1. 引言
随着时代变迁与人类生活领域的交互,为推动我国现代化体制建设进程,促进世界经济全球化,从改革开放时期以来,我国始终坚持对外开放力度,逐步扩大对外开放范围,尤其是外贸方面,使我国在对外贸易发展中取得长足的进步,让我国同世界各国人民共同走向人类命运共同体。在国家间往来日益频繁的今天,各国之间有经济、文化、繁育以及习俗之间的交融,种族特征在随着时间的推移与人类间互相演变出现新的特征,结合当前大数据知识应用体系留存不同国家人脸特征数据,以逐步丰富人脸识别分析基础资源数据库。人脸识别就显得尤为重要,它能有效对各个国家人员进行识别,以便我国边检口岸等一系列安全系统能更有效、快速地识别各个国家人员,构建更加有序的公共环境。也可以逐步丰富人脸识别分析基础资源数据库,这对未来相关领域的研究将会是一份宝贵的财富。
近年来国内外也有不少研究者们对人脸种族识别进行了一定的研究。Sheerko Hma Salah [1] 等人使用颜色和纹理的多层融合方案进行人脸种族特征的提取,其样本数据是由多个数据库集合构成,然后使用KNN分类器区分高加索人、东亚人、非洲人,其平均准确率达96.5%。A. Rehman,G. Khan [2] 等人使用Haralick + GLCM特征融合提取特征,并使用预测随机数作为分类区分亚洲人、欧洲人和非洲人,其准确率达到85.39%。黄惠 [3] 将PCA和2DPCA进行特征提取,用多种不同的SVM作为分类器应用于自建中国少数民族(维吾尔族、柯尔克孜族、哈萨克族、回族、蒙古族)数据库进行民族识别,实验表明,使用RBF的SVM效果可达85%。王雅丽 [4] 使用CNN提取深度虹膜纹理特征作为底层向量,并结合Fisher向量相融合,使用SVM分类器区分亚洲人和非亚洲人,最高准确率可达99.93%。邱盛 [5] 在深度学习的研究中,利用了几种不同网络框架对自建的中国部分少数民族(汉族、蒙古族、藏族、维吾尔族)数据集进行民族识别分类,其中包括卷积神经网络和集成神经网络,并利用卷积神经网络搭建了一个基于这五个民族的人脸识别系统。
从当前国内外研究现状来看,当前研究中基本都在区分人种,而对同一区域不同国家的人脸面部研究几乎没有。因此本文提出针对同一区域(亚洲)上的五个国家(中国、日本、韩国、泰国、印度)进行人脸识别分类的研究。本文通过基于MobileNet网络上对本文自建的五国人脸数据集进行识别分类,通过对原始网络、插入八度卷积以及加入中心损失函数后的实验数据对比,验证本文提出方法的有效性。
2. 自建五国人脸数据集
2.1. 人脸数据集的采集
由于当前没有公开的这五国的人脸数据集,且考虑到实地采集的困难性和限制性,本文通过网络爬虫获取这五国(中国、日本、韩国、泰国、印度)的人脸数据样本。由于网络爬虫图像样本数据存在大量由光照、姿势、遮挡各种因素引起的大量差异,本文通过使用,Multi-task convolutional neural network (MTCNN,多任务卷积神经网络)对本文通过网络爬虫采集的人脸数据样本进行“清洗”,即对人脸定位和对齐,本文将原始数据集裁剪成了128 × 128尺寸大小。本文经过“清洗”后所建立的原始数据集样本共10,266张(中国2881张、日本1747张、韩国2381张、泰国1971张、印度1286张),由于网络爬虫的限制导致得到的初始样本数据量不一致,得到的部分样本数据如图1所示,其样本顺序由左到右五列依次为中国、日本、韩国、泰国、印度。

Figure 1. Face samples of five countries
图1. 部分五国人脸样本
2.2. 人脸数据集的扩充
