1. 引言
当Von Neumann和Morgenstern在1944年发表了《博弈论与经济行为》,一个关于策略选择行为的理论诞生了,博弈论成为独立的学科,成为人类经济行为的方法论基础 [1] 。博弈论学家Nash在20世纪50年代早期发表了著作,到70年代早期人们发现了纳什均衡的无穷威力,经济学家将纳什均衡的思想应用到诸多问题中。纳什均衡成为博弈论研究的核心,但是纳什均衡的精炼思想在解决一般博弈中的多重均衡问题时,对纳什均衡定义的集合大到难以描述。Maynard Smith的《演化与博弈论》将博弈论学家的目光从精炼的理性定义转到演化过程上来,解决均衡选择问题的新方法强调如下论断:所选择的均衡是达到均衡的均衡过程的函数 [2] 。Weibull总结了演化博弈,在《演化博弈论》中定义了演化稳定性标准,细致分析了演化博弈的复制子动态 [3] 。Sandholm在《Population Games and Evolutionary Dynamics》中从几何的角度分析了复制子动态模型,并阐述了模仿动态的几个模型 [4] 。
演化博弈理论为研究大群体中个体之间的相互影响提供了模型框架,是用微分方程组分析预测策略所占的比例随时间的变化来分析策略的稳定性,复制子动态是演化博弈中的标准动态,有大量的文献研究复制子动态。而在演化博弈理论中,与复制子动态中成功策略通过复制来扩展相比较,模仿动态描述的是成功策略通过模仿来扩展。与标准复制子动态一样,经典模仿动态假设个体模仿对手的策略的概率不仅与自身的收益函数有关,还与选择的对手的收益函数有关,并假设对手的收益函数越高,个体模仿他的策略的概率越高。
关于模仿动态的研究,文献 [5] 中,作者分析了两策略博弈中带有时滞的模仿动态,并得出不含时滞的内部平衡点是稳定的,而且存在一个临界值使得当时滞大于这个临界值时系统出现稳定的周期解,并在三策略的博弈模型中,用数值仿真显示了随着时滞的增加,解的幅度和周期都会增加。在文献 [6] 中,作者讨论了含双时滞的模仿动态的纳什均衡稳定性,得出多时滞的纳什均衡稳定性存在的充分条件,并针对结果做了数值仿真试验。
很多学者研究过基于绿色信贷的博弈模型,并得出一系列的结果。文献 [7] 应用一些博弈模型来探索商业银行发展绿色信贷商业的有效路径。文献 [8] 和 [9] 在演化博弈中加入金融监管部门的干预,分析监管行为对银行绿色信贷实施的影响。文献 [10] 建立了政府、银行和企业的三方演化博弈模型,得出结果表明政府的奖励和银行的绿色信贷优惠可以激励企业采用绿色供应链。
基于奖惩机制的绿色信贷的三方博弈在文献 [11] 中得到分析,作者从绿色信贷中三博弈方的收益入手,构建了博弈的复制子动态方程,得到博弈的三方演化动态方程,再在后面讨论了加入随机量的情况下分析了奖惩机制对各博弈方的策略选择行为的影响,得出的结论表明奖励的增加可以激励银行和企业实行绿色信贷政策,惩罚的增加可以遏制非绿色信贷行为。
以上绿色信贷的博弈分析中,所有的作者都只构建了标准的复制子动态方程,从遗传的角度分析绿色信贷的策略演化过程。我们的目的是从模仿的角度入手,基于绿色信贷中政府、银行和企业博弈方的收益与演化动态中的模仿机制,考虑各博弈方通过模仿来复制,构建三个博弈方的成比例模仿动态方程,分析各个平衡点在不同收益条件下的稳定性,并分析不同的奖惩力度对各博弈方策略选择动态的影响。
2. 绿色信贷的模仿动态模型
2.1. 模仿动态经典模型
与复制子动态相似,模仿动态也是假设个体有一定的机会改变自己的策略,也就是根据自己和对手的收益,按照一定的概率改变到对手的策略。以两策略对称博弈为例,假设支付矩阵为:
.
