1. 引言
1.1. 研究背景及意义
随着社会发展,人们生活水平提高,人们对于生活质量的要求也越来越高。购物便成为了人们满足这一需求的重要途径。沃尔玛百货有限公司是一家美国的世界性连锁企业,连续七年位居美国《财富》杂志首位,同时,也是世界上最大的私人雇主,在世界范围内拥有超过两百万的员工,是世界上最大的零售商。截至2021年,沃尔玛在全球27个国家开设了超过10,000家商场,而且随着该公司向新兴市场扩张,这一数字很可能会增加。这些门店的净销售额超过5000亿美元,而沃尔玛的毛利率一直稳定在25%左右,这意味着沃尔玛经过几十年的发展,仍然具有较强的竞争力,在全球市场中仍然具有较大影响力。
在文献 [1] - [15] 中展示了沃尔玛在世界范围内能够取得这样的成功的关键,在很大程度上取决于尖端科技和物流系统进行巧妙搭配,使用计算机进行管理和全球领先的卫星定位系统控制公司物流,提高配送效率。文献 [15] [16] [17] 给出了沃尔玛一直采用最先进的系统进行运输安排,通过电脑系统和配送中心相互配合,为沃尔玛节省了相当多的成本,以速度和质量赢得用户的满意和忠诚。
这样大的一个百货公司要为各个门店合理配送商品并不容易,如果给销量差的门店配送较多的商品,会导致货物囤积,产生浪费;而给销量好的门店配送较少的商品,就会影响门店收益,甚至给消费者带来较差的消费体验,每天影响销量的因素有很多,如果能够预测销售额和准确的需求,将会很好地为沃尔玛节约成本和提高收益,为更多消费者带来更好的用户体验。
1.2. 国内外研究现状
沃尔玛是最早开始投资和部署大数据应用的零售商之一,在全球许多地区设立了沃尔玛大数据实验室,从中挖掘出消费者的消费习惯,商品之间的相关性,建立起消费者与商品之间便捷的联系,这为沃尔玛带来了巨大的利润,同时,也为消费者提供了更好的购物体验,参见文献 [18] [19] 。在20世纪90年代,沃尔玛超市管理人员对销售数据进行数据分析时就发现“啤酒”与“尿布”这两个毫无关系的商品会经常出现在同一个购物篮中,经过调查发现,这种现象发生在年轻父亲身上,由此,沃尔玛的超市管理人员们将“尿片”和“啤酒”经常性放在一起出售,大大提高了两者的销量,参见文献 [20] [21] 。对销售商品进行数据分析,将许多孤立的数据集成起来,能够实现智慧营销,帮助管理者更好地制定决策。在许多情况下,简单的数据分析只能提取到少量有价值的信息,更多有价值的信息需要使用数据挖掘技术,通过算法获取。实验研究表明,数据挖掘技术能够帮助沃尔玛挖掘更多客户信息,辅助日常管理,提高市场竞争力。
本文将使用数据分析方法对沃尔玛部分地区数据进行分析,这有助于沃尔玛百货公司更好地执行商业决策,对沃尔玛的发展具有十分重要的意义。
1.3. 研究思路
本研究主要分为三个部分:
第一部分:对数据进行预处理。本文所采用的原始数据未经过处理,数据中不乏存在缺失值、异常值等情况,需要在使用前通过Python进行填充和修改之后才能进行分析和预测。
第二部分:数据分析过程。经过预处理过后的数据就可以直接使用了,通过给定的数据分析不同指标对销售额的影响,分析不同年月季度和地区的销售额,节假日对销售的正负面影响。
第三部分:建模过程。本文将采用两种模型对销售额进行预测。为了保证数据研究的科学性和合理性,将数据分为训练集和测试集。使用训练数据建立模型,测试数据验证模型。通过实际结果和模型预测结果进行比较,验证模型的性能。
2. 模型简介
