1. 引言
随着国家大数据战略的发展,数据要素已经成为我国经济发展的重要驱动力。2020年4月9日,《中共中央、国务院关于构建更加完善的要素市场化配置体制机制的意见》发布,要求加快培育数据要素市场,推进政府数据开放共享,提升社会数据资源价值,加强数据资源整合和安全保护 [1]。我国关键基础设施运营企业,比如能源、金融、电信等行业拥有海量的客户数据,不仅反映了社会用能、经济运行等宏观情况,而且反映了居民生活、企业经营等具体情况,价值巨大,社会开放共享需求迫切。然而近年来数据安全事件频繁发生 [2],国家法律法规对于个人信息保护越来越严格 [3] [4] [5],因此我们必须在保障数据安全的前提下,输出数据价值。
我国关键基础设施运营数据不仅会在内部各个部门间流转,也会向工商、司法等政府部门,金融、能源、互联网公司等企事业单位提供。数据一旦对外提供,数据的管理控制权将随之转移,如果发生数据泄露,责任难以定位。《中华人民共和国网络安全法》规定网络运营者应当按照网络安全等级保护制度要求,防止网络数据泄露或者被窃取、篡改 [6]。《数据安全管理办法(征求意见稿)》规定网络运营者有履行数据安全保护义务 [7]。如果责任不能厘清,则极大限制了数据管理者的数据共享积极性,因此采取必要的技术手段,尽可能避免数据泄露,加强数据泄露之后的定责能力,十分必要。
文章提出了一种基于自适应嵌入的高抗毁数据水印方法,并采用当前主流的微服务技术架构,针对数据离线对外提供场景,提供高抗毁、高仿真的数据水印,一旦数据被恶意泄露,即可根据数据水印,定位责任环节,同时数据水印也可警示数据使用人员的安全意识,防止数据管理不当,非法泄露。
2. 相关知识
2.1. 概述
数据水印技术又被称为数字水印、数据库水印,能够将特定的标识信息嵌入到数字产品的内容当中,例如数据库、文档、软件等,同时不影响原数字产品的使用价值,也不容易被第三方探知和破坏。当数字产品流转给用户使用时,用户只能在许可范围内使用该数字产品,不能再次转发给第三方使用,这既符合绝大部分商品销售的商业规则,也是数据广泛开发共享的基本保证。使用的数据水印技术,不仅是对数据权属的标识,而且可以准确的进行数据泄露责任追溯,保护数据提供者的利益。
2.2. 技术现状
2002年Agrawal和Kiernan首次提出数据库水印的概念,以此来标记哪些是数值型的数据 [8]。随着数据水印技术的发展,总的来说,大致可分为失真和无失真的两类水印 [9]。数据水印的嵌入首先应该根据不同业务的差异化需求,尽量保证数据的可用性;其次数据水印应该具有完整唯一标识,保证数据泄露时溯源的准确性;最后数据水印应该具有很强的隐蔽性和抗毁性,保证数据在流转过程中,水印不会被攻击破坏。为了同时实现上述三个目标,国内外学者提出多种数据水印方法。一种思路是基于差异扩展的数据水印,同时考虑失真约束,控制数据水印的嵌入率,例如Bhattacharya和Cortesi提出的将元组划分置换后嵌入水印方法 [10]。为了优化嵌入效果,有学者提出了遗传算法和直方图移位算法 [11],但是前期计算量非常大。
为了更好的保证数据水印嵌入率,同时保证数据水印的隐蔽性和抗毁性,文章针对使用范围较广的数值型数据,开展了基于自适应嵌入的高抗毁数据水印技术研究,包括数据水印自适应嵌入,以及数据水印精准提取,并得到了实验验证。
3. 算法设计
3.1. 自适应分组
为保证水印更加均匀地分散在目标数据中,我们设计了自适应分组算法,根据不同数据库的内容特性,计算最优的分组方式,具体算法如下:
(3.1)
其中,
代表第i行第j列的属性值,
代表序号为i的元组主键值,