记x为使用策略A的概率,
为使用策略A的收益,则
为使用策略B的概率,
为使用策略B的收益,我们有:
根据模仿动态的定义,当个体使用策略A而他的对手使用策略B时,则他由策略A改变到策略B的概率为
,在前面的研究中,模仿概率
一般与当前状态支付收益
和
有关,也即是:
.
根据演化博弈中的模仿协议,我们可以得到博弈的模仿动态如下:
在现实生活中,博弈方都偏向于模仿收益高的策略,则取模仿协议为
,则博弈的模仿动态可变为:
2.2. 政府、银行和企业三方的收益参数假设
假设1:地方政府拥有促导绿色信贷和不促导绿色信贷两个策略。
首先,地方政府出于地方财政收入和绩效考核的考虑,没有对绿色信贷政策的监督,即不促导绿色信贷的发展,这种情况下的地方政府会收到企业的上税T,但会受到上级政府的惩罚
,
表示的是惩罚力度并且
,
表示的是最糟的时候的惩罚金额;
其次,地方政府为了响应国家绿色发展的号召,制定强有力的惩罚奖励机制,落实绿色信贷政策,即促导绿色信贷的发展,在这种情况下,地方政府要花费监督费用G来监督金融银行实行绿色信贷和生产企业实施绿色生产,如果企业实施绿色生产,地方政府给企业一定的缴税减免,缴税金额变为
,
表示减免比例且
;如果银行实行绿色信贷政策,地方政府给银行一定的资金补助
,
表示补贴的力度。
假设2:金融银行拥有实行绿色信贷和不实行绿色信贷两个策略。
为了追求营业利润,金融银行不实行绿色信贷政策,则银行可收到企业按正常利率贷款的贷款利润
,但如果地方政府促导绿色信贷的发展,银行会受到地方政府的惩罚
;
如果银行实行绿色信贷政策,就要对企业进行调查,审计的成本为D,获得的非绿色生产公司的贷款利润为
,获得的绿色生产公司的贷款利润为
(
),同时由于承担社会责任的良好印象,银行获得一定的绿色声誉收益R。
假设3:生产企业能采取绿色生产和非绿色生产两个策略。
为了追求商业利益和减少污染治理成本,企业不实施绿色生产,则会受到地方政府的惩罚
。企业如果实施绿色生产,则得到金融银行的优惠贷款利率,但要为企业的节能减排花费
。企业的营业收入为F,营业支出为
。
基于假设,可得出各博弈方在各个状态下的收益,见表1。

Table 1. The payoffs of government, bank and enterprise under each state
表1. 政府、银行和企业在各个状态下的收益
2.3. 政府、银行和企业的模仿动态模型分析
1) 政府的收益函数:
政府选择促导策略的收益:
政府选择不促导策略的收益:
则政府的模仿动态方程为:
当
时,状态x是模仿动态的稳定状态,也即是从这个状态开始系统不可能开始演化,由系统构成可以得出:
A) 当
时,有
,所以
是系统的一个稳定状态;
B) 当
时,有
,所以
是系统的一个稳定状态;
C) 当
时,也即是
时,
,在这种情况下,所有
的状态x都是稳定状态,也即是在这种情况下,系统不可能演化;
