1. 引言
目前,许多研究已经证明了自动驾驶汽车在应对道路安全、燃油消耗、可持续性等挑战方面的有效性。考虑到目前的科学成就,很难想象未来无人驾驶汽车不会被用于交通运输。然而,在自动驾驶汽车大规模上路之前,还有很多问题需要解决,例如对于车辆换道意图的快速准确识别。由美国高速公路安全管理局的统计数据可知,由于驾驶员操作不当引发的交通事故占总数的94%,其中由于换道操作不当引发的交通事故约占到总数的27% [1] ,这是因为当自身车辆或者周围车辆执行换道操作时,驾驶员无法全面获取人、车、路等多方面信息,也无法了解驾驶员在执行换道行为时的各种隐藏特征,对于当前车辆所处的环境无法做出准确快速的判断。所以,当驾驶员在驾驶时能够通过车联网设备准确获得自身车辆和周围车辆的实时动态信息,同时驾驶辅助系统可以根据这些信息精准地识别出车辆的换道意图并选择必要时机介入操纵车辆,那么就可以有效减少换道行为带来的风险,对道路交通安全提供了极大地保障。因此对于车辆换道行为的研究一直以来都是交通安全领域重点方向之一,与迄今为止进行的大多数变道研究一样,本文选择的是基于高速公路变道情景。
针对车辆换道意图的识别,国内外学者进行了大量的研究,其构建模型中所使用的识别方法根据基于算法的不同大致可以分为三类。第一类是生成式模型,这是一种概率模型。早在1997年Liu等 [2] 首次将驾驶员在换道操作时的一种内心状态定义为“换道意图”,并第一个采用隐马尔科夫模型(HMM)以车辆驾驶数据信息为根据来推断驾驶意图。在此基础上,Pentland等 [3] 提出了动态马尔科夫换道意图识别模型,宗长富等 [4] 提出了双层隐马尔科夫换道意图识别模型,以及Jin [5] 等提出了连续隐马尔科夫换道意图识别模型。此外,还有一些车辆换道意图识别模型是建立于HMM模型和其他算法相融合的基础之上。例如曲文奇等 [6] 提出了混合高斯–隐马尔科夫模型(GMM-HMM)。宋晓琳等 [7] 使用HMM和支持向量机(SVM)进行建模,使得能够更快速准确地识别车辆换道意图。Li [8] 等将贝叶斯滤波(BF)方法与隐马尔科夫模型(HMM)相融合来进行车辆换道意图识别,HMM的初步输出进一步使用BF方法进行过滤以做出最终决策。Li [9] 等提出了一种基于动态贝叶斯网络(DBN)的换道意图推理方法,并为了考虑驾驶员先前的行为将自回归(AR)与HMM相结合。由于HMM在变道过程中捕获环境信息的能力有限,这些基于HMM改进的车辆换道意图识别模型性能上有一定的提升,整体识别准确率仍显不足。第二类是判别式模型,常用的算法有k近邻法、感知机、SVM、逻辑回归、条件随机场、决策树、最大熵以及RF等,这类方法被广泛运用于车辆换道意图的识别与分类的研究工作,这类判别模型有着丰富的背景理论和成功的应用经验。Schlechtriemen J等 [10] 采用随机森林方法建立迭代时间短、准确率高且可回溯的车辆换道意图预测模型。Morris等 [11] [12] 对支持向量机算法进行贝叶斯扩展,即相关向量机(RVM)对驾驶员变道和车道保持意图进行分类。该分类器的准确率达到80%,且虚警率相对较低。Lethaus等 [13] 提出了一种基于人工神经网络的驾驶员意图识别方法,左变道检测精度优于右变道检测精度。Kumar等 [14] 将支持向量机和贝叶斯滤波融合使用构建了一个多类分类器,结果表明该算法可以实现平均1.3 s的提前预测。Jang等将驾驶员行驶途中瞳孔变化和运动数据作为输入来训练SVM分类器,其换道意图预测模型准确度在75%左右。Hanwool等将车辆相对于车道线的横向距离和速度变化作为部分特征训练得到了虚警率更低的SVM分类模型。黑凯先等 [15] 提出基于随机森林决策树算法的换道意图识别模型,其数据集是通过自建车辆仿真平台采集而得。第三类是深度学习模型,近年来,由于深度学习理论、并行计算硬件、大规模标注数据集等方面的发展,深度学习领域取得了巨大的成就。针对车辆换道意图的识别任务,其特征隐藏难以挖掘,而基于深度学习方法构建的模型具有很强的自学习能力,相较于上述前两类模型性能更为优良,同时其模型参数可调的优点使得能够更好地适用于不同的行驶场景数据集。