1. 引言
智能交通这一概念的产生,是用于解决各种由于城市交通流量增加所带来的问题。根据《交通强国建设纲要》中的规划目标,到21世纪中叶,中国将全面建成交通强国。中国智能交通市场将继续稳定增长。智能交通在快递物流方面更是存在广泛的应用。目前,上海市传统物流行业发展迅速,但是智能化程度并不高。在高峰时期,各快递公司常常无法准时送达顾客的快递,出现运输货车超载和仓库存储超量的情况 [1] ,部分地区物流供需关系的不平衡已经严重影响到市民的日常生活。
我国对于快递物流站点选址的相关研究从九十年代初期开始,距今已有三十多年的历史。随着全球互联网技术的发展与普及,电商行业不断壮大,国内的物流业也迎来了飞速的发展。如何解决快递物流中心的选址问题至关重要,这一问题是运筹学范畴内的典型实际问题,通常需要同时控制时间成本和费用成本最小化。即一方面需要保证影响便捷程度的距离因素和取件效率因素,另一方面考虑到影响所选地点盈利程度的运输、建设、储存与人流量等问题。该选址思想可以应用到诸如仓库选址、大型公共设施选址等多方面实际问题,应用范围非常的广泛。因此,研究物流中心设施选址问题的模型和求解该模型的算法显得格外重要。
由于城市大型设施选址问题需要考虑的实际因素往往很多,收集到的变量数量也非常大。因此,通常情况下问题的求解方案难以通过已有算法在很短的计算时间内得出,所得到的某一解决方案也难以保证其是否接近最优解。所以,如何构建能在有限时间内计算出近似最优解的优化算法成为了国内外学者的研究重点之一。已有的研究通常把选址点的状态与各类成本作为影响因素构建设施选址模型进行求解。关菲 [2] 等人在综合考虑模糊环境下的各个影响因素条件下,构建一个模糊多目标物流配送选址模型并基于粒子群优化算法进行求解。张富 [3] 则结合选址特点与疏散要求建立了一个多目标规划选址模型,并通过实际的案例验证该模型与算法的可行性。而通过粒子群算法、克隆选址算法、遗传算法等多种方法进行求解同样快捷高效。例如,马一丁等 [4] 使用遗传算法对基站选址模型进行优化求解。Su等 [5] 通过改进后的蚁群优化算法对多目标优化模型进行求解,效果同样十分显著。万兴玉 [6] 则为了更加准确有效的求解模型,将排队理论和遗传模拟退火算法结合处理。
在快递物流行业智能化的趋势下,关于配送中心选址这一问题的求解方式有很多,但大都没有得到广泛认可。基于此,本文设计了在K-means聚类分析后构建0-1规划模型实现智能化选址的方案。
本文的具体工作内容如下:1) 在采用手肘法来得到K的最优值后,利用K-means聚类算法进行聚类,将初始候选点划分为K类以备进一步的选择;2) 将快递物流选址问题进一步转化为选择问题,对于可行的选址点通过更接近实际情况的0-1规划进行建模分析,即根据物流配送环节的各个影响因素和约束条件,建立了快递物流选址的0-1规划数学模型,求解模型得到最优位置坐标;3) 针对上海市杨浦区某快递物流公司的具体情况进行实例分析,并利用重心法对比两模型的求解效果,验证了整数规划结果的可行性及有效性,为物流企业的站点选取提供了理论的科学依据。
2. 模型建立
在智能交通场景下,一个区域内的物流规划被分为三个部分,区域总配送中心、物流中心、居民家中。这三个节点层层递进,由区域总配送中心将货物发放到物流中心,再由物流中心将货物发放到各个街道与居民的家中。同样,收取货物的途径也是按照这三个节点反向递进。对于一个城市的交通规划来说,其体系与网络布局都过于复杂,而位于中间环节的任意一个物流中心可以辐射至其一定范围内的所有居民。因此,为降低位置选取模型的复杂度,本文先采用聚类分析对不同区域进行划分,从而缩小规划范围,确定物流中心的大致位置。
继续深入分析可知,物流中心的位置往往受不同区域居民的人口密度、货物流量与运输成本等因素的影响,因此,本文使用K-means聚类算法分类后,根据这些影响因素进一步建立相关的0-1规划模型并进行求解。