D) 当
时,会出现两个现象:若
,则
,所以x向
演化;若
,则
,所以x向
演化,见图1。
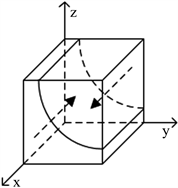
Figure 1. The phase diagram of government
图1. 博弈方政府的相位图
2) 银行的收益函数:
银行实行绿色信贷策略的收益为:
银行不实行绿色信贷策略的收益为:
则银行的模仿动态方程为:
当
时,状态y是模仿动态的稳定状态,也即是从这个状态开始系统不可能开始演化,由系统构成可以得出:
A) 当
时,有
,所以
是系统的一个稳定状态;
B) 当
时,有
,所以
是系统的一个稳定状态;
C) 当
时,也即是
时,
,在
这种情况下,所有的状态y都是稳定状态,也即是在这种情况下,系统不可能演化;
D) 当
时,会出现两个现象:若
,则
,所以y向
演化;若
,则
,所以y向
演化,见图2。
3) 企业的收益函数
企业实施绿色生产的收益为:
企业不实施绿色生产的收益为:
则企业的模仿动态方程为:
当
时,状态z是模仿动态的稳定状态,也即是从这个状态开始系统不可能开始演化,由系统构成可以得出:
A) 当
时,有
,所以
是系统的一个稳定状态;
B) 当
时,有
,所以
是系统的一个稳定状态;
C) 当
时,也即是
时,
,在这种情况下,
所有的状态z都是稳定状态,也即是在这种情况下,系统不可能演化;
D) 当
时,会出现两个现象:若
,则
,所以z向
演化;若
,则
,所以z向
演化,见图3。
联立政府、银行、企业的模仿动态方程可得:
(1)
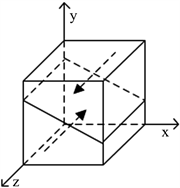
Figure 3. The phase diagram of enterprise
图3. 博弈方企业的相位图
3. 奖惩影响下的平衡点稳定性分析与数值仿真
3.1. 平衡点稳定性的分析与仿真
由相位图的动态方向可知,系统只会向边界与顶点演化,也即是系统不会向内部平衡点演化,所以下面只考虑顶点平衡点,系统的顶点平衡点为:
模仿动态的系统方程的Jacobian矩阵为
其中:
分别把各个平衡点代入Jacobian矩阵可求得矩阵的特征值,见表2。
Table 2. The eigenvalues of Jacobian matrix under each equilibrium
表2. 各平衡点处Jacobian矩阵的特征值
定理 [12] 若矩阵A的所有特征值均具有负实部,方程组
,
,
,
的零解是渐近稳定的。
现实中,各博弈方的收益都为正数,所有特征值的分母皆为各博弈方的收益之和,即所有分母都是正数,所以只需考虑特征值分子的符号就可得下列结论:
结论1:当
,
,
时,平衡点
渐近稳定,也即是平衡点
是演化稳定的,见图4。
结论2:当
,
,
时,平衡点
渐近稳定,也即是平衡点
