1. 引言
在许多学科领域,如医学、生物学、保险精算学、经济学以及人口统计学等多个领域都需要研究生存分析问题,当所研究的问题只存在单一结局时,Kaplan和Meier提出的K-M方法 [1] 和Cox提出的Cox模型 [2] 是最为常用的方法,Cox模型是一种常用的生存分析模型,用于探讨与生存时间相关的因素。它假设风险比在时间的推移过程中是恒定的,不随时间变化。在被给出的协变量集合
下,个体i的风险可以分解成两个部分,一部分是包括协变量不包括时间,一部分包括时间不包括协变量。Cox模型基本形式如下:
其中
是基线危险函数,
是需要估计的参数或系数。
是惟一的有序感兴趣时间点,回归系数
由偏似然方程的最大值决定。累积危险函数为
,累积分布函数
可由
导出,
。
然而,所研究的问题并不总是单一结局的,因此在某些情况下,上述方法可能并不适用,其中一种情况就是存在竞争风险,Gelman [3] 和Gooley [4] 对竞争风险理论进行了描述,Kalbfleisch和Prentice [5] 提出了一种考虑竞争风险的方法,在存在竞争风险条件下,事件i发生在时间t之前的概率分布叫做子分布,类型i事件的累计发生率函数被定义为
,记为CIF,Fine和Gray [6] 于1999年提出了Fine-Gray模型,这是一种基于CIF建模的一种竞争风险模型,然而,所研究的问题并不总是单一结局的,因此在某些情况下,上述方法可能并不适用,其中一种情况就是存在竞争风险,Gelman [3] 和Gooley [4] 对竞争风险理论进行了描述,Kalbfleisch和Prentice [5] 提出了一种考虑竞争风险的方法,在存在竞争风险条件下,事件i发生在时间t之前的概率分布叫做子分布,类型i事件的累计发生率函数被定义为
,记为CIF,Fine和Gray [6] 于1999年提出了Fine-Gray模型,这是一种基于CIF建模的竞争风险模型,Fine-Gray模型在存在竞争风险的生存分析实际问题中有着广泛应用,朱旭 [7] 和钱迪 [8] 等分别以胃癌和肝癌患者为样本构建Fine-Gray模型研究生存分析问题。
2. Fine-Gray模型介绍
该模型基于
这里的
是子分布危险函数,
是子分布的基线危险函数,x是协变量向量,
是回归系数。其中子分布危险函数为
偏似然方程为
在所有的感兴趣的事件被观察到的时间点取乘积,其中
。Fine-Gray模型的偏似然形式和Cox比例风险模型相似,与Cox比例风险模型相比,Fine-Gray模型主要有两个差异,风险集合
定义方式不同以及引入了删失生存权重
。风险集合
由在时间t之前未经历事件的个体和在时间t之前经历了一个竞争风险事件的个体组成。
因此,那些经历过竞争风险事件的个体一直处于风险集中。在存在竞争风险的前提下,一种类型i事件在时间t之前不发生的概率称为子生存函数,定义为
。
删失生存概率权重
定义为
这里的
是删失生存分布函数的一个K-M估计,需要解释一下,删失生存分布定义为
,这里的
定义为观察到第一个事件的时间,如果未观察到事件则
,而观察到事件时
。在每个观测到感兴趣事件发生的时间点(下标为j),风险集合由在时间t之前未经历事件的个体和在时间t之前经历了一个竞争风险事件的个体组成。对给出的部分似然的对数进行求导,得到得分统计量:
表示回归系数
的估计,是函数
时
的取值。
为说明Fine-Gray模型的计算过程,给出示例数据集见表1。表1中包括10个观测个体,其观测到的时间点,事件类型,每个个体协变量为分别在表1的第1~4列。
备注:事件类型I:感兴趣事件;事件类型II:竞争风险事件 ;事件类型III:删失。
表1第5列给出了删失分布生存函数估计值
,这里的
由K-M估计计算可得,K-M方法的过程如下:假定
是唯一的删失时间点,设
为在
时间发生删失的个体数量,
为在
之前有经历该事件风险的个体数量。则
在10个观测个体中,有4个个体发生删失。删失时间点分别在
,这4个删失时间点的生存分布
值,计算如下;
在其他未发生删失6个时间点,每个时间点的生存函数估计值
与小于该时间点的前一个删失时间点的生存估计值相同。
在得到各个时间点的生存函数估计值后,可以计算删失生存概率权重
,计算过程见表2。观测个体单元在第1行,感兴趣(类型I)事件发生的时间点在第1列,表中数据为类型I事件在各阶段所在风险集中取得的权重
。

Table 2. Calculation process of weights w j i for deleted survival probabilities
表2. 删失生存概率权重
的计算过程
备注:表中“−”表示该单元对应时间点
不在讨论的风险集
中。
对于感兴趣事件(类型I),竞争风险事件(类型II),删失(类型III) 3种不同类型事件,10个观测个体他们在不同时刻的权重也不相同。
