最大的数据点作为新聚类中心,且Txi越大,被选取作为下一个聚类中心的概率越大:
(1)
其中,
为点xi被选中为下一轮循环的簇中心的概率,txi为每个点到所有类簇中心的最短距离。
d. 重复上两步直至数据集中所有样本点到所属聚类质心的距离之和J为最小,聚类结束:
(2)
经过这一改进后,可以有效降低簇内误差平方求和得到的损失值,使数据最大化地收敛到全局最优减少迭代,还可以避免出现空簇。
2.2. 情感分析
本文基于K-means聚类后产品每个主题所表示的若干个特征属性词来组成产品的属性词典。先按基础标点符号把顾客在线评论划分为单元句,根据在线评论的语言特征,一般一个单元句里只包含消费者对一个产品属性的评价。再选用知网HowNet情感词典作为构建情感词典的基础词典,并在此基础上增加评论领域相关的词汇,情感词典中标记了情感词的极性和强度。其中,程度副词参考不同文献的研究成果,本文将程度副词强度划分为6个层级,否定副词划分为2个层级 [28] [29] [30] 。
以<特征词,情感词>词组的抽取在词标注的基础上,参考文献 [31] [32] [33] 情感分析算法设计进行情感强度计算。抽取出的词组中包括特征词、情感词以及与情感词相邻的副词(如果存在)。特征情感值的计算以单元句为基本单位,再把同属一条评论的属性情感进行汇总,具体公式如下:
(3)
(4)
其中,Si_pos表示评论中对第i个特征的正向情感值,n(Si)表示i个特征的特征词总数,
表示抽取出的<特征词,情感词>词组中属性i的第j个特征词的正向情感值,由词组中情感词的情感强度来衡量。若词组中有否定副词则按负向情感计算。adv代表词组中的程度副词强度,若词组中无程度副词,则adv = 1。
Si_neg表示评论中对第i个特征词的负向情感值,
表示<特征词,情感词>词组中特征i的第j个特征词的负向情感值,由词组中情感词的情感强度来衡量。
2.3. IPA-KANO模型构建
假定F表示产品集合,即
;I表示产品特征属性的集合,即
;i表示产品特征属性下的特征词,即
;T表示评论的集合,即
,则
为第k款产品的第I个特征属性,
为第k款产的第I个特征属性上评论数量,其中
。
为更契合在线评论文本数据特点,本文引入特征属性I的情感度SenI作为模型隐性重要性判断依据,SenI越高,则特征属性I上顾客整体满意度越高,反之则越低。
(5)
(6)
其中,ni为含有特征词i的评论数,
,
。
引入消费者对指标I关注度作为显性重要性判断依据,先计算产品特征占比 [34] ,即指标I在不同款式产品中被关注的平均程度,具体计算公式为:
(7)
式中,Tk为第k款产品所有特征属性上评论短句总数,
表示关于第k款产品的第I个特征的评论数。通过计算产品特征占比,可以看出在一系列产品中,该产品相应特征属性受顾客关注的关注水平。
基于上述产品属性占比数据,通过依次比较不同产品中的特征属性关注度,可以得到该产品特征属性的整体关注度AttI,即评论中特征属性I在各款产品评论中被关注程度的均值:
(8)
(9)
为常数,若第I个产品特征在第k款产品的评论中占主要地位,则
,反之为0:
(10)
可以看到,AttI越高,则特征属性I上整体关注度越高,即该特征越受消费者关注,反之则越低,越不受消费者关注。
根据KANO模型的需求定义及IPA模型的矩阵,以归一化处理后的SenI为竖轴,AttI为横轴构建IPA-Kano的象限图,具体如图2所示。
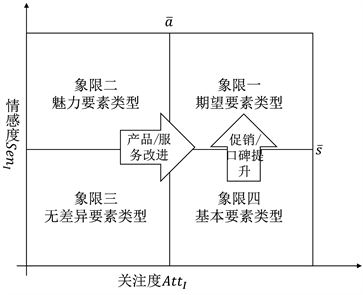
Figure 2. IPA-KANO model matrix diagram
图2. IPA-KANO模型矩阵图
(1) 象限一:期望要素类型。顾客对该象限的被测特征属性的关注度和情感度都很高,针对该区域,应继续保持高产品口碑和维持产品质量,保持顾客体验。
(2) 象限二:魅力要素类型。位于该象限的被测特征属性,顾客关注度较低,情感度很高,所以应采取根据消费者具体评价提升和改进产品细节质量的策略,逐步向象限一发展。
(3) 象限三:无差异要素类型。位于该象限的被测特征属性的关注度和情感度均低,应通过提升口碑或质量先向象限二或四优化靠拢,但在企业资源有限的情况下应先减少关注。
