1. 引言
时间序列的一个重要研究内容就是趋势预测,传统的利用故障趋势预测都是基于历史数据信息,历史数据信息决定未来时间序列的趋势,这种预测方法的缺点在于过于依赖历史数据信息,而忽略了预测自变量之间的相关性,且忽略了外部因素对时间序列趋势的影响 [1] [2] [3] [4]。而多元时间序列的建模与预测方法则考虑了多元变量之间的相关性,充分发挥协方差或相关系数在预测过程中的作用,相对于一元时间序列建模与预测更加有效合理,因此本文针对产品多性能参数的特点,将多元时间序列分析方法应用于可靠性建模与寿命预测。
基于多元时间序列的多性能参数退化建模方法,并利用Copula函数来描述多性能参数间的相关性,可以解决基于单性能参数对退化过程描述和寿命预测的结果不够准确,以及考虑多性能参数间的相关性及受环境干扰和人为因素的交互影响时建模困难的难题。
2. 多性能退化参数的时间序列建模
2.1. 一元时间序列模型
实际工程中的单性能参数退化量时间序列多为方差平稳时序,根据方差平稳时序分解原理,可分为确定性部分和平稳随机性部分。以ft表示确定性部分,即方差平稳时序的均值,并以一元回归模型描述,rt表示平稳随机性部分,则组成的单性能参数的一元时序模型为:
(1)
其中,ft为以时间t为自变量的回归函数,p为自回归模型阶数;
为自回归参数,
为滑动平均参数;
为均值为0,方差为
的高斯白噪声。若考虑多个性能参数的时序模型,首先想到的是将每个性能参数分别利用一元时间序列模型描述,而后组成方程组形式,此时则有:
(2)
其中,fit为第i个性能参数的确定性部分,rit为第i个性能参数的平稳随机性部分,fi(t)为第i个性能参数的以时间t为自变量的回归函数,ri(t-j)为第i个性能参数在t-j时刻下的平稳随机性部分,εit为第i个性能参数的白噪声,
。
可见,多性能参数的一元时序模型方程组公式(1)的本质仍然是只能分别反映单个性能参数的退化过程,而不能够反映各性能参数间的相关性。
为弥补多性能参数的一元时序模型公式(2)不能够反映各性能参数间的相关性的不足,并同时考虑各性能参数之间及其自身不同时刻变化的多元相关性,本文借鉴Copula理论来解决多性能参数间的相关性问题。
2.2. Copula函数
Copula函数通过构造多元随机变量的概率分布函数,来描述多元变量间的相关结构,能较好地解决多元随机变量的相关性问题 [5]。
根据Sklar定理,由n个性能参数组成的n维随机向量
表示,其联合累积概率分布函数可用一个Copula函数C表示,即:
其联合概率密度函数可表示为:
(3)
其中,c为Copula函数C的密度函数。常用的Copula函数主要有:多元正态Copula函数、多元t-Copula函数、阿基米德Copula函数等。
多元Copula函数的仿真:
对于从m维Copula函数
中产生随机数,第j维边缘分布可表示如下:
其中,
,
。则,已知前j-1个变量的条件分布可以表示如下:
(4)
Copula函数产生随机变量的一般过程如下:
a) 从均匀分布U (0,1)上随机产生一个u1;
b) 已知u1,利用式(4),得到随机变量u2的条件分布C2(u2|u1),并在其中随机产生u2;
……
m) 已知u1,u2,um-1,利用式(4)得到随机变量um的条件分布
并在其中随机产生um。
通过上述随机数产生过程,就可以得到一组m维Copula函数的随机数(u1 u1,
, um)。
2.3. 基于Copula-ARMA时序模型的多性能退化参数建模
工程实际中产品失效通常是多个错综复杂的性能参数综合退化作用的结果,多性能参数退化量时序通常为多元方差平稳时序,即该时序的均值是一组关于时间t的确定性函数,当对该时序减去均值后,就是一个多元平稳时序。显然,同一产品多个性能参数退化量时序之间会具有一定的相关性。