是演化稳定的,见图5。
结论3:当
,
,
时,平衡点
渐近稳定,也即是平衡点
是演化稳定的,见图6。
结论4:当
,
,
时,平衡点
渐近稳定,也即是平衡点
是演化稳定的,见图7。
结论5:当
,
,
时,平衡点
渐近稳定,也即是平衡点
是演化稳定的,见图8。
结论6:当
,
,
时,平衡点
渐近稳定,也即是平衡点
是演化稳定的,见图9。
结论7:当
,
,
时,平衡点
渐近稳定,也即是平衡点
是演化稳定的,见图10。
结论8:当
,
,
时,平衡点
渐近稳定,也即是平衡点
是演化稳定的,见图11。
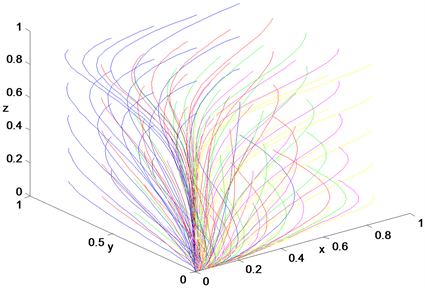
Figure 4. System evolves to (0, 0, 0)
图4. 系统向(0, 0, 0)演化
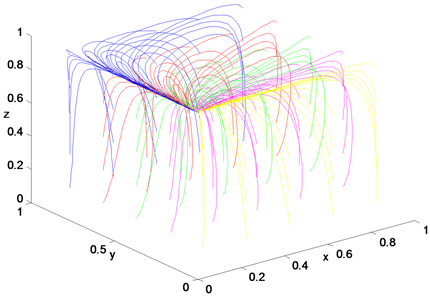
Figure5. System evolves to (0, 0, 1)
图5. 系统向(0, 0, 1)演化
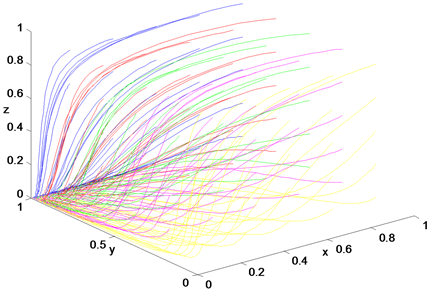
Figure 6. System evolves to (0, 1, 0)
图6. 系统向(0, 1, 0)演化

Figure 7. System evolves to (0, 1, 1)
图7. 系统向(0, 1, 1)演化
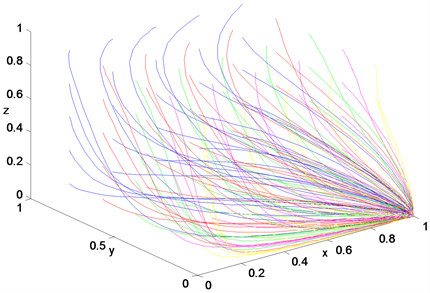
Figure 8. System evolves to (1, 0, 0)
图8. 系统向(1, 0, 0)演化
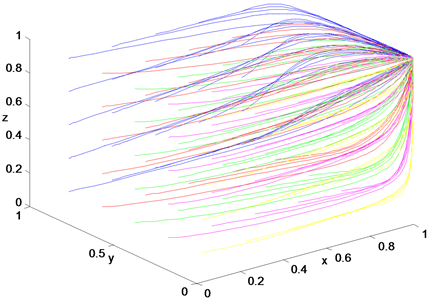
Figure 9. System evolves to (1, 0, 1)
图9. 系统向(1, 0, 1)演化
3.2. 奖惩力度对平衡点稳定性的影响
为分析不同的惩罚力度对各个博弈方策略选择的影响,
,
,
,
,
,
,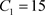 ,
,
,
,
,
,
,
,
。设置不同的
值,应用仿真分析各博弈方在不同惩罚力度下的动态行为。
,
,
,
,
,
,
,
,
。设置不同的
值,应用仿真分析各博弈方在不同惩罚力度下的动态行为。
当对各博弈方的惩罚力度非常小时,使用绿色信贷产生的各方面的投资花费远大于被惩罚的资金,各博弈方为了使自己的利益最大化,会偏向于使用非绿色信贷手段,导致系统会收敛于
这个点,也即是政府不督促绿色信贷政策的实施、银行不执行绿色信贷的策略以及企业不实施绿色生产,见图12。
当对各博弈方的惩罚力度非常大时,使用非绿色信贷手段而获得的收益不足以抵扣惩罚,各博弈方为了不得不偿失,会偏向于实行绿色信贷政策,以免被惩罚高额罚金,这样系统会收敛到