由于循环神经网络RNN具有记录前一时刻信息的基础上处理当前时刻数据的特性,故常被用于处理数据集之间的时间依赖性。同时又因为车辆换道意图预测模型通常需要考虑之前的驾驶员行为和交通环境,而传统HMM方法捕捉长期依赖性的能力有限,所以不少学者开始应用循环神经网络以及其各种变种网络来更准确识别车辆换道意图。Patel S等 [16] 利用图结构模型表示目标车辆与周围车辆的交互关系,提出了一种基于结构化RNN (SRNN)的换道意图预测模型。Scheel O等 [17] 将多头注意力机制和双层LSTM融合使用,提升了模型的准确性和可解释性。Hochreiter等 [18] 提出了一种长短期记忆(LSTM)网络来增加长期依赖性并克服梯度下降。季学武等 [19] 使用长短期记忆网络识别车辆换道意图并对换道轨迹做出预测。Zyner等 [20] 提出了LSTM-RNN模型来推断车辆进入交互时的驾驶意图,证明了RNN优于二次判别分析模型。Jain等 [21] 证明了基于LSTM-RNN的车辆换道意图预测模型性能优于多个HMM模型,可以在变道发生前3.5秒检测到换道意图,同时准确率和召回率达到了90.5%和87.4%。XIE等 [22] 采用深度置信网络(DBN)构建车辆换道行为预测模型。
近几年基于深度学习方法构建的车辆换道意图识别模型性能表现较为优良,但是仍有提升空间,而且大多数研究仍然没有很好的处理车辆之间的交互关系。同时目前大多数模型的训练数据都采用的是离散的车辆轨迹数据信息,没有重点注意到车辆历史行驶信息中存在一定的时序和空间相关性,并且在进行海量数据计算时无法避免一定的重复和冗余,耗费时间较长。此外还有一部分模型选取驾驶员的生理特征为训练数据信息,这类信息的采集不仅需要专业车载设备,并涉嫌侵犯驾驶员隐私。因此针对车辆运动轨迹的时空特点,本文选择使用保护驾驶员隐私且获取简便的NGSIM车辆轨迹数据,提出了一种基于CNN-Transformer-GRU-Att组合模型来进行车辆换道意图识别。
2. 数据预处理
本文选用的数据集来源于NGSIM(Next Generation Simulation)数据集,它是由美国联邦公路局(Federal Highway Administration)搜集的美国公路行车数据,在US-101,I-80,Lankershim Boulevard和Peachtree Street四个特定路段场景上安装高空摄像头采集获取,记录了摩托车、小汽车以及大型车的行驶轨迹信息,包括车辆识别编号、车辆采集区域坐标系坐标、车辆标准地理坐标系坐标、车辆速度、车辆加速度、车道编号、车头间距和车头时距等。NGSIM数据集中车辆轨迹数据类型的详细描述如下表1所示。

Table 1. NGSIM dataset variable description
表1. NGSIM数据集变量描述
其中Vehicle_ID车辆识别编号是根据车辆进入该区域的时间升序进行编排的,重复利用。因此会出现相同车辆识别编号的车辆但是实际上并非同一车辆,也就是说在处理数据不可以车辆识别编号作为车辆的唯一区分凭证。而Frame_ID是表示该条数据在某一时刻的帧数,从开始时间升序,同一Vehicle_ID的帧号不会重复,所以后续可以根据在连续帧数(一定时间段)内的同一Vehicle_ID的数据获取某一车辆的一定时间长度的行驶轨迹序列信息。Local_X是采集区域坐标系下车辆前部中心的横向(X)坐标,以英尺为单位,相对于截面在行驶方向上的最左侧边缘,即以内侧车道往外侧车道变化的方向为正方向。Local_Y是采集区域坐标系下车辆前部中心的纵向(Y)坐标,以英尺为单位,相对于截面在行驶方向上的进入边缘,即以车辆行驶方向为正方向。同时将长度单位是“英尺(feet)”的多种类型数据转化为国际单位制基本长度单位米(m)。
由于本文研究工作集中在更具有普适性的高速公路而不是某一个特定的城市交通场景。所以本文选用的基础数据是NGSIM数据集中的US-101和I-80两个美国高速公路路段,其结构如下图1所示。

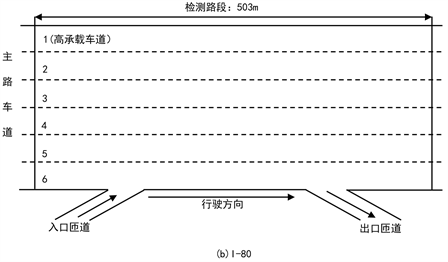