代表编码后的水印码字长度,
为分组序号,参数m的取值范围由数据水印位数和目标数据量之间的幂的逆运算值取整确定,一般为自然数。
通过上式,我们把第j列中所有属性项分为
组,每一组用来嵌入一位水印信息,很明显,当m大于0的时候,每一位水印嵌入到了
分组上。为了评估m的取值对于最终抗毁性的影响,我们定义了计算分组的离散度。
我们首先对第j列属性按照主键值进行排序:
(3.2)
保证
,
代表排序后的第i个元组。排序后按照下式计算分组的离散度:
(3.3)
其中,
表示所有元组排序号的均值,
的定义如式(3.1)。
最后,在根据下式选择使
最大的m值,计算最终的分组个数
。
(3.4)
即为自适应分组算法的分组结果,该分组方式能够保证水印在数据库中的分布更加均匀和离散,能够有效抵抗删除、更新等攻击。
3.2. 自适应嵌入强度
为保证数据库水印的抗毁性,特别是对于删除、更新等攻击的抵抗能力,文章通过计算适宜的水印嵌入强度,在单个属性项中嵌入合适的多位水印,在提高水印嵌入率的同时又兼顾了数据可用性,保证数据失真较小。
我们根据每一列的属性项的两个统计特性来计算嵌入强度:
(3.5)
表示第j列属性值的均值,n表示第j列属性列的属性个数。显然,均值越大,我们的修改量也可以更大,且不引起明显失真。
(3.6)
表示第j列属性值的方差,该值是用来判断该列的数值抖动情况,如果
的值较小,说明该列数值变化平稳,为了避免明显失真,应使修改量较小;反之,可以嵌入较大容量的水印信息。
针对上述统计特性,我们设计了强度判断公式:
,
(3.7)
上式中,
为均值条件下的嵌入强度等级,
为方差条件下的嵌入强度等级,
和
为设定的阈值,可根据实际情况进行调整。
(3.8)
为最终确定的嵌入强度等级,为保证数据失真较小,我们取均值条件下和方差条件下较低的那一个等级作为最终的强度等级。
3.3. 数据水印提取
数据水印的精准提取,关键在于数据水印标识位的识别,标识位识别出来后,就可以根据既定规律,准确提取出数据水印。由于在提取端,无法得知属性列是否嵌入水印,提取标识位是完全盲提取,因此需要对属性列进行遍历查询,确定是否存在标识位。
对于第j列中的一个属性项
,首先通过下式计算其标识位信息:
(3.9)
其中Q为数值型数据水印的量化公约数,原始属性项
通过Q的映射,得到数据水印标识。如果
与Q取模不等于0,说明该属性项不是标识为,即为error;如果
与Q取模等于0,可进一步进行取模运算,判断该位标识是0还1。
为对j列中所有属性项通过上式(3.9)计算其标识位信息,然后进行标识位统计:
(3.10)
其中||运算符表示返回集合中有效数值的个数,
用于标记提取出来的
位标识位,而统计完成之后,第
位标识位通过下式计算获得:
(3.11)
如果是自然采集得来的数据,
值是接近近于0.5的。当进过标识位映射之后,
值要么接近于0,要么接近于1;当数据水印受到局部破坏时,
值会向0.5靠拢。
通过遍历匹配,可以完整的提取标识位,识别当前属性列是否含有标识位信息。
4. 软件设计及应用结果分析
4.1. 微服务能力设计
在互联网+新业态下,服务商为了追求客户粘性,业务升级和迭代迅速,因此相关能力微服务化设计成为业界趋势。文章提出的自适应嵌入的高抗毁数据水印溯源算法,也设计了微服务能力,供前端服务或者其他后台能力调用,设计架构如下图1。
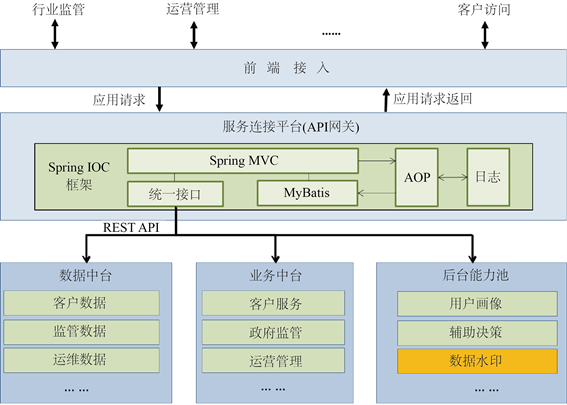
Figure 1. Design of micro-services for data watermark traceability