这个点,也即是政府督促绿色信贷政策的实施、银行执行绿色信贷的策略以及企业绿色生产,见图13。
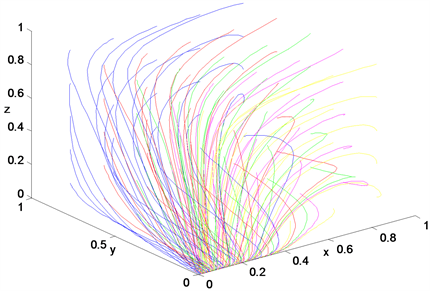
Figure 12. The dynamic for punishment intensity is 0.1
图12. 惩罚力度为0.1时的动态图

Figure 13. The dynamic for punishment intensity is 0.8
图13. 惩罚力度为0.8时的动态图
当对各博弈方的惩罚力度不高也不低时,对各博弈方的罚金和非绿色信贷所获得的额外金额基本相等,这时,各博弈方选择绿色信贷手段和非绿色信贷手段的收益基本相同,导致系统处于混沌状态。
不同惩罚力度对各博弈方策略选择的影响:
设置不同的惩罚系数,应用仿真试验讨论不同的奖励力度对政府、银行和企业策略选择的影响。从图中可以看到,当
很小时,
的值都逐渐趋向于0,当
一定大时,
的值逐渐趋向于1,并且
越大,
向1趋近的速度越快,见图14~16。
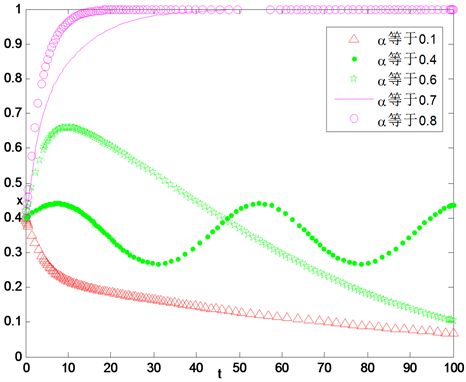
Figure 14. The influence of difference punishment intensity for government’s strategy selection
图14. 不同惩罚系数对政府策略选择影响
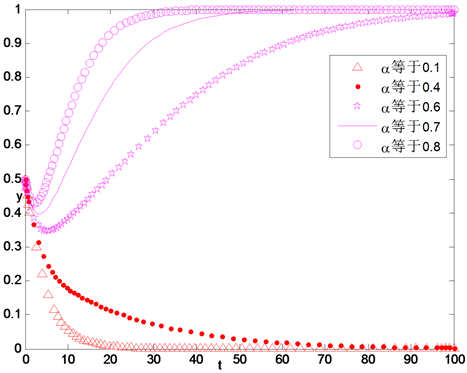
Figure 15. The influence of difference punishment intensity for bank’s strategy selection
图15. 不同惩罚系数对银行策略选择影响
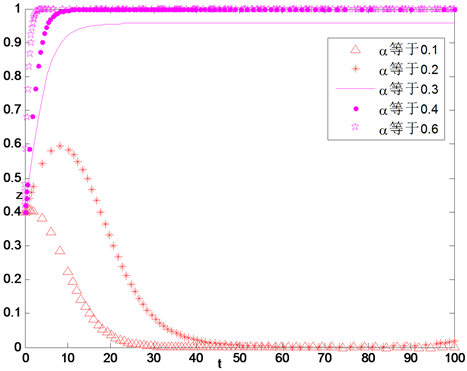
Figure 16. The influence of difference punishment intensity for enterprise’s strategy selection
图16. 不同惩罚系数对企业策略选择影响
为分析不同奖励力度对各博弈方策略选择的影响,由于奖励制度是由地方政府设置并实施的,所以地方政府的策略选择始终是实施绿色信贷政策,也即是地方政府选择督促绿色信贷的概率是1。设置不同的
值,应用仿真模拟系统动态,可得出下列结论:
当奖励力度
值很小时,政府给与企业的奖励不足以解决企业为绿色生产而产生的额外花费,企业为使自己利益最大化,会选择非绿色生产策略。企业的非绿色生产策略的选择会导致银行选择非绿色信贷策略,从而导致系统向
演化,见图17。
当奖励力度
值很大时,政府给与企业的奖励不仅解决了企业为绿色生产而产生的额外花费,还为企业带来一定的收益,企业为使自己利益最大化,会选择绿色生产策略。在企业选择绿色生产策略的情况下:若地方政府给与银行的补贴力度很小,不足以解决银行为实行绿色信贷政策而产生的优惠利率和审计费用,银行选择非绿色信贷策略,从而导致系统向