Figure 1. The structure of US-101 and I-80 freeway segments in the NGSIM data set
图1. NGSIM 数据集中US-101和I-80高速公路段结构
US-101路段中摄像头视野覆盖的路段长度为640 m,其中有5条高速公路车道。I-80路段中摄像头视野覆盖的路段长度为400 m,其中有六条高速公路车道(其中一条为高承载车道)和一条汇入的斜坡弯道。
同时NGSIM数据集中包含了摩托车、小汽车以及大型车三种类型车辆的行驶数据信息,各类型车辆数量占比如下表2所示。可以看到小汽车数量在所有车辆中的占比约为97%,远远多于其他两种类型的车辆,数据比例严重不平衡。同时,不同类型车辆的性能指标具有较大差异,加上不同类型车辆的驾驶员驾驶习惯风格也不同,从而导致在变道发生过程中不同类型车辆的行驶轨迹信息具有显著的差异性。为了专注于小汽车换道意图预测研究,所以本文剔除了其他两种类型车辆的数据信息,筛选保留了小汽车的行驶数据信息。
Table 2. The proportion of the number of vehicles of each type
表2. 各类型车辆数量占比
此外,刘晨强等 [23] 表示由于该数据集由高空摄像头采集而成,这种采集方式的局限性会使得原始数据受到周围环境的干扰并具有一定的测量误差,尤其是横向运动数据信息。而纵向运动和横向运动是地下车辆的两个基本运动方向,由于与周围车辆的复杂相互作用,横向意图通常比纵向意图更复杂。驾驶员的纵向行为包括制动、加速、启动和车道保持等,而横向行为则正是研究的重点—车道变换。为了保证采样轨迹数据的质量,尽可能地减小甚至排除对实验结果的负面影响,提高车辆换道意图预测的准确可靠性,本文选用了扩展卡尔曼滤波方法对嘈杂的实验数据进行平滑处理,选择2号车来体现降噪效果,如下图2所示。
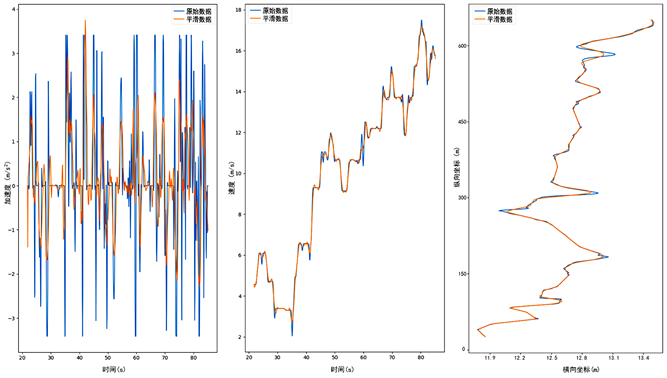
Figure 2. Comparison of the filters moothing effect of the second car
图2. 第2号车滤波平滑处理效果对比
3. 换道意图分类
在NGSIM数据集中US101和I-80两段高速公路的车辆轨迹数据不同于Lankershim Boulevard和Peachtree Street两个城市路段,缺乏车辆换道行为的标签,无法直接得知车辆驾驶行为是向左换道,还是向右换道,或是保持车道不变直线行驶。所以本文需要首先根据车辆的行驶轨迹数据对车辆的驾驶行为进行分类,分为向左变道、向右变道、车道保持三类,并将分类结果给每条车辆行驶轨迹数据附上驾驶意图标签。
3.1. 车辆驾驶意图分类
驾驶员意图可以根据不同的标准划分为不同的类别。例如,它可以根据动机、时间尺度和车辆控制方向进行分类。其中,两种最直观的分类方法是基于意图的时间尺度和驾驶方向。变道过程中存在四个关键时刻。T1表示驾驶员产生变道意图的时刻。T2是驾驶员完成交通环境检查并开始变道的时刻。T3表示车辆开始穿过车道的时刻,即车辆与车道中心线发生交叉的时刻。最后,驾驶员在T4完成变道行为。因为没有精确的驾驶员心理模型可以用来描述驾驶员何时产生意图,所以受到主观影响的T1无法精确确定。因此,大多数研究使用T2和T3作为评估识别范围的时间标准。又因为识别越早,任务就越困难,所以需要精确确定T2和T3。而像Lee [24] 一样在车道编号发生改变之前的3秒标准来标记为车道变化的起始时刻显然不够精确。因此本文选择智能自动标记,这样可以捕捉到人类无法察觉的细微线索,从而使得模型获得更好的表现。
本文智能自动标记车辆换道意图标签的依据是换道临界点前后连续时间长度内车辆行驶的航向角绝对值是否小于某个阈值。具体提取规则如下,首先是确定换道的临界判定点,逐帧读取同一小车的车辆行驶数据,由于NGSIM数据信息包含车道编号,所以可直接获取该小车在某时刻所处车道的信息。而当同一辆车在某个时刻的车道编号与前一时刻的车道编号不一致,这表示该车辆在此时刻与车道中心线发生交叉,此时刻即为T3,此时刻车辆所处位置称为换道中点。再由车辆位置坐标信息计算得到车辆的航向角,然后从换道中点沿时间轴逆向逐帧读取采样点的航向角参数值,航向角的参数值计算如公式(1)所示:
(1)
由于车辆行驶轨迹数据本身具有一定误差和噪声,所以规定当第一次读取到连续三个采样点的航向角的参数值都不大于航向角阈值时,则第一个采样点的时刻即为T2,此时刻车辆所处位置称为换道起点,这样可以有效保证对于换道起点判断的准确可靠性。同理,从换道中点沿时间轴顺向逐帧读取采样点的航向角参数值,若当第一次读取到连续三个采样点的航向角的参数值都不大于航向角阈值时,则第一个采样点的时刻即为T4,此时刻车辆所处位置称为换道终点。参考 [25] 本文将换道起点和换道终点航向角阈值均选取为θth = 0.02rad。本文对车辆直线行驶行为规定为车辆的航向角绝对值小于航向角阈值保持10 s以上。
又因为轨迹数量上直线行驶远远多于换道行驶,为了保持数据集的平衡,本文对直线行驶和向右换道两类行驶轨迹进行欠采样,使其被选取的样本数量等于向左换道行驶轨迹的数量。最终从三类不同驾驶行为的行驶轨迹中各选取1596条车辆行驶轨迹片段(共4788条)组成整个数据样本。
3.2. 样本序列提取
为了充分利用上述所提取的车辆行驶轨迹信息,并且最大限度获取车辆换道意图阶段的数据,本文直线行驶车辆的数据序列中驾驶行为标签全部标记为2,对于换道车辆,将换道起点前1 s认定为换道意图阶段。如下图3所示,以车辆左换道为例,T2点为换道起点,与T2点相隔1 s的T1点为换道意图产生点,T3点为换道临界点,T4点为换道终点,此时T1点到T4点的数据信息为该车辆的一个完整行驶轨迹序列,并将这整个序列中的驾驶行为标签标记为0 (右换道车辆驾驶行为标签标记为1)。最后对所有的车辆行驶轨迹片段使用滑动窗口法从整个车辆行驶轨迹序列提取一定时间长度的样本序列,本文选取采样窗口的长度为1 s,采样率为10 Hz。由于不同的驾驶行为的持续时间不同,直线行驶持续时间远大于换道行为,为了进一步保证数据集的平衡,避免预测模型以高假阳性率为代价追求高真阳性率,本文选择对每条轨迹切分成的序列只随机选取10条,即共提取了47,880条轨迹序列。本文再按照3:1的比例分为训练集和测试集。最后模型中所用数据含有位置、速度等多类型数据,不同类型间数值尺度和单位差异都较大,为了减少数据中不同类型数据量纲的干扰,将序列中所有的数据信息进行最小–最大归一化处理以便于神经网络的训练,加快收敛速度。

Figure 3. Indication of vehicle lane change intention
图3. 车辆换道意图标注示意
4. 换道意图识别模型
4.1. 卷积神经网络(CNN)
为了有效提取输入数据中的时序特征,本文卷积神经网络(CNN)部分选择常用于序列模型领域的一维卷积Conv1D神经网络,其卷积计算可以实现对原始数据深层次和抽象化的处理,能够有效自动提取数据内部特征。本文CNN部分的输入数据是上文预处理完后的车辆轨迹数据序列,通过公式(2)进行计算:
(2)
上式计算过程可以描述为t时刻时第i个卷积核在与输入xt叉乘后加上偏置量bi得到输出特征向量y(t,i)。
4.2. Transformer模型
当前基于注意力机制的编码器–解码器架构的Transformer模型在处理长序列、并行计算、捕捉全局信息能力时表现优异,而这良好的性能来自于它的自注意力机制和多头注意力机制。它具有显著的提取长序列元素之间相关性的能力,同时还可以有效弥补LSTM和RNN存在的梯度消失和梯度爆炸等缺陷,这就表示它可以充分考虑目标车辆与周围车辆的交互作用,还能够关注到较长时间内与车辆相关的信息,有效捕捉到更长的序列依赖性。又由于每辆车的驾驶行为会受到驾驶员驾驶风格习惯、道路环境状况、周围车辆行驶状态等很多因素影响,这些隐藏因素不仅难以描述,无法妥善地量化表示作用关系,而且还在时刻动态变化。所以为了充分利用输入的序列数据,本文选择使用Transformer模型的编码层来进一步有效提取车辆变道意图隐藏特征。该层结构如下图4所示:

Figure 4. Schematic diagram of coding layer of Transformer model