2.1. 多元线性回归模型
多元线性回归模型由多个解释变量预测或估计因变量,其非随机结构表达式如下:
其中,
为k个解释变量,
为线性回归模型的回归系数,其
。在正太分布假定下,如果
是可逆的,则参数β的最小二乘估计为:
从而可以得到因变量y的估计值:
残差
,则随机误差方差δ2的最小二乘估计为:
这样就可以求解出多元线性回归模型的参数。
2.2. 深度神经网络模型
深度神经网络(DNN)是一种多层无监督神经网络,它将上一层的输出特征作为下一层的输入,经过逐层映射,最终将原始数据特征映射到另一个特征空间,经过这样的映射之后使得特征具有更好的表达。本文将构建一个具有两个隐藏层,单个输出神经元的深度神经网络用于销售额预测,其结构如图1所示。
网络中每一层到下一层之间的特征映射,通过如下线性关系得到中间结果:
其中,wij是下一层中第j个中间特征的第i个线性关系系数, 为偏置项。
然后再接一个神经元激活函数:
做非线性变换,就可以得到下一层神经元的输入。深度神经网络经过多个这样的特征映射可以实现对高度复杂函数的拟合,从而达到预测的目的。
为了提高深度神经网络的参数更新的效率,本文将采用Adam优化算法进行参数更新。Adam优化算法结合了AdaGrad和RMSProp算法的最优性能,在深度神经网络训练过程中具有非常好的表现。
3. 数据分析
3.1. 数据来源及解释
本文所使用的沃尔玛商店数据来自于Kaggle竞赛网站,该数据本就是用于零售数据分析的,是沃尔玛在不同地区的门店的历史销售数据汇总而来,拥有6000多条数据,数据中包含45家门店的相关信息,从2010年到2012年中部分天数的销售额情况、节假日信息、对应华氏温度、燃料价格、居民消费指数CPI以及失业指数等。
3.2. 销售数据分析
在大多数情况下获取的数据都是不完整的,需要人为将获取到的数据的空值部分做预处理,本文所使用的沃尔玛数据也不例外,在此使用均值填充的方式来填补空值。使用Python经过预处理后,获取到数据的一些描述性统计信息,如下表1所示。

Table 1. Descriptive statistical analysis
表1. 描述性统计分析
从给出的数据描述来看,所使用的数据具有八个属性,6435条记录,提供了45个门店的销售额、节假日、温度、油价、居民消费指数、失业率等相关信息。
在所提供的数据中,包含2010年、2011年以及2012年的销售信息,下面分析45家门店三年的销售额情况,绘制出如下图2的柱状图。
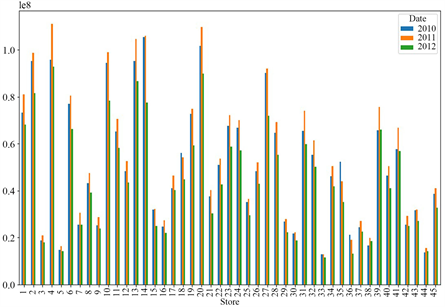
Figure 2. Bar chart of sales statistics of each store
图2. 各门店销售统计数据柱状图
所绘制的柱状图反映出在所提供的45家门店中普遍2011年的销量最好,2010年次之,2012年销量最差。为了能看出这三年45家门店销售额的分布情况,将三年的销售额堆叠起来得到如下图3的柱状图。

Figure 3. Stacked bar chart of sales statistics of each store
图3. 各门店销售统计数据堆叠柱状图
从图中可以看出,第20家门店的销售额略高于其他门店,与第4家门店的差距较小,第33家门店的销售额最少。下面再分析45家门店三年销售额的标准差,绘制出如下图4的折线图。