演化,见图18;若地方政府给与银行的补贴力度很大,不仅解决银行为实行绿色信贷政策而产生的优惠利率和审计费用,还为银行带来一定收益,银行选择绿色信贷策略,从而导致系统向
演化,见图19。
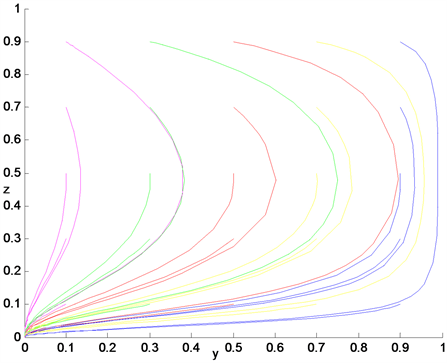
Figure 17. Dynamic diagram of the evolution of a system with little award intensity
图17. 奖励力度很小时系统的演化动态图
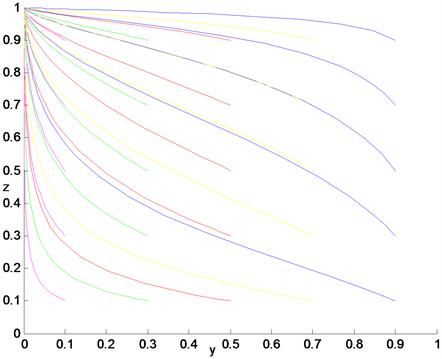
Figure 18. Dynamic diagram of system with large β but little γ
图18. β大而γ小时系统动态图
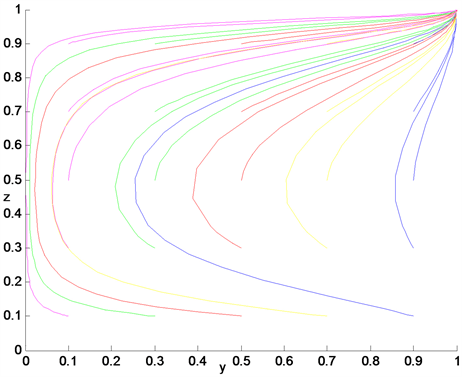
Figure 19. Dynamic diagram of system with large β and large γ
图19. β与γ都大时系统动态图
下面分析不同奖惩力度对企业和银行策略选择的影响:
设置不同的补贴参数,应用仿真试验讨论不同的补贴力度对银行策略选择的影响。从图中可以看到,当
很小时,y的值逐渐趋向于0,当
一定大时,y的值逐渐趋向于1,并且
越大,y向1趋近的速度越快,见图20。
设置不同的奖励系数,应用仿真试验讨论不同的奖励力度对企业策略选择的影响。从图中可以看到,当
很小时,z的值逐渐趋向于0,当
一定大时,z的值逐渐趋向于1,并且
越大,z向1趋近的速度越快,见图21。

Figure 20. The influence of different γ for bank’s strategy selection
图20. 不同γ值对银行策略选择的影响
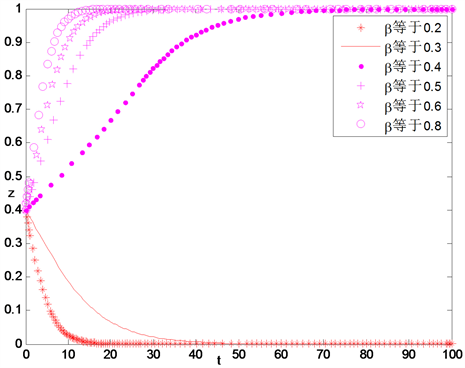
Figure 21. The influence of different β for enterprise’s strategy selection
图21. 不同β值对企业策略选择的影响
4. 总结
在绿色信贷交易行为背景下,构建了基于奖惩机制的政府、银行和企业三方演化博弈的模仿动态方程,分析了各平衡点在不同条件下的稳定性情况,用数值仿真验证了各个平衡点在一定的收益条件下是演化稳定的;探索了不同的奖惩力度对各博弈方策略选择的影响,得出奖惩力度对政府、银行和企业的策略选择有着很大的影响,奖惩力度很小时,政府、银行和企业偏向选择非绿色信贷策略;奖惩力度增大,政府、银行和企业从选择非绿色行为策略转变到选择绿色行为策略,并且奖惩力度越大,政府、银行和企业选择绿色行为策略的意愿更大。