图1. 水印溯源能力微服务设计
自适应嵌入的高抗毁数据水印溯源算法模块在微服务软件框架下,可以以一个独立的模块部署在虚拟化容器中,并与数据流转的申请审批、脱敏处理、日志审计应用协同工作。当前端应用发起一个业务请求时,由业务中台中的应用服务按需调用数据中台数据和后台能力池中功能,如果是向外流转数据,在准备数据的同时,调用数据水印能力进行数据处理,然后流转数据。当安全人员接到数据泄露举报时,可以通过运营管理接口,调用数据水印溯源能力,精准定位是哪一位数据使用者泄露了数据。
4.2. 模拟验证
文章模拟了电力营销客户数据流转共享的场景,比如数据分析人员进行客户经营分析的业务,在数据外发前添加数据水印,如果向外流转的数据发生泄露,验证是否可以通过已添加的数据水印进行溯源。
(1) 验证环境
模拟验证的软硬件环境,包括1台关系数据库服务器,1台应用服务器(部署数据水印溯源服务),和1台导出文件服务器用于临时存储生成的数据文件(表1)。

Table 1. Software and hardware verification environment
表1. 模拟验证软硬件环境
(2) 模拟样本数据
模拟样本数据主要采用个人基础信息和用电数据,包括姓名、电子邮箱、手机号码、用户名、密码,还包括客户当日用电量、当月累计用电量、本年度每月的用电量等等。样本数据的来源主要通过各属性的特点由代码随机自动生成,共计20000条。部分样例数据如下表2。
Table 2. Some verification sample data
表2. 部分模拟样本数据
(3) 水印添加及溯源结果
为了验证数据水印的隐蔽性,针对上述数据文件添加数据水印,并流转至数据运维人员、数据分析人员、业务运营人员、客户服务人员和安全管控人员,数据分析生成的相关统计曲线在容忍的精度范围之内,相关人员均未发现数据水印。
为了验证溯源的准确性及抗破坏性,针对上述数据文件的六种数据泄露情况进行溯源验证:
第一种情况:全量的20000条已经添加水印的数据文件发生泄漏;
第二种情况:已下载的数据文件随机10000条数据发生泄漏;
第三种情况:已下载的数据文件随机1000条数据发生泄漏;
第四种情况:已下载的数据文件随机100条数据发生泄漏;
第五种情况:已下载的数据文件随机10条数据发生泄漏;
第六种情况:已下载的数据文件随机5条数据发生泄漏。
每种数据泄露情况重复验证100次,局部泄露的数据范围随机选择,可以当数据全量泄露,或者少量泄露(大于100条),溯源的准确率均达到100%。而当泄露数据为5条时,数据水印遭到破坏,溯源的平均准确率约为60% (表3)。
Table 3. Data watermark tracing results
表3. 数据水印溯源结果
5. 总结
文章面向数据共享流转业务场景,开展了基于自适应嵌入的高抗毁数据水印方法,可灵活针对目标数据的特性,在保证目标数据可用性的前提下,尽可能的保证数据水印嵌入率,提高数据水印的抗毁性。经设计原型验证,本文提出的水印溯源技术具有较好的溯源准确性以及抗破坏性。文章研究成果针对数值型数据,虽然大部分数据分析人员的数据需求在于数值统计分析,然而随着社会数据安全意识的提高,以及国家个人信息保护法律法规的陆续出台,文本型数据和自然语言型数据也将是数据流转中安全防护的重点,开展文本型数据和自然语言型数据的水印溯源算法研究将是需要进一步研究的方向。
基金项目
文章研究成果由国网江苏省电力有限公司科技项目“电力营销敏感数据安全防护关键技术研究及应用”(项目编号Grand No.J2020007)支持。