从图中可以看出,第14家门店的标准差最大,第33家门店最小,说明第14家门店的销售额变化较大,第33家门店由于本身销售额较小,因此销售额变化不太大。
前面纵向比较45个门店2010年、2011年及2012年的销售额情况,下面横向比较2010年、2011年及2012年不同月份的销售额情况,绘制出三年各个月45家门店销售的折线图,如图5、图6、图7所示。
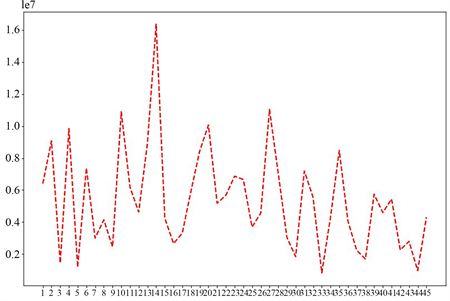
Figure 4. Line chart of sales statistics of each store
图4. 各门店销售统计数据折线图
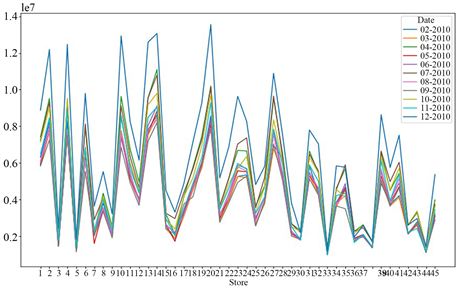
Figure 5. Line chart of monthly sales data of each store in the first year
图5. 各家门店第一年各月销售数据折线图
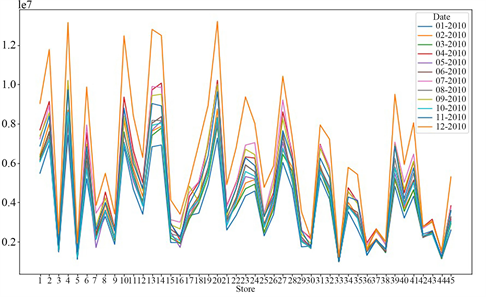
Figure 6. Line chart of monthly sales data of each store in the second year
图6. 各家门店第二年各月销售数据折线图
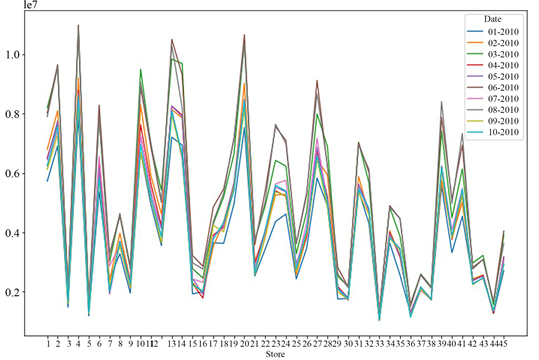
Figure 7. Line chart of monthly sales data of each store in the third year
图7. 各家门店第三年各月销售数据折线图
从折线图中可以看出,45家门店在2010年和2011年2月中的销售额普遍较高,2012年较复杂,没有明显的区分。从折线图的走势来看,2010年、2011年及2012年各门店销售额的情况大致相同,没有太大变化。下面给出三年中45家门店各个月的销售总额,得到如下图8的柱状图。
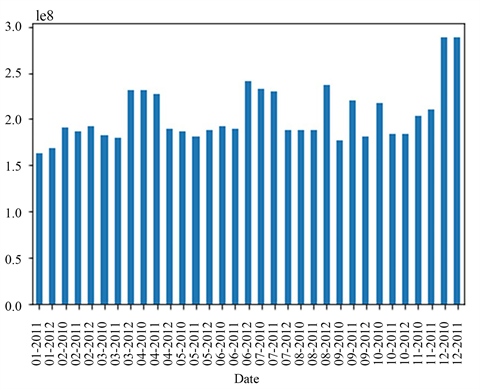
Figure 8. Bar chart of monthly sales data of each store for three years
图8. 各门店三年各月销售数据柱状图
该统计柱状图表明,在十二月时的销售额会比较好,其他月份虽然偶尔销售额会有所增加,但基本比较稳定。将2010年和2011年各月的销售额数据以季度为单位,得到如下两年中45家门店各季度的柱状图分布,如下图9所示。
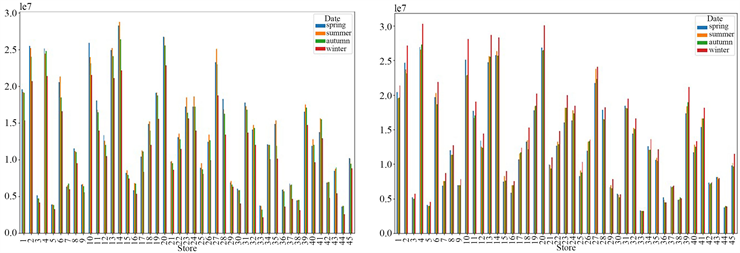
Figure 9. Bar chart of quarterly sales data of each store for three years in 2010 and 2011
图9. 2010年和2011年各门店三年各季度销售数据柱状图
从柱状图中可以看出,在2010年冬季的销售额最差,对于其他三个季节,不同门店的销售额各不相同,没有明显的规律,但普遍是春夏季的销售额较好。但在2011年冬季的销售额普遍最好,其他三个季节没有特别的规律。
所给定的沃尔玛数据提供了节假日标记信息,数据中1表示对应的节假日,0表示一般工作日。节假日包括劳动节、感恩节、圣诞节等,为了了解节日对销售额产生的影响,对节假日销售额数据进行统计分析,将一般工作日的平均销售额作为正面和负面的影响指标,得到节假日销售额高于所有商店在非节假日期间的平均销售额的统计图,如图10所示。