图4. Transformer模型编码层结构示意
Transformer模型中由多个自注意力而得的多头注意力机制是其显著的提取长序列元素之间语义相关性的能力主要来源。自注意力向量通过公式(3)计算所得,
(3)
其中,Q (Queries向量)、K (Keys向量)、V (Values向量)是通过特征向量隐射到不同的线性空间所得,dK为向量K的维度。多头注意力机制中最终的注意力向量是通过公式(4) (5)计算所得,
(4)
(5)
其计算过程可以描述为,将输入向量通过n个并行的注意力机制计算所得结果拼接,再将其映射到输入向量的原始线性空间即可得到。其中Concat为矩阵拼接,headk为第k次注意力机制计算,
、
、
为第k个head中的映射矩阵。
4.3. 门控循环单元
如今有不少学者建立基于循环神经网络RNN或长短期记忆网络LSTM来实现对车辆换道意图和轨迹的预测,这些模型虽然在处理时间序列数据时性能良好,但是在面对车辆轨迹数据时仍然有一些缺陷,例如受限于滑动窗口的大小、梯度消失或梯度爆炸、训练效率低下以及未能充分考虑车辆之间交互作用的影响。所以本文使用了LSTM的改进版本——门控循环单元(Gated Recurrent Unit),不仅同样可以学习长期依赖关系,而且由于它简化了LSTM原本复杂的内部结构,用更新门替换了输入门和遗忘门,在不损失预测精度的前提下减少了训练参数并提高了训练效率,可以有效处理车辆行驶轨迹序列数据。GRU的基本结构如下图5所示,
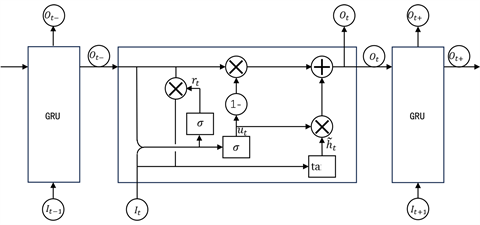
Figure 5. Schematic diagram of Gated Recurrent Unit (GRU) structure
图5. 门控循环单元(GRU)结构
图中×表示矩阵数乘,
为重置门和更新门神经元的Sigmoid激活函数,tanh为记忆门神经元的激活函数,It为当前时刻模型的输入值,Ot为当前时刻模型的输出值,Wu、Wr、W为权重系数矩阵,ht−1是前一节点的隐藏层输出。可以看到GRU有两个重要组成部分——重置门rt和更新门ut,前者决定了有多少前一时刻的信息被写入到当前状态信息,后者则控制前一时刻和当前时刻的状态信息的保留程度。模型通过公式(6)~(9)计算当前隐藏层的输出ht:
(6)
(7)
(8)
(9)
4.4. CNN-Transformer-GRU-Att模型
为了有效提取车辆换道意图重要隐藏特征和捕捉车辆行驶轨迹序列中局部和长期依赖性,本文提出了一种融合卷积神经网络(CNN)、Transformer模型、门控单元神经网络(GRU)和注意力机制的组合模型,具体结构如图6所示。

Figure 6. Structure of vehicle lane changing intention recognition model based on CNN-Transformer-GRU-Att
图6. 基于CNN-Transformer-GRU-Att的车辆换道意图识别模型结构
本文选择先使用CNN提取车辆行驶轨迹内部特征,再将如上改进的Transformer模型进一步重构时间序列数据,这样不仅能够考虑到换道过程的时序和连续特征,而且还可以高效率地提取更深更抽象的换道行为意图隐藏特征,较好地处理一定长度的时间序列信息,从而有效地捕捉其中的长期依赖性。Transformer目前可以被称为提取长序列中元素之间语义相关性的最成功的解决方案。然而,在面对车辆行驶轨迹这一类过长的时间序列建模时,需要从连续点的有序集合中提取出时间关系时表现欠佳。而提取时间关系的能力在很大程度上取决于与输入标记相关联的位置编码,即对于一组连续点而言,与配对关系相比这些元素的顺序更能体现出它们之间的时间关系。虽然在Transformer中采用位置编码和标记嵌入子序列有助于保留一些排序信息,但其自注意力机制在一定程度上具有排列不变性和“反序性”,会不可避免地引起序列中时间信息的丢失。而本文核心问题是通过车辆轨迹时间序列数据中的车辆位置、速度、加速度等多变量的输入信息来实现对车辆驾驶行为这单个值进行滚动预测,在该问题中不需要Decoder结构进行并行计算。