以Yt表示t时刻多性能参数退化量向量,将Yt分为确定性部分和平稳随机性部分,Ft 表示Yt的确定性部分,即多元方差平稳时序的均值向量,由于多参数时序的均值向量为时间t 这个单自变量的确定性函数,因此仍可对其以一元回归方程组模型描述,Ut表示Yt的平稳随机性部分并以多元自回归 (也称向量自回归)模型描述。将一元回归方程组模型与多元自回归模型结合,得到多性能参数退化量时序的多元Copula-ARMA时序模型表示如下:
(5)
其中:
,
,
将(5)式展开,可得到:
(6)
根据Copula函数的性质可知,对变量做严格的单调递增变换,相应的Copula函数不变。
上述模型,存在
,因此,则有:
即连接
的Copula函数
和连接
的Copula函数相同。这样我们就可以将多性能参数之间的相关性简化为研究残差项之间的相关性。对于一个确定的ARMA模型,高斯白噪声是唯一的“干扰源”,因此,我们可以利用高斯白噪声序列的相关程度来描述多性能退化参数时间序列的空间相关性。用一个Copula函数
来描述高斯白噪声的相关性,即:
式中,
为每个白噪声序列的标准差;
为标准正态分布函数。
因此式(6)的模型可进一步改写为:
(7)
3. 可靠性预测
基于上述假设和理论分析,基于多元混合时序分析的多性能参数加速退化试验产品寿命预测方法主要包括以下五个步骤:
第1步:开展加速性能退化试验并监测多性能退化参数退化数据及数据的预处理,由试验设备采集到的性能参数的原始退化量时序通常难以直接对其进行时序分析,为了避免过大的退化量值对时序分析造成的影响,提高性能参数退化量时序模型的拟合精度,并且统一原始退化量时序的初值以及退化失效的判据,应对每个性能参数的原始退化量时序分别作初值化的预处理。
第2步:对试验数据进行多元时间序列建模,主要分为确定性部分,即趋势项,和平稳随机项部分,趋势项和随机项部分的确定方法如下:
① 趋势项的确定:
由于产品的各性能退化参数的总体变化趋势具有单调性,均为关于时间的确定性函数,因此趋势项
采用一元单调回归方程组模型来描述,主要包括线性或单调非线性一元回归方程组,即:
其中,F(t)为以时间t为自变量的n维一元单调回归方程组。fk(t)为第k个性能参数的一元单调回归方程,
。
对于性能参数单调性较好,且信号特征相对比较简单的退化数据,可直接对每个性能特征参数的原始数据序列进行回归拟合,获得其趋势项拟合参数。但是对于复杂信号特征,这种拟合方法偏差较大,因此可选择EMD算法进行提取,EMD算法能够直接从原始数据序列中提取趋势项,可大大降低直接对原始数据进行数据拟合的误差,关于EMD算法的原理详见参考文献 [6]。
② 随机项确定:
随机项部分主要是利用ARMA时间序列进行拟合,从原始数据Yt减去趋势项部分Ft后,得到随机项部分的数据序列,然后对随机项部分进行ARMA时间序列的拟合,得到ARMA模型的参数,最后对多性能参数的相关Copula函数进行参数估计。
第3步:退化失效预测
确定好多性能参数退化量时间序列的结构,如式(7)所示,再利用Copula函数模拟产生相关性的白噪声序列,然后再结合拟合得到ARMA模型产生多维随机项序列,再结合趋势项部分,这样就可对多元时间序列对多性能参数进行预测。根据性能退化参数历史数据获得多元Copula-ARMA时序模型的参数后,就可以对其预测,预测过程可分为两个阶段:
阶段一:产生L个服从n维Copula函数C的高斯白噪声序列
。
① 由上述方法产生n元Copula函数的随机数向量(u1 u1,
, un);
② 令
,得到服从n元Copula函数的高斯白噪声序列(ε1 ε1,
, εn)。
重复阶段一L次,产生长度为L的n元高斯白噪声序列
