1. 实验方法与步骤
首先在一元线性模型的基础上,推导多元线性模型相关系数的求解公式;之后利用产生的随机数分别按不做处理、做中心化处理、做标准化处理计算相应的未知参数;最后通过比较计算得到的未知参数,分析中心化和标准化处理的好处。
2. 实验过程
2.1. 公式推导
2.1.1. 一元线性回归未中心 [1]
对
记
,
则有
。
其中,
,
。
其中
。
则
。
2.1.2. 一元线性回归的中心化
对
即
其中
。
对数据
作中心化处理,利用新的n组数据
,
。
建立线性回归方程
。
记
记
记
,
则有
。
2.1.3. 多元线性回归的中心化
样本数据的中心化公式:
其中:
其中
用最小二乘原理求出参数B的估计量
:
根据最小二乘原理,需寻找一组参数估计值
,使残差平方和
最小。
于是参数的最小二乘估计值为
中心化回归模型只包含k个参数估计值
。
对于(10):
2.1.4. 多元线性回归的标准化
样本数据的标准化公式:
同中心化类似,用最小二乘方法,求出标准化的样本数据
的经验回归方程,记为
。
其中:
为y对自变量
的标准化回归系数,标准化包括了中心化。
标准化回归系数与最小二乘回归系数之间存在关系式
。
其中:
为
的样本标准差,普通最小二乘估计
(或中心化回归系数)表示在其他变量不变的情况下,自变量
的每单位的绝对变化引起的因变量均值的绝对变化量。
标准化回归系数
表示自变量
的1%相对变化(相对于标准差)引起的因变量均值的相对变化百分数(相对于标准差)。
由样本观测值
,分别计算
与
的简单相关系数
,得自变量样本相关系
数矩阵
。
若记:
,表示标准化的设计阵,则相关系数矩阵可以表示为
相关系数矩阵R是对称矩阵,若
满秩,则R为对称正定矩阵。
2.2. 实验数据运行
2.2.1. 一元线性模型 不做处理
matlab程序:
x_1=[143 144 145 147 148 150 153 154 155 156 157 158 159 160 161 162]';
X=[ones(16,1),x_1];
Y=[87 85 88 91 92 90 93 95 98 98 97 95 97 99 100 102]';
[b,bint,r,rint,stats]=regress(Y,X)
t=1:16;
figure(1);
y_fitting=X(t,:)*b;
plot(t,y_fitting,'r-',t,Y(t,:),'b-',t,abs(y_fitting-Y(t,:)),'k-');
legend('红--拟合值','蓝--实际值','黑--误差值');
text(8,50,strcat('相关系数R=',num2str(stats(1,1))));
text(8,40,strcat('F=',num2str(stats(1,2))));
text(8,30,strcat('P=',num2str(stats(1,3),'%f')));
nhfcsl=strcat('拟合方程式Y1=',num2str(b(1,1)),'+',num2str(b(2,1)),'*x1');
text(8,20,nhfcsl);
title('线性回归方程拟合结果');
xlabel('样本点');ylabel('y');
figure(2);
u1=rint(:,1);
I1=rint(:,2);
plot(t,I1,'b-',t,r,'R*',t,u1,'g-');
legend('蓝--残差95%置信区间的上限','红--残差值','绿--残差95%置信区间下限');
xlabel('样本点');ylabel('残差值');
运行结果如图1和图2:
stats = 0.9047132.8768 0.0000 2.5357
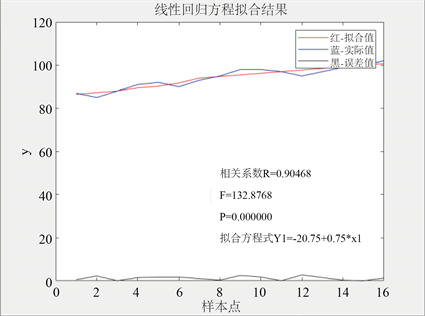
Figure 1. Fitting results of linear regression equation with one variable
图1. 一元线性回归方程拟合结果
由以上运行结果可得到:
参数的估计:
回归方程为:
(1)
的区间估计:
的区间估计:
。
拟合优度(回归平方和和总离差平方和的比值)
,表示回归值对观测值的拟合程度,值越接近1,说明回归直线对观测值的拟合程度越好。
F值(方差检验量)
,是整个模型的整体检验,值越大,说明回归方程越显著。