所以,为了更好的满足车辆驾驶意图预测任务,本文将原Transformer模型中Decoder结构剔除,这样简化后的Transformer部分可以避免由于车辆行驶轨迹序列过长而引起模型迭代计算需要过多的成本和内存。再将Transformer模型输入部分与GRU层进行耦合,GRU不仅能够避免RNN网络梯度消失下降消失和爆炸的缺点,同时它与LSTM相比需要更少的参数和占用内存,从而进一步提高了模型的运算效率,缩短了迭代时间。应用Transformer模型输入部分对换道行为主要影响因子寻找,再将其特征进行表达与提取并作为GRU网络的输入。由于车辆动态信息是对驾驶行为的响应,在意图推理任务中,相对于驾驶员行为数据和交通环境信息,车辆动态信息给出的信息是滞后的。一般情况下,车辆动态信息不能为意图识别提供高级信息。然而,它们仍然对车辆横向机动发生后的早期阶段中纵向驾驶行为意图识别有用。选择使用GRU网络可以充分利用一定长度的车辆行驶历史数据序列,而不是仅仅根据单一某个历史时刻的数据,从而能够对车辆换道意图有着持续准确的识别预测。Transformer部分所提取出的数据特征在GRU层得到充分利用,同时这些特征会通过GRU层的门结构来被决定是否记住或忘记,这样就能够从多个尺度对特征序列之间的长期依赖关系来进行建模,弥补了Transformer难以捕捉局部依赖性的缺陷。然后由于预测车辆的驾驶行为会被受到周围车辆影响,但是周围车辆的不同行驶状态和其驾驶员的不同驾驶习惯对目标车辆的换道意图产生和执行会造成不一样的影响。所以为了解释这种实际驾驶情景,在GRU层后再加入了注意力机制,不同的车辆换道意图隐藏特征被赋予不同的权重系数,即可体现其对于预测车辆的驾驶行为决策的不同影响程度。最后经过这些部分的计算后所得输出再通过Softmax函数映射得到一个值域范围为(0, 1)的最终输出值,这个输出值就是预测车辆发生换道行为的概率,输出值最大的一种驾驶行为即为本文模型对目标车辆换道意图的识别结果。
本文在采用扩展卡尔曼滤波方法对原始数据进行滤波处理后,提取了目标车辆及周围车辆的位置、速度和车道环境位置信息等特征,如下图7所示:

Figure 7. Schematic diagram of target vehicle and surrounding vehicle scene
图7. 目标车辆及周围车辆场景示意
目标车辆即为被预测车辆,其在t时刻的横向坐标、纵向坐标、速度和加速度分别记作
,
,
和
,本文通过计算目标车辆在同一帧内与其他车辆横纵向距离最小来确定其在同一行驶环境下的周围车辆,周围车辆为目标车辆的左前方、正前方、右前方、左后方、正后方和右后方六个方位的车辆,记作
,其在t时刻的横向坐标、纵向坐标、速度和加速度也分别记作
、
、
和
。
本文中所构建的车辆换道意图预测模型的输入向量I(t)见公式(10) (11)。
(10)
(11)
其中,
,N表示输入的车辆行驶轨迹序列的长度,
表示i号车在t时刻的状态信息,
表示i号车在t时刻到路段左侧的距离,
表示i号车在t时刻与目标车辆的相对距离。
车辆换道意图识别模型的输入是一段长度的车辆行驶轨迹数据序列,而输出则是该车辆发生了何种驾驶行为,这在本质上是一个多分类问题。首先车辆是否执行换道行为是一个二分类问题。然后车辆所执行的换道行为是发生了左换道行为还是右换道行为,又成为了另一个二分类问题。本文采用One-Hot编码用一个三维的二进制向量来表示车辆驾驶行为,即
表示向左换道,
表示向右换道,
表示直线行驶。模型输出向量为
,其中,pi表示其对应的车辆驾驶行为发生的概率。最后根据最大的概率值确定模型最终识别所得的车辆驾驶意图结果。
5. 实验分析
5.1. 评价指标
本文选取了以下五个评价指标从识别精度和识别水平两个方面来评价本文所提出的基于CNN-Transformer-GRU-Att的车辆换道意图识别模型,这样可以通过分类效果和运算效率来更加全面的衡量模型性能。
精确率(Precision):指某种驾驶意图被识别正确的样本数量占识别结果为该种驾驶意图的样本数量的比例,具体计算见公式(12)。
