摘要: 本文研究了具有重叠集合约束的实体解析集合相似性连接问题。给定两个集合内元素为集合的集合以及一个常数c,找到数据集当中至少共享了c个共同元素的所有集合对。这一问题是许多领域诸如信息检索、数据挖掘和实体解析当中的基本操作。现有的方法都受到了O(n
2)的限制,其中n是数据集总的大小。本文提出了一种算法复杂度为
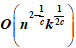
的集合大小感知算法。集合大小感知算法根据集合大小将所有集合分为大集合与小集合并分别进行处理。本文通过现有的方法来处理大集合,对于小集合本文提出了集中启发式算法来提高算法性能。由于大集合与小集合的大小边界对于效率至关重要,本文还提出了一种有效的大小边界的选择方法来选择合适的大小边界。本文通过在真实数据集上的实验结果证明了该方法的有效性。
Abstract:
In this paper, the entity resolution set similarity connection problem with overlapping set constraints is studied. Given two sets whose elements are sets of sets and a constant c, find all sets that share at least c common elements in the data set. This problem is a fundamental operation in many fields such as information retrieval, data mining, and entity resolution. Existing methods are limited by O(n
2), where n is the total size of the dataset. This paper presents a set size awareness algorithm with
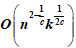
complexity. The set size sensing algorithm divides all sets into large sets and small sets according to the set size and processes them separately. In this paper, the existing methods are used to deal with large sets. For small sets, a centralized heuristic algorithm is pro-posed to improve the algorithm performance. Since the size boundary of large sets and small sets is very important for efficiency, this paper also proposes an effective size boundary selection method to select the appropriate size boundary. Experimental results on real data sets demonstrate the ef-fectiveness of the proposed method.