p值
,其值小于0.05或0.01时说明系数通过检验。
结论:将残差的置信上下限和实际残差值绘制出来后可看到,残差值都在区间内,回归模型正常;将实际数据值和拟合值分别绘制成折线图之后可看到,两条曲线非常接近,可从直观上说明拟合程度较好。从数值上,拟合优度接近1,方差检验量也较大,p值也说明系数通过了检验。故上述回归方程拟合较好。
2.2.2. 一元线性模型 做中心化处理(减均值)
x_1=[143 144 145 147 148 150 153 154 155 156 157 158 159 160 161 162]';
a_1=mean(x_1')
X=[ones(16,1),x_1-a_1];
Y=[87 85 88 91 92 90 93 95 98 98 97 95 97 99 100 102]';
b_1=mean(Y')
Y=Y-b_1;
[b,bint,r,rint,stats]=regress(Y,X)
t=1:16;
类似地,可得到:
参数的估计:
回归方程为:
又
代回原始数据得:
即
(2)
的区间估计:
的区间估计:
拟合优度
方差检验量
p值
。
2.2.3. 一元线性模型 做标准化处理(减均值再除以标准差)
x_1=[143 144 145 147 148 150 153 154 155 156 157 158 159 160 161 162]';
a_1=mean(x_1')
s_x=std(x_1)
X=[ones(16,1),(x_1-a_1)/s_x];
Y=[87 85 88 91 92 90 93 95 98 98 97 95 97 99 100 102]';
b_1=mean(Y')
s_y=std(Y')
Y=(Y-b_1)/s_y;
[b,bint,r,rint,stats]=regress(Y,X)
t=1:16;
参数的估计:
回归方程为:
又
代回原始数据得:
即
(3)
的区间估计:
。
的区间估计:
。
拟合优度
方差检验量
p值
。
2.2.4. 多元线性模型 不做处理
matlab程序:
x_1=[143 144 145 147 148 150 153 154 155 156 157 158 159 160 161 162]';
x_2=unifrnd(2,4,16,1);
x_3=rand(16,1);
X=[ones(16,1),x_1,x_2,x_3*10];
Y=[87 85 88 91 92 90 93 95 98 98 97 95 97 99 100 102]';
[b,bint,r,rint,stats]=regress(Y,X)
t=1:16;
figure(1);
y_fitting=X(t,:)*b;
plot(t,y_fitting,'r-',t,Y(t,:),'b-',t,abs(y_fitting-Y(t,:)),'k-');
legend('红--拟合值','蓝--实际值','黑--误差值');
text(2,50,strcat('相关系数R=',num2str(stats(1,1))));
text(2,50,strcat('F=',num2str(stats(1,2))));
text(2,50,strcat('P=',num2str(stats(1,3),'%f')));
nhfcsl=strcat('拟合方程式Y1=',num2str(b(1,1)),'+',num2str(b(2,1)),'*x1','+',num2str(b(3,1)),'*x2','+', num2str(b(4,1)),'*x3');
text(2,50,nhfcsl);
title('线性回归方程拟合结果');
xlabel('样本点');ylabel('y');
figure(2);
u1=rint(:,1);
I1=rint(:,2);
plot(t,I1,'b-',t,r,'R*',t,u1,'g-');
legend('蓝--残差95%置信区间的上限','红--残差值','绿--残差95%置信区间下限');
xlabel('样本点');ylabel('残差值');
运行结果如图3:
stats = 0.9069 38.9804 0.0000 2.8884

Figure 3. Fitting results of multiple linear regression equations