(12)
召回率(Recall):指某种驾驶意图识别正确的样本数量占实际的该种驾驶意图样本数量的比例,具体计算见公式(13)。
(13)
F1-分数(F1-score):指精确率与召回率的调和平均值,具体计算见公式(14)。
(14)
准确率(Accuracy):指三类驾驶意图被识别正确的总样本数量占总样本数量的比例,具体计算见公式(15)。
(15)
上式中TP指模型识别结果与实际意图均为正的样本数量,FP指模型识别结果为正但实际意图为负的样本数量,TN指模型识别结果与实际意图均为负的样本数量,FN指模型识别结果为负但实际意图为正的样本数量。
推理耗时(Time to Iterative Calculations, TIC):指模型训练迭代推理计算100次所耗费的总时间。
5.2. CNN-Transformer-GRU-Att模型换道意图识别结果
通过训练集完成模型的训练后,再通过测试集对模型性能进行评估。将测试集的实际意图与本文所提模型的识别结果汇集制作成如图8所示的混淆矩阵热力图。
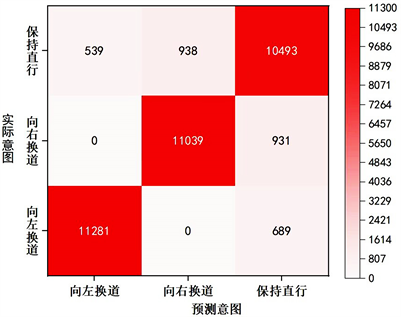
Figure 8. Confusion matrix heat map of model recognition results
图8. 模型识别结果混淆矩阵热力图
基于上述提及的评价指标,本文所提出的换道意图识别模型性能评估结果如表3所示。
Table 3. Performance results of CNN-Transformer-GRU-Att Model
表3. CNN-Transformer-GRU-Att模型性能结果
由表4可知,本文所提出的基于CNN-Transformer-GRU-Att的车辆换道意图识别模型综合准确率为91.38%,推理耗时为10.08 s。其中对于两种换道意图的识别在精确度、召回率、F1分数分别均高于94%、92%,表明该模型能够高效率地准确感知和判断车辆的驾驶意图,具有优良的识别车辆换道意图性能。该模型对于向左换道这一驾驶意图的识别效果最好,精确度、召回率和F1分数三个评价指标均优于其他驾驶意图的识别效果,而对于保持直行的识别效果相对较差,精确度、召回率和F1分数三个评价指标均为最低值。同时由图7可知,该模型没有将车辆换道意图识别成相反的结果,即将向左(右)换道的实际意图识别为向右(左)换道。这些综合表明了该模型能够很好的挖掘、学习、记忆并推导车辆执行换道行为的隐藏特征,且不同的换道意图的特征之间具有较为显著的差异性。而车辆保持直行时容易由于驾驶员的无意识行为给车辆带来横纵坐标、速度和加速度上的扰动,这些细微的变化也被模型错误的提取并当作是车辆换道意图的复杂特征,所以该模型会将一些车辆保持直行的实际意图错误分类为换道。
5.3. 各模型性能对比实验
为了进一步验证本文所提出新模型的优良性和可靠性,本文选择CNN、LSTM、GRU、CNN-GRU等模型在基于同一数据集上与本文所提出的CNN-Transformer-GRU-Att模型对比实验,最终各模型性能对比结果如表4所示。
Table 4. Performance comparison results of various models
表4. 各模型性能对比结果
由表4可知,本文所提出的CNN-Transformer-GRU-Att模型在精确度、召回率、F1分数、准确率等四个评价指标上全面明显高于其他模型,对于三种驾驶意图的识别效果也是均明显优于其他模型。与CNN、LSTM、GRU三个单一传统模型相比,本文所提模型在准确率上分别提高了9.34%、8%、6.92%,关于三种换道意图的识别结果在精确度上平均提高了9.22%、7.87%、6.81%,在召回率上平均提高了9.33%、7.99%、6.91%,在F1分数上平均提高了9.3%、7.95%、6.88%.可以看到本文所提模型对车辆换道意图的识别能力明显强于单一传统模型,各评价指标提升明显。与CNN-GRU组合模型相比,本文所提模型在精确度、召回率、F1分数、准确率上分别提高了4.29%、4.26%、4.28%、4.27%,且推理耗时缩短了7.18%,表明了本文所提模型通过组合CNN层、Transformer模块、GRU层和注意力机制能够有效兼顾车辆行驶轨迹序列中局部和长期依赖关系,从车辆行驶动态信息和道路环境静态信息中充分提取车辆换道意图的深层次抽象特征,同时再进一步提升了识别精确度的前提下仍有着相对较高的迭代计算效率。