注意,在风险集
中,对于时间点
,当
时,由
,此时
当
时,权重小于1。
以个体4为例,其对应的删失生存概率权重
为
个体1和个体2在
和
时发生删失,在此之前没有观测到感兴趣事件,因此不在风险集中,个体3在
时观测到感兴趣事件,它只参与了第一项的部分似然,权重为1,个体4在
时观测到竞争风险事件,在
之前,权重为1,随着时间推移,权重逐渐降低。个体5在
时观测到感兴趣事件,参与了前两项的部分似然,权重为1。
对于本例,需要求解的得分统计量为:
将表2中的权重值和表1中的x代入可得
可以算出函数的解
。
3. 基于Fine-Gray模型的CIF估计
定义
为子分布的累计危险函数,它的估计计算方法如下
其中t表示感兴趣的时间点,
为代入的协变量,
为回归系数的估计值。
通过累积危险函数
可计算CIF的估计值,计算公式如下:
利用表1中的示例数据集,代入4个感兴趣时间点及对应协变量,计算累计危险函数以及CIF的估计值。
CIF的估计值为
4. 实例分析
数据来自R中的数据集(survival包中的mgus2),共计1371例单克隆丙种球蛋白病患者,其中结局事件定义为“发生浆细胞恶性肿瘤”有114例,而结局事件是在“发生浆细胞恶性肿瘤”之前因其他原因死亡患者有855例,这些发生“其他死亡”的患者因无法观察到“发生浆细胞恶性肿瘤”的终点,就被称为与“发生浆细胞恶性肿瘤”存在竞争风险的事件,其他402例患者是在观测期间上述结局事件没有发生。研究指标变量定义与赋值见表3。
Table 3. Definitions and assignments of variables
表3. 各变量的定义与赋值
协变量x有两个,分别为血红蛋白水平和年龄,记为x1,x2,创立协变量矩阵。生存时间t对类型I事件表示直至发展为浆细胞恶性肿瘤或最后一次访视时间,对类型II事件表示直到死亡或最后一次接触的时间,对类型III事件表示最后一次接触时间。
数据集mgus2中的各个变量的统计描述见表4。
Table 4. Statistical description of variables
表4. 变量的统计性描述
利用Fine-Gray模型分析建模,这里的协变量为x1,x2,自变量为生存时间t,响应变量为回归系数
。
如果用Cox模型进行回归分析,由于不考虑竞争风险,因此在考虑类型I事件时,将类型I事件为感兴趣事件,类型II和类型III事件改为删失事件,在考虑类型II事件时,则将类型II事件作为感兴趣事件,类型I和类型III事件改为删失事件。
利用Fine-Gray模型和Cox模型建模所得结果见表5。
Table 5. Comparison between Fine-Gray model and Cox model
表5. Fine-Gray模型与Cox模型对比
根据表5,可得出以下结果:
在对类型I事件建模中,Fine-Gray模型与Cox模型估计结果差异很大。Fine-Gray模型协变量x1的回归系数不显著,x2的回归系数显著。Cox模型估计结果则与之相反。而在对于类型II事件建模中,Fine-Gray模型与Cox模型估计结果非常接近。协变量x1和x2对应的回归系数都非常显著。说明利用Fine-Gray模型与Cox模型的建模区别主要体现在对类型I事件的估计结果上。主要由于Cox模型只针对样本中发生类型I事件114例的个体建模,而Fine-Gray模型在考虑了发生类型I事件的114例个体基础上,还考虑发生类型II (竞争风险)事件的855例个体,在建模过程中,通过表2中的权重计算方法,算出竞争风险事件个体的权重,并且随着时间推移,竞争风险事件个体在风险集中的权重逐渐降低。
为了更直观的说明Fine-Gray模型与Cox模型的区别,分别绘制类型I事件的累计发生率的曲线图。以mgus2数据集协变量的中位数
,
,编号为135的患者为例,分别用Fine-Gray模型和Cox模型对发生浆细胞恶性肿瘤这一感兴趣事件的累计发生率进行预测,结果见图1。
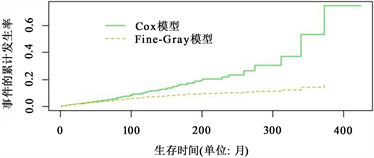
Figure 1. Predictive comparison between Fine-Gray model and Cox model
图1. Cox模型与Fine-Gray模型对比预测图
5. 结语
由第3部分实证对比分析可以看出,Fine-Gray模型适用于具有多个终点的生存数据,在存在竞争风险的情况下,得到的结果更符合实际,具有更好的拟合性。如临床上常见术后死亡患者无法获取关心终点,故术后死亡与关心终点存在竞争风险。相比之下,使用传统Cox模型会忽略竞争风险,可能高估所研究事件的累计发生率。
基金项目
本研究由2022年度辽宁省研究生教育教学改革研究项目(2022-180-39510165)资助。
NOTES
*通讯作者。