(4) 象限四:基本要素类型。位于该象限的被测特征属性的顾客关注度较高,情感度较低,可能过度表现,在保持高关注度的同时,可以采用更新、促销等手段提高顾客的实际体验。
3. 实证分析
本文选择具有代表性的宠物猫粮产品作为在线评论文本分析的研究对象,通过市场调查顾客大致品牌倾向,再运用基于Python开发的八爪鱼爬虫软件,分别获取京东网络购物平台上六个品牌的宠物猫粮在线评论,通过初步筛选,最终选出共22,984有效评论,评论时间约从2018年至2023年,如表1所示。

Table 1. Jingdong domestic cat food crawling data source
表1. 京东国产猫粮爬取数据源及部分评论信息
顾客评论中使用的词汇具有明显的“长尾效应”,因此需要对评论数据进行预处理。首先使用基础Python代码对评论文本进行简单去重。其次,由于评论文本主围绕京东商城的某品牌猫粮进行评价,其中“京东”、“猫粮”等词出现的频数较大,但会干扰需求挖掘的准确性,因此同样使用代码去除。对文本进行清洗,最后用JIEBA进行分词和词性标注,使用百度中文停用词表对停用词进行删除。
3.1. 特征属性提取
猫粮评论特征词聚类的方法步骤如下:
(1) 使用TF-IDF算法对文本进一步筛选得到词频高符合主题的优质词源。
(2) 使用Word2vec模型,选择CBOW模式,windows = 5,size = 20,计算各个特征向量,通过基础语料库训练得到分词向量。
(3) 基于模型构建中的K-means算法对词向量进行聚类,根据SSE肘函数算法确定K = 5,提取聚类特征和每个特征下具体的特征词如图3和表2所示。

Figure 3. Improved K-means clustering plot
图3. 改进后的K-means聚类图
Table 2. Preview of theme section feature words
表2. 主题部分特征词预览
根据表1中每聚类词频前10的特征词,经人工确定各聚类主题名称,为了更加细分消费者需求,归纳主题下相应特征属性名称,分配对应特征词,详见表3。
Table 3. Feature attribute overview
表3. 特征属性总览
3.2. 情感分析
为对各类特征属性进行IPA-KANO模型分析,本文对聚类主题中的特征词做进一步阐述,使各个主题中各被测指标要素的涵义更加具体,并利用Python程序代码计算情感值。首先读取对应的情感词典文件,构建适应研究数据的词典,其次导入语库将其转化为字典对象,其中部分情感观点词和强度副词如下表4、表5所示。
Table 4. Preview of selected opinion words
表4. 部分观点词预览
最后输入预处理后的评论语料计算,根据公式(3) (4)得到如表6的数据结构。
Table 6. Example of comment sentiment analysis results
表6. 评论情感分析结果示例
3.3. 基于IPA-Kano模型的猫粮产品需求分析
基于上述,根据公式(5)~(8),计算各特征属性情感度和关注度得分如表7所示。
Table 7. Score for each characteristic attribute
表7. 各特征属性分值
最后结合上述两项指标得分,绘制出基于IPA-KANO模型的猫粮产品需求分析象限图,如图4所示。
图4中位于第一象限的特征属性包括:客服服务D1、适口性A1、软硬程度A4、性价比E1、产品外包C2和物流服务D3。这类指标显性隐性重要性都很高,因此此类指标对该产品消费者来说非常重要,且影响这顾客对产品的整体评价。其中D1、A3和D3重要性相对最大,表明良好的服务和口感对产品提升顾客的满意度效果最佳,由于这6类指标顾客对它们的总体口碑和满意度都很高,所以此类指标需继续保持目前的质量与品质,后续可以高性价比为切入点对产品进行宣传。