5.4. 消融实验
此外,通过对Transformer模块、GRU层和注意力机制进行消融实验,实验结果如表5所示,Transformer模块、GRU层和注意力机制分别帮助模型在车辆换道意图的识别整体准确率上提高了3.19%,5.07%和1.08%,表明本文选择组合的这三部分都能一定程度上有效提高车辆换道意图识别模型性能。
Table 5. Results of ablation experiment
表5. 消融实验结果
5.5. 输入序列不同时间长度N下模型性能结果对比
车辆换道意图识别分为三阶段,其重点在于驾驶意图的产生阶段。在使用滑动时窗法切分车辆行驶轨迹序列时,窗口大小影响模型输入时间序列的长度。理论上来讲,模型的输入数据维度越高,则表明模型可收集利用的信息越多,能够采集和提取更多特征,能够更加准确识别车辆换道意图,但是这也会导致模型计算成本呈指数增长,降低了模型计算效率。所以下面对比了不同时间长度N的车辆历史行驶轨迹序列输入对车辆换道意图识别模型性能的影响,以准确率和推理耗时作为评价指标,结果如表6所示。
Table 6. Comparison of model performance results under different time lengths N of input sequences
表6. 输入序列不同时间长度N下模型性能结果对比
由表6可知,随着模型输入车辆历史行驶轨迹序列的长度的增大,模型所获得的车辆行驶和道路环境信息越多,提取到换道意图隐藏特征越多,对于车辆换道意图的识别精度越高,模型迭代计算的耗费成本越高。但是当输入的序列长度超过一定阈值时,此时模型所获得信息中包含着一定量的与驾驶意图相关性较低的无用信息,例如驾驶员无意识的行为动作而引起的车辆随机运动,并且模型同时从中错误的学习记忆到一些具有换道意图的特征,从而影响模型对车辆换道意图的识别准确度有所下降。当模型输入车辆历史行驶轨迹序列的长度为1 s时,模型的整体识别准确率最高,达到。在对车辆驾驶意图分类时可得驾驶员从产生换道意图到车辆抵达换道中点这一过程平均持续时间在2.5 s左右,而本文所提模型在车辆换道前2 s内整体识别准确率在89%以上,表明本文所提模型能够在车辆抵达换道中点之前做出准确的感知和预测。
6. 结论
为了保证车辆换道意图的识别准确性,本文首先采用扩展卡尔曼滤波方法对车辆轨迹数据进行平滑处理,再基于航向角的变化对车辆的驾驶行为进行分类并标注,再提取出目标车辆和周围车辆的横纵坐标、速度及加速度等行驶信息,将目标车辆和周围车辆相对位置、速度、加速度等动态行驶信息和车辆与路段左侧距离静态环境信息共同作为模型的输入特征,又由于车辆换道意图产生和执行的复杂性以及行驶过程中的时空特性,结合车辆实际驾驶情况,考虑到车辆换道意图的影响因子众多且程度各异,提出了一种基于CNN-Transformer-GRU-Att组合模型来进行车辆换道意图识别,能够较好解决CNN与LSTM融合时存在重要意图隐藏特征丢失、难以兼顾车辆行驶轨迹序列中局部和长期依赖性、模型计算效率低下迭代时间长等缺陷。
本文通过选取NGSIM数据集中US101、I-80两段高速公路的车辆行驶数据信息对模型进行训练和测试,并与CNN、LSTM、GRU、CNN-GRU等模型进行对比,实验结果表明,本文所提出的融合注意力机制的基于CNN-Transformer-GRU组合模型整体识别准确率为91.38%,推理耗时为10.08 s,在精确度、召回率、F1分数、准确率等评价指标上有明显优于其他传统模型,且推理耗时小于除CNN单一模型外其他模型。综上说明本文所提出的模型有着优良的识别性能,能够快速准确的感知和判断车辆的换道意图,可以有效规避换道过程中的碰撞风险,进一步保证了车辆行驶的安全性,具有一定的实际应用价值。