2.1. K-means聚类模型
聚类是数据分析方面重要的部分,它能够将大量的、杂乱的数据进行整理,最终以类簇的形式将多个数据囊括其中,并提取出各个类簇的特征。依照方式的不同,聚类算法可以被分为层次聚类、划分型聚类、网格与密度的聚类、ACODF聚类法等等 [7] 。层次聚类法将各项数据在进行反复的分拆与聚合后生成一个层状的结构,完成聚类的要求。划分式聚类法则需要事先给出一个类别,然后根据指定规则,反复计算与迭代,最终得到一个最好的聚类效果 [8] 。
在此之中,K-means聚类算法是一个非常经典的划分式聚类法,其思路是先给定一个数据集的一组初始质心作为类簇的中心,然后通过一定的聚类规则,来判断聚类结果是否为最优解,从而决定是否通过改进质心来达到改进聚类的效果。在具体操作的过程中,K-means聚类法首先需要选择的初始质心数即为K,一般根据需求和经验随机指定。为了既能达到最好的聚类效果,又不浪费资源和建设成本,本文选择利用手肘法来得到类簇数量K的最优值 [9] 。即选择形如一条手臂的肘处的拐点处作为问题的最优解。
首先,在指定的区域内选取n条带有经纬度的街道,作为K-means聚类的n个初始质心。接着以区域中每条街道作为其余的样本点,将其到n个质心的欧拉距离视为度量标准进行聚类,样本点到哪个质心距离最近,就将其归为该质心所代表的类簇中。并将K与不同误差平方和SSE做一折线走势图,利用手肘法找出其拐点的位置即得出K值。随后,通过求解同一类簇Xi中每一样本点的均值来得到新的质心。最终,当新的质心与前一个质心结果一致时,停止迭代计算。
2.2. 0-1规划模型
通过K-means聚类算法已得到模型能够被分为K个类簇,并且相应地计算出了K个质心位置的结论。因此,进一步建模的主要思路应该是将物流中心的选址问题再进一步地转化为选择问题。对于可行的选址点,选址用更贴近实际情况的0-1规划进行建模分析,根据所给出的约束条件,删除部分不理想的可行解,考虑剩余解,最终检测得到最优解。
对于K个质心,现给出K个约束条件,使得每个物流中心的货物运输距离不超过2500米。所建模型的思路为在运输范围内一定包含有一个快递物流中心的情况下,如何能够建设尽可能少的物流中心。也就是说在满足运输条件的前提下,探求一种能够保证成本最少的物流中心布局方案。
0-1规划的基本思路如下:
首先引入参数
权重值和
矩阵,其中
代表该备选物流中心的重要程度,用人口数量占比的倒数归一化表示,即对于人口占比大的可行解赋予较小的系数;
则如式(1)所示。
(1)
规定松弛变量
为:
(2)
建立物流中心的选址模型:
(3)
构造模型的约束条件为:
(4)
3. 实例分析
为验证0-1规划模型在物流中心选址中的有效性和实用性,本章在对上海市杨浦区快递驿站和配送成本进行实地调查后,利用上述模型针对上海市杨浦区计算得出快递配送中心选址结果,再将所得结果与重心法结果进行对比。
3.1. 整数规划结果
选取杨浦区为研究区域,该区域共包括12个街道。本文利用高德地图得到杨浦区各街道经纬坐标,根据《中国统计年鉴》整理得到各街道人口数,并将2021年杨浦区各街道快递流量的估算值作为各街道的货物流量,由于现实情况中调查的单家快递运输单价一致,故规定运输成本为1。统计结果见表1。

Table 1. Population, latitude and longitude coordinates and goods flow for each street
表1. 各街道的人口数、经纬坐标与货物流量
本节首先采用2.1中的K-means聚类法将所调查得到的驿站坐标进行聚类,采用手肘法根据所得折线图将12个街道分为2个类别,通过Python代码输出其类簇的经纬度坐标见图1。
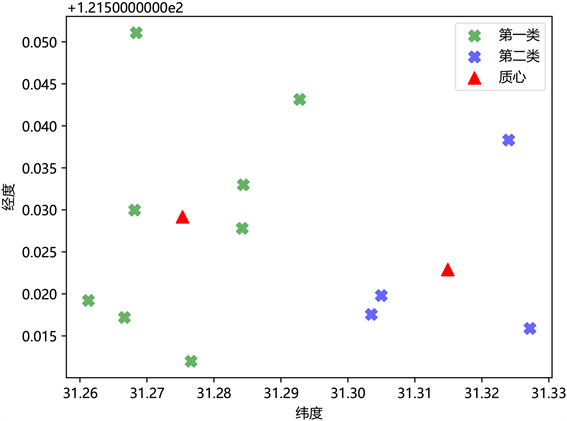
Figure 1. K-means clustering results diagram