由于使用深度学习,需要大量人脸图像进行学习。故本文采取数据增强方法对样本数量进行扩充,通过对原始照片旋转一定的小角度(角度旋转范围在15度以内)、改变饱和度、对比度、锐度以及亮度来进行样本数据的扩充。
3. 基于Mobilenet网络模型核心
3.1. MobileNet网络
MobileNetV1网络结构模型是2017年谷歌团队提出的 [6],该网络主要针对便捷式或嵌入式设备使用,属于轻量级卷积神经网络,在2018~2019年谷歌团队在该网络基础上又先后提出了MobileNetV2网络 [7]、MobileNetV3网络 [8]。本文的所有实验都是基于MobileNetV1和MobileNetV2两个模型上进行的。该网络核心思想是深度可分离卷积,其原理是把普通卷积拆分成一个深度卷积和一个点卷积的组合以减少运算量。其原理如图2所示。
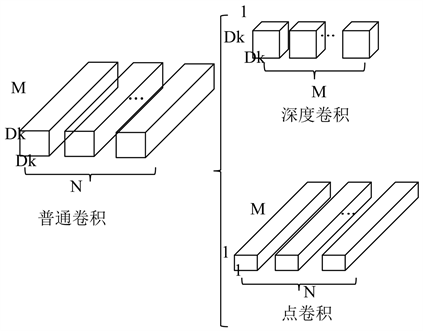
Figure 2. Deep separable convolution principle
图2. 深度可分离卷积原理
MobileNet网络的第二个核心是提出了两个超参数:宽度因子α、分辨率因子β,这两个超参数的目的也是减少运算量。理论上来说,宽度因子α的取值越大,其训练精度越高,相应地训练时间也和参数量也增加。同理,对于分辨率因子β,其取值越大,训练精度越高,相应地训练时间也和参数量也增加。宽度因子α取值范围在[0, 1],通常定义为四个值:0.25、0.5、0.75、1。分辨率因子β通常是128 × 128、160 × 160、196 × 196、224 × 224。
MobileNetV1网络共28层,其网络结构中,除了第一层和最后一层使用普通卷积,其余层均采用深度可分离卷积代替普通卷积。每一层卷积后面均需使用BN (Batch Normalization)和Relu6激活函数,目的是为了能有效调整每一层的特征图分布,加速网络收敛,增强了网络的泛化能力。
MobileNetV2网络共有54层,在MobileNetV2网络模型中,它是将MobileNetV1网络做了两处改进:1) 仿照ResNet网络的核心思想,加入了“倒残差模块”,即对原始特征图做“扩张–卷积–压缩”的操作;2) 去除最后层的Relu6激活函数,直接替换为线性输出。
3.2. 八度卷积
八度卷积 [9] 是2019年提出的一种新卷积,八度卷积的目的是为了在提高精度的同时,减少冗余。它的核心思想就是通过空间尺度变化将图像拆分为高频、低频两块,此操作可以大大降低参数量。完成此步骤是通过使用网络定义的超参数α将图像分解成高频低频两部分,通过高斯滤波器使得低频的空间是高频空间的一半,将原图像可以拆分成图3所示,通过该方法可以有效减少空间冗余。
八度卷积的另一个优点是可以很好的嵌入到任一神经网络中,即可以在不改变原网络结构及参数的前提下,通过对超参数α的设定即可用八度卷积代替普通卷积,较好的解决低频信息的冗余问题。八度卷积的使用中,除第一层和最后一层外对超参数设定为:
,第一层的输入和最后一层的输出均为0,即可完成对八度卷积的即插即用。
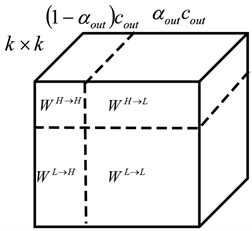
Figure 3. Principle of octave convolution
图3. 八度卷积原理图
4. 损失函数
由于亚洲这五国人脸面部极为相似,尤其是中日韩三国,为了能更好地将他们进行分类研究,本文提出将中心损失函数 [10] 与交叉熵损失函数相结合的方法来改进实验精度。中心损失函数的作用是在分类识别中,减小类内的差异,也就是说使同一类的样本相似性更大,让同一类能尽可能向样本中心靠拢,而常用的交叉熵损失函数是为了增大各类别间的距离,减少类间的交叉问题。两者结合可以更好的区分开这五国人员。在两者结合后,整个网络的损失函数如公式(1)所示。