位于第二象限的特征属性包括:新鲜度B3、颗粒大小A2和产品内包C1。该类特征属性的好坏一般不会影响顾客的购买意愿,但提升此类指标的满意度仍有促进销售的巨大价值空间。此类这些用户需求要素是区别于其他同质产品提升用户的满意度的重要突破点,属于顾客潜在需求,产品生产企业若想进一步扩大猫粮生产规模,提高客户粘性,就必须改进位于该象限内的特征,以求在竞争中脱颖而出。在进行产品设计时,企业在第一象限指标均满足的基础上,优先提供高魅力型需求,在资源充足的情况下再考虑低魅力型需求是否提供。例如:在新鲜度方面,国产猫粮可以把猫粮保质新鲜作为吸引顾客的魅力型营销点。同时,针对产品内包等魅力型顾客需求点,商家企业可以加大研发投入,通过改善产品过度包装、重复包装等问题,使用绿色环保包装等为营销推广的亮点,吸引用户关注。
第三象限的特征属性包括:香味A3、品牌效应E3和赠品与折扣E2。一般情况下,这类指标隐性和显性重要性均比其他指标低,能产生这种情况的原因有很多,比如猫粮香味对人类来说可能是个重要考虑因素,但对于真正的产品受众群体猫咪来说,香味的刺激并不大;再比如品牌效应指标,由于目前国内猫粮销售市场仍处于国外品牌垄断阶段,能选购国内产品的顾客相对于其他考虑因素,品牌对购买意愿的影响程度就较小等。总体说明上述三类特征属性对改进猫粮产品性能,提高顾客口碑和满意度的作用不大,在企业资源有限的情况下可以先不对这类指标进行改善,但仍应持续关注这些属性,在资源充足的情况下有序改进,以提升市场竞争力。
第四象限的特征属性包括:毛发情况B1、肠胃情况B2和售后服务D2。该类特征属性在模型矩阵中属于基本要素类型,它们的好坏往往与顾客的购买意愿直接相关,能否进一步提升产品销售额的关键就在其中,需要企业重点关注该类指标的负面评价。而位于该象限的特征属性往往存在顾客总体满意度较高,而部分口碑较低的特点,造成如此不匹配的原因,一方面可能存在商家刷分的线性,另一方面就是购买猫粮的某位消费者对于产品该特征属性的评价及其不满,从而拉低总体情感度得分,尤其是B2和D2,甚至出现了负分,这更加说明该类特征属性的重要性,企业需要对其进行具有针对性的着重改进,争取消灭负面评价,使特征属性向第一象限靠拢。
Table 8. IPA-KANO classification results
表8. IPA-KANO分类结果
综合上述问题,如表8所示,在制定猫粮产品改进策略时,应倡导以提升产品整体质量为主导,以保证那些具有基础性特征属性的主题如口感和食用反馈能满足消费者的需求为主,提升功能性主题质量为辅的产品优化模式。第一,口感方面,维持住原有的猫粮适口性和软硬程度,再根据顾客反馈适当调整猫粮颗粒大小,减少猫粮刺激性香味;第二,食用反馈方面,率先保证产品新鲜程度,减少猫咪食用后出现不良肠胃反映及掉毛的情况,若部分顾客反映还是出现此类情况,需积极做出响应,跟进相关售后服务;第三,包装和服务方面,内包和外包同样重要,前者减少猫粮腐败情况,后者减少货物运损情况,同时,售前和售后也同样重要,是企业获得猫粮产品反馈体验的重要来源,需大幅提升售后服务质量满足顾客需求;第四,产品附加值方面,需制定相应的宣传策略,打造企业品牌,可适当多增加些猫粮产品的折扣活动。
4. 结论
本文以猫粮为例,通过机器学习算法对产品评论进行主题提取及情感分析挖掘需求偏好,再结合联合分析提出基于在线评论的IPA-KANO模型对偏好进行分类,将消费者对猫粮产品15种属性划分为期望、魅力、基本和无差异要素并得到相应产改进优先级,其中适口性、性价比等特征属性,企业应采取“继续保持”的策略;对于香味、品牌效应等特征属性,企业应采取“提升改进”策略。
传统需求分析中的需求分类依赖于KANO问卷,而本文设计了一种文本挖掘在线评论取代问卷调查的方法,与以往产品需求分析研究相比,解决了需求确定的主观性及不确定性问题;引入在线评论消费者对需求的关注度和情感度,提出一种适用在线评论的IPA-KANO模型,解决了传统需求分析中满意度和重要度定义重复模糊的不足;以往研究大多止于对产品属性的需求类型的判断 [17] ,对判断结果如何使用未做进一步分析,而本文在此基础上,结合IPA模型给出改进方法:电商企业可以依据评论的关注度能对产品需求实现细分,资源有限条件下,利用直观的消费者情感度能获取产品改进最优路径,对企业利益与消费者满意度协同最优有积极的现实意义。
同时,本文也存在以下不足:第一,由于网络评价的特殊性,爬取的产品评论中可能混有部分虚假评论未筛除。第二,在线评论除纯文本外还包含表情包等多形式评论,目前本文没有涉及。后续研究中需要继续改进机器识别算法,并尝试纳入其他形式的数据作为研究主体,为多形态数据下需求研究提供新方向。