图1. K-means聚类结果示意图
由图可知,12个街道在距离上被分为两类,第一类:平凉路街道、江浦路街道、大桥街道、定海路街道、四平路街道、控江路街道、延吉新村街道、长白新村街道。第二类:五角场镇、五角场街道、殷行街道、新江湾城街道
由物流的收发规律可知,各个街道的居民人数会影响到快递货物的收发量,从而影响快递物流中心地址的选取。因此,在考虑了各个街道居民数量后,对目标函数的松弛变量赋予权重。将人口占比的倒数归一化后得到权重值,此值代表了选址点的重要程度。所得结果见表2:
Table 2. Weight values of slack variables
表2. 松弛变量的权重
在聚类后进一步利用0-1整数规划法。为满足每2500米范围内都包含至少一个物流中心,且此时物流中心建设数量最少。现建立一个
的矩阵,其各元素满足的规则如下:
假如各物流中心之间最远大圆距离小于或等于2500米,则该处值为1;相应的,假如各物流中心之间最远大圆距离大于2500米,则该处的值为0。然后将各个物流中心是否建立与R矩阵进行矩阵乘法,约束其结果需要大于等于1,这样能够避免在距离大于2500米(
),但却选择了不建站(
)的决策。其中,约束条件中对应距离的R值如式(5)所示:
(5)
即可保证在每2500米范围内都包含至少一个物流中心,且此时物流中心建设数量最少。在实际调查数据的基础上,利用2.2中的0-1整数规划模型,使用Python进行求解,输出结果见表3:
可见,在满足约束条件下,杨浦区的物流中心最优建设地址为:大桥街道,控江路街道,五角场镇,殷行街道。
3.2. 重心法结果
重心法是一种模拟方法,它在设定所求物流系统的平面所属范围后引入需求点和资源点,系统中物体的重量表示为需求量和资源量,求得该系统中心即求得所求网点 [10] 。该种方法从设施之间的距离和运输货物量入手,经常用来选择中间仓库或经销仓库,即求出该地区实际的货物流量的重心所在位置,且此时物流成本最低,同样满足本文所需目标。
因此,以货物流量为标准寻找重心,利用Python程序经过10次迭代后得到两个类簇中重心的经纬度坐标,结果如图2和图3所示:
且由输出结果可知,第一个类别的重心坐标为(31.2735596, 121.527976),第二个类别的重心坐标为(31.305001, 121.519796),由此即找到了两个类中到各个街道物流成本最低的经纬位置。
3.3. 算法结果对比
上述内容分别采用了0-1整数规划法和重心法得出了杨浦区物流选址情况。本小节现对重心法和0-1整数规划法所得的选址情况进行对比,将两种方法所得的选址放入同一坐标系进行位置对比,如图4所示。
由图4可知,0-1规划模型所得的结果在同样保证由物流配送中心至各街道的成本最低的基础上,围绕着重心法所得的街道经纬度坐标均匀分布。这说明所构建模型得到的结果既能够满足物流中心的运输成本最低,也能保证达到一定的配送速度,同时也说明了这一整数规划模型的可行性与优越性。
4. 结论
综上所述,本文采用先聚类后进行整数规划的方法构建模型,且在整数规划中对各个松弛变量按照居民人口数量进行加权,所得模型在满足日常货物流量的基础上也能保证物流成本低廉,同时具有一定的配送时效。如此,模型的创新性与可操作性都得到了有力的证明,对快速构建不同情况下的选址方案具有一定的参考价值和指导意义。
但是,由于物流中心位置所受影响的复杂性与多样性,以及本文调查所得数据不精确等问题,例如只调查了各个街道的经纬坐标,仅考虑了单家快递公司的情况等,导致本文的结果仍然并非最优解而是次优解。因此,本文所构建的模型仍有较大的提升空间,相关的选址与规划问题仍有待学者们进一步的发掘与思考。
基金项目
感谢国家自然科学基金(12201407)、上海市青年教师培养资助计划(ZZ202203095)和上海理工大学创新创业训练计划项目(SH2022218)的资助!