(1)
其中,
分别代表交叉熵损失函数和中心损失函数,λ表示两个损失函数之间的比重。
表示在全连接层前的特征,
代表第
个类的特征中心,m代表的是每个batch的样本数量,n是类别数量,本文中的n是5。
5. 基于MobileNet网络实验分析
5.1. 评价标准
本文实验中通过采用网络爬虫自建的五国人脸数据集,分别是中国、日本、韩国、泰国、印度五国。实验共用68,495张样本数据,各国分别13,699张,训练测试按照7:3比例随机抽取,即训练共47,945张,测试20,550张。在下面三个网络模型中,模型迭代次数均设置为1000次。本文中所有实验均在64位Windows 7的环境,内存为16 GB,CUDA 10.1,Python 3.6配置mxnet和python环境搭载GPU的主机上进行编程调试。
在MobileNetV1网络结构中,为了验证宽度因子α对实验结果的影响,分别选取了α = 0.75 (MobileNetV1_075)、α = 1 (MobileNetV1_100)两个模型进行实验,然后又对比了相同参数下,MobileNetV1_100和MobileNetV2_100两个模型,验证MobileNetV2网络相较于MobileNetV1网络在本实验中效果是否得到提升。在本文整个实验评价指标均采用Accuracy和Error top 1,其中Accuracy是针对训练集进行评价,Error top 1是针对测试集进行评价的。其公式如下:
(2)
(3)
5.2. 实验结果分析
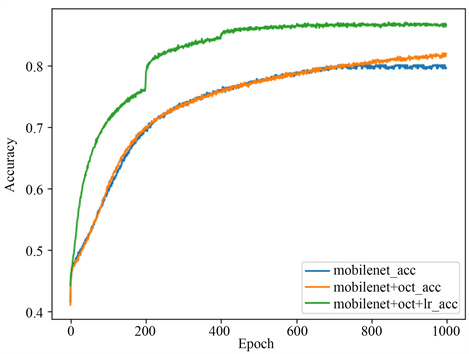
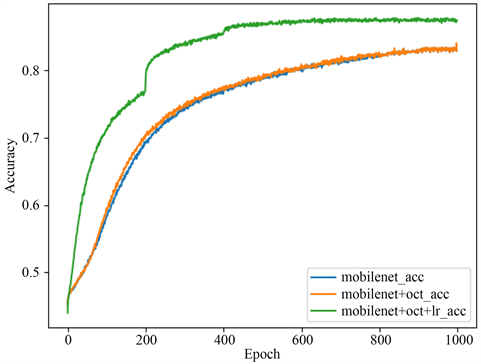
本文基于MobileNetV1和MobileNetV2两个网络上进行学习,首先是将五国人脸数据集应用在原网络上进行分类识别,其次是在两个网络模型上插入八度卷积后进行分类学习,最后是在此基础上改进损失函数的实验结果。图4是在MobileNetV1_075模型上的实验结果,图5是在MobileNetV1_100模型上的实验结果,图6是在MobileNetV2_100模型上的实验结果。
 (a)
(a) (b)
(b)
Figure 4. (a) Based on MobilenetV1_075 training result graph; (b) Based on MobilenetV1_075 test result graph
图4. (a) 基于MobilenetV1_075训练结果图;(b) 基于MobilenetV1_075测试结果图
由MobilenetV1_075两个实验结果图可以看出,在加入八度卷积后,其训练精度得到了一定的提升,而后在加入八度卷积基础上改进其损失函数,我们可以看到不管是在训练集上的Accuracy还是测试集上的Error top 1的得到了显著改善。
 (a)
(a) (b)
(b)
Figure 5. (a) Based on MobilenetV1_100 training result graph; (b) Based on MobilenetV1_100 test result graph
图5. (a) 基于MobilenetV1_100训练结果图;(b) 基于MobilenetV1_100测试结果图
由MobilenetV1_100两个实验结果图可以看出,在加入八度卷积后,其训练精度曲线与原模型基本保持吻合,只得到了较不明显的提升,而后在加入八度卷积基础上改进其损失函数,我们可以看到不管是在训练集上的Accuracy还是测试集上的Error top 1的得到了显著改善。