。
阶段二:基于ARMA时序模型对多性能参数数据进行预测。
① 根据拟合得到趋势项回归方程,将时间变量代入回归方程,预测多性能退化参数的趋势项数据fk(t);
② 根据随机项
,
及εk,t利用ARMA递推公式产生第k个性能特征参数在t时刻的随机项的值uk,t;其中,当t < 0时,εk,t和rk,t的取值设为0;
③ 令
,这样即可得到产品第k个性能参数在t时刻的预测值。
对于单调退化型产品,其失效定义为首次穿越失效阈值的时间,如果产品具有多个性能参数,工程实际中,一般是由最先穿越失效阈值的性能参数所决定,根据竞争失效的判别原理,在给定各性能参数的失效阈值后,再由多性能退化参数的多元Copula-ARMA时间序列模型预测得到的各性能参数的预测值,外推得到各性能参数穿越失效阈值的时间,得到伪失效寿命数据。
第4步:利用拟合优度检验法对各应力水平下得到的伪失效寿命数据进行寿命分布的假设检验,选择伪失效寿命数据可能服从的分布,而后将外推得到的伪失效寿命数据视为完全寿命数据。
4. 实例分析
为了验证方法的有效性,按照文献 [7] 给出的方法仿真产品多性能参数退化轨迹,利用Monte Carlo仿真方法进行验证。假设产品在温度应力下进行加速退化试验,应力水平为:T1 = 333 K, T2 = 363 K, T3 = 393 K, T4 = 423 K,共4个加速应力水平,产品工作的正常温度应力T0 = 293 K。各应力下的样本量为10,测试时间为:t1 = 100,t2 = 200 h,
, t24 = 2400 h共设置24个监测时间点。假设产品有三个性能参数,且服从三元联合正态分布,失效阈值分别设置为:D1 = 50, D2 = 60, D3 = 40。
利用Monte Carlo仿真三个性能参数的退化数据,具体步骤如下:
第1步:从标准正态分布中产生三个独立同分布的随机数,z1t, z2t, z3t。
第2步:令
,
,
其中
,
。
第3步:令
,
,
式中,
可由下式得出:
其中,
。
根据上述第1步至第3步步骤就可以产生各应力水平下24次监测的三个性能参数的退化数据[x(1)(t) x(2)(t) x(3)(t)]。
第4步:重复第1步至第3步10次,就可以产生各应力水平下,10个样本在各测试时刻的三个性能参数的退化数据,仿真试验完毕。
按照上述步骤,就可得到4组应力水平下的仿真多性能退化数据,T1 = 333 K时仿真的一个样本的多性能退化参数的试验数据如图1所示。
下面就对仿真试验数据进行多元Copula-ARMA时间序列建模:
第1步:分别对各应力水平下,各样本的三个性能退化参数的退化数据进行趋势项提取,由于退化数据为线性退化,我们采用一元线性回归方程(
)拟合的方法提取趋势项,以图1中的其中一个样本为例,对其退化数据进行趋势项提取。

Figure 1. Simulation of degradation data of multi-performance parameters
图1. 仿真多性能参数退化数据

Figure 2. Linear regression fitting of trend term
图2. 趋势项线性回归拟合
趋势项提取结果如表1所示,性能参数3的拟合精度较差,这主要由于一元线性回归拟合是最为简单的趋势项提取方法,因此对于信号特征相对复杂的退化数据,可利用EMD分解的趋势项提取方法,提高趋势预测精度。

Table 1. Trend item extraction of performance degradation data
表1. 性能退化数据趋势项提取
第2步:将时间变量t代入第1步拟合得到的趋势项回归方程,然后利用原始数据减去趋势项,得到性能退化数据的随机项原始数据序列。然后利用ARMA随机项时间序列模型建模,确定ARMA时间序列结构如下:
性能特征参数1:ARMA(4, 3):
性能特征参数2:ARMA(4, 3):
性能特征参数3:ARMA(2, 2):
第3步:利用Copula函数构建三个性能特征参数之间的相关性,首先,根据随机项原始数据序列检验三个性能特征参数之间的相关性,而后对其联合Copula函数的参数进行估计,参数估计值如表2所示,得到三个性能特征参数Copula函数结构,通过最小经验距离比较,Gumble Copula函数与理论值之间的距离最小,因此采用Gumbel Copula函数描述相关性,结构如下式:
第4步:通过上述第1步至第3步,就确定了式(7)的多性能特征参数Copula-ARMA多元混合时间序列模型,然后可对多性能特征参数的退化趋势进行预测。
第5步:根据预先给定的退化失效阈值,外推性能退化轨迹首次穿越失效阈值的时间,即失效时间,然后按照拟合优度检验法对各应力水平下得到的伪失效寿命数据进行分布的假设检验,选择伪失效寿命数据可能服从的分布形式。将外推得到的伪失效寿命数据视为完全寿命数据,通过模型对伪寿命数据进行假设检验,发现寿命服从威布尔分布。限于篇幅,在此不再给出第5步至第6步的详细过程,寿命统计原理详见参数文献 [8]。
Table 2. Estimated values of Copula parameters
表2. Copula参数估计值
第6步:根据加速模型外推得到产品在正常工作应力水平293 K下的寿命特征信息,可靠度预测的函数如式(8)。
(8)
基于联合概率密度求解多性能参数退化数据的可靠度公式如下:
(9)
一般很难用解析积分的方法求解式(9)的可靠度,需借助数值积分的方法进行近似,求解过程非常复杂,对计算机硬件要求高。如图3所示,两种方法可靠性预测对比:
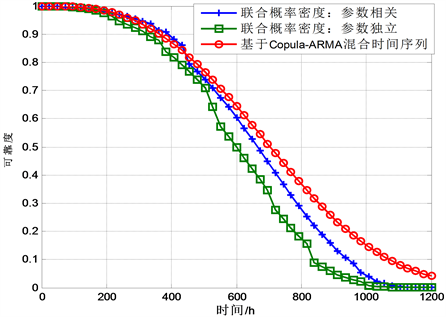
Figure 3. Reliability prediction results
图3. 可靠性预测结果
从可靠性预测曲线可以看出,基于Copula-ARMA混合时间序列的方法预测的可靠度结果非常接近于仿真理论曲线,然而,通过多元正态联合概率密度的积分求解非常复杂,且本文是通过仿真方法在已知联合概率分布的均值向量和协方差矩阵基础上得到可靠度的,在工程实际中利用多元联合概率密度求解时还需要对协方差矩阵进行参数估计,这样就更增加了求解过程的复杂性。而Copula-ARMA能够更好的保持原始数据的所有统计特性,时间序列模型建立的退化模型将退化数据分为趋势项和随机项,在一定程度上提高了退化模型假设带来的误差,且通过Copula函数描述相关性,大大降低了联合概率密度函数求解的复杂性。
5. 小结
在工程实际中,大多数电子产品具有多个性能特征参数,基于多个性能参数退化数据的可靠性预测问题更加复杂,解决问题的方法主要有两种,一是假设多个性能参数之间相互独立,然后按照串联系统的方法进行处理,这种方法具有简单快速的优点,缺点是分析不够全面,预测结果误差较大,二是充分考虑性能参数之间的相关性,如联合密度法和状态空间法,缺点是当性能参数较多时,计算量较大,且建模复杂。本文从多元预测的角度分析,提出了基于Copula-ARMA混合时间序列的多性能退化特征量建模方法,有效解决了多元性能退化数据相关条件下建模复杂、计算量大的问题,相对于一元时间序列,可靠性预测的精确度更高,结果更加客观。即考虑多性能参数随时间的退化又可将互相之间的相关性进行描述,弥补了多元线性回归方法的不足。多元时间序列能够很好地解决多性能参数退化是非平稳随机过程的问题,将多性能退化参数的退化过程分解为非平稳部分和平稳部分,而后对其分别采用对应的模型进行建模描述。