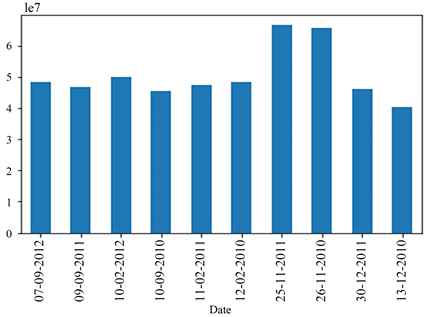
Figure 10. Statistical chart of holiday sales are higher than the average sales of all stores during non-holiday periods
图10. 节假日销售额高于所有商店在非节假日期间的平均销售额的统计图
该柱状图统计了在这些节假日中,销售额高于一般工作日的销售额,节假日在沃尔玛销售中产生了有益的影响,提高了收益。
3.3. 本章小结
本章介绍了所使用的沃尔玛零售数据来源,介绍了数据的基本信息。通过对数据进行纵向分析发现,45家门店在2011年的销售额最好,2012年销售额最差。其中,第20家门店销售额最高,第33家门店销售额最少且变化最小,第14家门店的销售额变化最大;横向比较发现,其中,45家门店在2010年和2011年2月中的销售额普遍较高,三年各门店销售额的情况大致相同,没有太大变化;在对三年各月份的统计分析中,12月的销售额最好,在2010年冬季的销售额最差,2011年冬季的销售额普遍最好;最后,统计发现,在2010-02-12、2010-09-10、2010-11-26、2010-12-31、2011-02-11、2011-09-09、2011-11-25、2011-12-30、2012-02-10、2012-09-07这些节假日的销售额高于非节假日,对沃尔玛销售有帮助。因此,需要为各门店合理分配商品,为销售业绩比较好的门店派送充足商品,在12月之前需要囤积足够多的商品。
4. 数据销售预测
所提供的沃尔玛数据包含温度、燃油价、居民消费指数、失业率等属性,在使用这些属性预测沃尔玛销售额之前,需要考虑属性之间的相关性,找到解释变量之间具有较强关联的特征,能够观察属性之间存在的线性关系,有利于进行数据分析。在属性特征非常多的情况下,利用属性之间的相关关系往往可以达到变量选择的目的,减少多重共线问题,有利于提高模型稳健性,从而提升模型性能。
本文分析了数据中温度、燃油价、居民消费指数、失业率四个解释变量的相关性,得到如下图11所示的热力图。
从上面得到的热力图可以看出,燃油价和居民消费指数的相关性达到0.755,具有较强的正相关性,另一方面,居民消费指数和失业率具有较强的负相关性,达到−0.813,从而,燃油价和失业率都与居民消费指数具有较强的线性关系,从图中也能看出燃油价和失业率仍然有着−0.514的负相关关系;以上从沃尔玛数据得到的结果说明,燃油价的变动对居民消费指数影响较大,从而间接影响失业率,燃油价格升高在一定程度上会促进居民消费指数的上升,降低失业率,而燃油价格下降具有相反的变化趋势。
4.1. 数据预处理
在进行建模之前,需要将沃尔玛数据进行标准化处理,使得模型的输入数据控制在合理范围之内,这样可以消除量纲对数据预测的影响,使模型更稳定。
标准化处理的函数:
其中,μ表示样本xi的均值,δ表示样本xi的方差。
在此,本文使用2012年的数据来训练模型,经过标准化处理的序列为如下表2所示。
Table 2. Normalized variable value
表2. 标准化变量数值
4.2. 基于多元线性回归模型预测拟合