 (a)
(a) (b)
(b)
Figure 6. (a) Based on MobilenetV2_100 training result graph; (b) Based on MobilenetV2_100 test result graph
图6. (a) 基于MobilenetV2_100训练结果图;(b) 基于MobilenetV2_100测试结果图
由MobilenetV2_100两个实验结果图可以看出,在加入八度卷积后,其训练精度得到了较为显著的提升,而后在加入八度卷积基础上改进其损失函数,我们可以看到不管是在训练集上的Accuracy还是测试集上的Error top 1的得到了显著改善。具体实验中我们还要考虑训练时间等其他因素来判别三个网络模型的优异性。其实验结果统计如表1所示。表中p1、p2、p3分别代表上述三个实验,即p1是原网络上得到的结果,p2是加入八度卷积后的结果,p3是在p2实验基础上加入中心损失函数与交叉熵损失函数之后得到的实验结果。

Table 1. Based on the results of facial classification experiments in the five countries
表1. 基于五国人脸分类实验结果
由上述实验结果图和实验总结表可知,在原始模型上加入八度卷积后,MobileNetV1_075、MobileNetV1_100、MobileNetV2_100的三个模型上Accuracy分别提升了1.92%、0.77%、1.16%。Error-top 1分别下降了0.336%、0.058%、0.031%。在此基础上加入中心损失函数后,三个网络模型的精度均达到了最高,分别是86.82%、87.84%、85.57%,相较原网络分别提升了6.78%、4.63%、3.59%。Error-top 1分别下降了0.866%、0.551%、0.513%,均在该方法上达到了最低。对比MobileNetV1_075和MobileNetV1_100两组实验结果,我们可以看出在不改变其他参数仅改变宽度因子α时,其实验结果得到了提升,证明了宽度乘子对实验结果影响的有效性。对比MobileNetV1_100和MobileNetV2_100实验结果可以看出,在本实验中MobileNetV2网络效果低于MobileNetV1网络,且训练时间是MobileNetV1网络上的1.5倍。
6. 总结与展望
本文提出将八度卷积应用到五国人脸(中国、日本、韩国、泰国、印度)分类识别中,有效减少了冗余提升了精度,且在使用了中心损失函数和交叉熵损失函数相结合后,其精度达到了最高,整个实验结果中,精度最高可达到87.84%,其Error-top 1达到了0.120%,实验结果验证了本文提出改进方案的可行性,能有效提升准确率。本文的实验也说明了MobileNet网络中超参数α不同时实验效果的差异性,有效区分各国人脸信息在未来是一个重要的研究领域,为构建和谐安全幸福的良好社会环境有着不可替代的作用。在后续的学习研究中时,主要着力于解决以下问题:
1) 人脸数据样本对于区分各国人员起着至关重要的一步,因此如何能构建更好的各国人脸数据集应更一步的研究。且本文所构建的人脸数据集仅限于这五国的明星,并没有很好地包含各个国家不同年龄等因素,这需要在后续研究中不断改进。
2) 由于本文选取的网络模型是“轻便型”网络模型,因此可以针对此构建一个可适用于移动端口等的各国人员分类识别系统。
基金项目
国家自然科学基金(61862061,61563052)。
NOTES
*通讯作者。