图3. 多元线性回归方程拟合结果
由以上运行结果可得到:
参数的估计:
(4)
的区间估计:
。
的区间估计:
。
的区间估计:
。
的区间估计:
。
拟合优度(回归平方和和总离差平方和的比值)
,表示回归值对观测值的拟合程度,值越接近1,说明回归直线对观测值的拟合程度越好。
F值(方差检验量)
,是整个模型的整体检验,值越大,说明回归方程越显著。
p值
,其值小于0.05或0.01时说明系数通过检验。
结论:将残差的置信上下限和实际残差值绘制出来后可看到,残差值都在区间内,回归模型正常;将实际数据值和拟合值分别绘制成折线图之后可看到,两条曲线非常接近,可从直观上说明拟合程度较好。从数值上,拟合优度接近1,方差检验量也较大,p值也说明系数通过了检验。故上述回归方程拟合较好。
2.2.5. 多元线性模型 做中心化处理(减均值)
x_1=[143 144 145 147 148 150 153 154 155 156 157 158 159 160 161 162]';
x_2=unifrnd(2,4,16,1);
x_3=rand(16,1)*10;
a_1=mean(x_1')
a_2=mean(x_2')
a_3=mean(x_3')
X=[ones(16,1),x_1-a_1,x_2-a_2,x_3-a_3];
Y=[87 85 88 91 92 90 93 95 98 98 97 95 97 99 100 102]';
b_1=mean(Y')
Y=Y-b_1;
[b,bint,r,rint,stats]=regress(Y,X)
t=1:16;
类似地,可得到:
参数的估计:
又
代回原数据:
即
(5)
的区间估计:
。
的区间估计:
。
的区间估计:
。
的区间估计:
。
拟合优度
,方差检验量
,p值
。
2.2.6. 多元线性模型 做标准化处理(减均值再除以标准差)
x_1=[143 144 145 147 148 150 153 154 155 156 157 158 159 160 161 162]';
x_2=unifrnd(2,4,16,1);
x_3=rand(16,1)*10;
a_1=mean(x_1')
a_2=mean(x_2')
a_3=mean(x_3')
s_1=std(x_1)
s_2=std(x_2)
s_3=std(x_3)
X=[ones(16,1),(x_1-a_1)/s_1,(x_2-a_2)/s_2,(x_3-a_3)/s_3];
Y=[87 85 88 91 92 90 93 95 98 98 97 95 97 99 100 102]';
b_1=mean(Y')
s_y=std(Y)
Y=(Y-b_1)/s_y;
[b,bint,r,rint,stats]=regress(Y,X)
t=1:16;
参数的估计:
又
代回原数据:
即
(6)
的区间估计:
。
的区间估计:
。
的区间估计:
。
的区间估计:
。
拟合优度
方差检验量
p值
。
3. 实验结论
对一元线性回归模型,由以上的数据模拟可看出,不做处理,做中心化处理和做标准化处理均没有改变
的值;未代回原始数据之前,和不做处理相比,中心化处理后的线性回归方程少了常数项,相当于是做了坐标轴的平移,标准化处理后的线性回归方程不仅少了常数项,系数也发生了改变,相当于改变了坐标的分度值;但代回原始数据之后,三个线性方程相同。
对多元线性回归,可以看出,做了中心化处理之后,得到的方程不含常数项,其他系数和
值均相同,且代回原始数据之后得到和不做处理相同的回归方程;做了标准化处理后,各系数的值均有不同程度的变化,由于有随机数的参与,此时无法准确比较,但观察数据,不做任何处理时计算出来的结果会由于值的大小,比如第一行数据和第二行数据相差近100倍,产生的相应的估计有较大的差距。但透过数据的变化情况,两个因素对响应变量的影响又很接近,这也就告诉我们,在比较影响时不能直接比较,需要做标准化处理。
总之,数据的中心化处理相当于将坐标轴的原点移至样本中心,数据的标准化处理相当于是将不同指标化为同一尺度标准和数量级,方便比较。
特别地,在用多元线性回归方程描述某种经济现象时,由于自变量所用的单位大都不同,数据的大小差异也往往很大,这就不利于放在同一标准上进行比较。将样本数据作标准化处理后就消除了量纲不同和数量级的差异所带来的影响。