本节将使用温度、燃油价、居民消费指数以及失业率等特征,建立多元线性回归模型预测销售额。先将原始数据划分为训练集和测试集,使测试集占所有数据的20%。使用Python的sklearn模块中的Linear Regression方法,构建了一个多元线性回归模型,得到温度、燃油价、居民消费指数以及失业率等特征的系数为−0.2144、−0.0089、0.349、0.1448,由此,可以看出燃油价格对销售额的影响占比最小,居民消费指数对销售额的影响最大。将在训练集上训练好后的模型运用到测试集上,得到预测值及相关信息,如下表3所示。
Table 3. Comparison of actual values and predicted values
表3. 实际值与预测值比较
4.3. 构建沃尔玛数据深度神经网络模型
深度神经网络模型被广泛应用于数据预测,本文将深度神经网络模型运用于沃尔玛数据的预测分析中,搭建一个具有两个隐藏层的神经网络。第一层隐藏层具有10个神经元,后跟一个ReLU激活函数;第二层有5个神经元,后跟一个ReLU激活函数,最后是一个全连接层,其结构如下图12所示。
在模型训练之前,将数据划分成训练集、验证集和测试集,训练集和验证集用于模型训练过程中,将训练的批次大小设置为120,训练50轮次,学习率为0.001,训练得到该模型在训练集和验证集上损失函数的变化曲线,如下图13所示。
这样就构建了一个深度神经网络模型,该模型可以用来预测其他门店的销售额。
4.4. 本章小结
本节对解释变量进行相关性分析发现,燃油价的变动对居民消费指数影响较大,从而间接影响失业率,燃油价格升高在一定程度上会促进居民消费指数的上升,降低失业率,而燃油价格下降具有相反的变化趋势。然后,对数据进行标准化处理,使用多元线性回归模型在测试集上预测了销售额数据,并展示了部分预测结果及相关信息。在本节最后,搭建了一个两层的深度神经网络模型并使用沃尔玛数据进行训练,该模型可用于预测其他门店的销售额。
5. 结论与建议
本文对从Kaggle竞赛网站上获取的沃尔玛数据进行数据分析并建立预测模型,得到如下结论:
1) 对数据中的45家门店进行纵向和横向分析,得出不同地区不同门店销售情况存在差异,其中,各门店在2月和12月的销售情况最好,建议这两个月前可以囤积一定量的货物;在2010-02-12、2010-09-10、2010-11-26、2010-12-31、2011-02-11、2011-09-09、2011-11-25、2011-12-30、2012-02-10、2012-09-07这些节假日的销售额普遍高于非节假日,也需要充分准备商品,为顾客提供满意的服务。
2) 在对响应变量温度、燃油价、居民消费指数、失业率等属性进行相关性分析中发现,燃油价格与居民消费指数呈正相关,失业率呈负相关;使用多元线性回归模型在测试集上预测了销售额数据,得出燃油价格对销售额的影响占比最小,居民消费指数对销售额的影响最大。
根据以上数据分析和建模的结果,为了帮助沃尔玛增加销售额,提高收益率,在此提出如下建议:
在日常销售过程中,根据以上分析结果显示,在2月和12月之前应该增加库存,在以下日期的节假日到来之前也应该增加库存:2010-02-12、2010-09-10、2010-11-26、2010-12-31、2011-02-11、2011-09-09、2011-11-25、2011-12-30、2012-02-10、2012-09-07。同时,沃尔玛的销售人员应该关注燃油价。燃油价对居民消费指数的影响较大,在建立多元线性回归模型进行预测中,居民消费指数对销售额影响较大,从而燃油价间接影响了销售额。