1. 引言
在多属性群决策中,研究问题通常具有定性和定量双重属性,例如:评估一项金融理财产品,评价属性包括市场占有率、预期收益率、风险控制水平、历史收益率、市场环境等。其中,市场占有率、预期收益率、历史收益率属于定量属性,而风险控制水平、市场环境属于定性属性。在经典多属性群决策过程中,决策者通常使用精确数来表达他们对备选方案在每个属性下的评价值。然而,随着决策问题日益复杂化和人们思维的不确定性和模糊性,决策者很难给出精确的评价值,尤其对于定性属性来说。为解决此问题,Zadeh [1] 于1965年提出了模糊集理论,为描述这种模糊信息提供了一个很好的工具,得到了很多学者的研究和拓展,如语言术语 [2]、直觉模糊集 [3]、犹豫模糊集 [4] 等。考虑到人们的知识背景、社会经验和信息对称等差异以及决策问题本身的复杂性和不确定性,不同决策者可能倾向于利用自己熟悉或偏好的数据类型给出备选方案在某一属性上的评价值,如实数、区间数、模糊数、语言术语等;甚至对于同一决策者,其也可能利用不同类型的数据给出备选方案在不同属性上的评价值。这类决策问题称为混合多属性群决策问题。例如:对于金融理财产品评估问题,决策者通常用精确数表示市场占有率和预期收益率、用区间数表示历史收益率、用语言术语表示风险控制水平和市场环境。
针对混合多属性群决策,如何对不同数据类型的评价信息进行集结是该研究的一个重点问题。围绕该问题,现有研究方法主要分为两大类:(1) 直接对不同数据类型的评价信息进行集结。Lourenzutti等 [5] 对TOPSIS方法进行拓展以处理动态环境下的混合多属性群决策问题,该方法对不同的属性模块进行分组,每一组采取相同的数据类型,不进行数据转化,直接对分组数据应用不同的得分函数,并根据属性之和的总得分对备选方案进行排序。赵萌 [6] 在构造不同数据类型的愿景满意度函数的基础上,通过集成各方案满足愿景的程度对备选方案进行排序。龚承柱等 [7] 根据决策者对不同属性的期望值,将具有精确数、区间数和语言术语的决策矩阵转化成为前景决策矩阵,并通过计算各方案的综合前景值对备选方案进行排序。此类方法一般要求不同决策者在同一属性下必须采取相同的数据类型并给出其评价值,如果考虑到决策者的知识背景、社会经验和信息对称等方面的不同,不同决策者对于同一属性可能倾向于采用不同类型的数据,这时此类方法就不再适用。(2) 将不同数据类型的评价信息转化为统一形式后,再对其进行集结。张发明等 [8] 利用全序列法、二元语义和相对优势度模型对多种数据类型进行处理后,将其转化为实数与区间数,并通过对信息进行静态集结,求得每个方案的综合排序值。马金山 [9] 利用二元联系数向量分别对不同数据类型的指标值和权重进行处理,得到归一化各方案的各单指标向量与靶心指标向量的接近度和确定性权重,进而求得每个方案的综合接近度。Peng等 [10] 通过将不同数据类型映射到统一语言域,提出了基于精确数、区间数和语言术语的TOPSIS方法。此类方法主要聚焦于如何最小化数据类型转化过程中的信息丢失,以期最大程度上保留决策者的初始评价信息。
现有多属性群决策方法通常假设决策者是绝对理性的,而现实生活中由于决策者受各种条件的限制以及随机因素的影响,所获取的信息有一定的局限性,因而通常呈现出相对理性的特征,即做出的决策与理性预期之间存在偏差。为解决此问题,Gomes等 [11] 在前景理论的基础上,提出了交互式多准则决策(TODIM)方法,该方法在决策过程中考虑到决策者的心理因素和理性预期,能够有效地刻画决策者有关风险的心理行为。目前,TODIM方法已被广泛地应用于经济管理等多个领域,并考虑到传统TODIM方法只能用于处理精确数,许多学者对TODIM方法进行了不同角度的拓展。Ren等 [12] 将TODIM方法拓展到属性值为对偶犹豫模糊数的环境中,来解决相应的多属性群决策问题。Sang等 [13] 基于传统TODIM方法,提出了属性值为区间二型犹豫模糊数的多属性群决策方法。Lourenzutti等 [14] 考虑属性之间的关联性,将Choquet积分引入TODIM和TOPSIS方法中,提出了基于动态异质信息的多属性群决策方法。Fan等 [15] 在利用累积分布函数表示精确数、区间数和模糊数的基础上,通过计算每个属性下各方案相对于其他方案的损益值,构造损益矩阵,进而求得各备选方案的综合优势度以确定方案的最终排序。
为了最大程度地减少不同类型数据转化过程中的信息丢失,本文基于概率语言术语集的隶属度函数,将不同数据类型的评价信息统一转化为概率语言术语集,并在利用离差最大化思想确定属性权重的基础上,考虑决策者的心理行为和理性预期,将传统TODIM方法拓展到概率语言环境下,提出一种基于TODIM的属性权重未知的混合多属性群决策方法。
2. 基础理论
定义1 [16]:在实数域R上定义区间数
,其中:
,且满足
,
和
分别代表区间数a的上限和下限。区间数a的中心用
表示,宽度用
表示。当
时,区间数a是一个实数。
定义2 [17]:定义一个模糊集
,当满足
的形式时,称
为三角模糊数,
且
。该三角模糊数的隶属度函数表示为:
(1)
定义3 [18]:定义一个语言术语集
,其中:
为语言术语集S中的第i + 1个语言术语;
(
取偶数)表示语言术语集S中元素的个数,称为基数;
和
分别表示语言术语集S的最大和最小语言术语,且满足以下性质:
(1) 当
时,
。例如,基数为5的语言术语集S可以表示为:S = {s0 = 很差, s1 = 差, s2 = 一般, s3 = 好, s4 = 很好};
(2) 存在逆算子:
,且满足
。
为了防止在语言信息集结过程中出现信息缺失,Xu [19] 将离散的语言术语集扩展到连续情形,提出了虚拟语言术语集
。通常来说,决策者使用离散语言术语集给出其初始决策偏好,而虚拟语言术语集只出现在运算过程中。
定义4 [20]:假设
为一个语言术语集,则概率语言术语集可以被定义为:
(2)
其中,
表示语言术语
的概率为
,
表示概率语言术语集
中元素的个数,
是语言术语
的下标,
中的元素通常是按照
值的升序进行排列。对于任意两个概率语言术语集
和
,若
,则需要对元素个数相对较少的集合增加
个语言术语,使两个集合的元素个数一致,且增加的语言术语的概率为0。
定义5 [20]:当
时,说明概率语言术语集
中的概率语言信息不完全。对于概率语言信息不完全的概率语言术语集
,需要对其进行标准化处理:
(3)
为了便于计算,下文中任意给定的两个及以上概率语言术语集,其中的元素都是经过标准化且有序处理的,并通过增加元素使得概率语言术语集的元素个数相等。
定义6 [21]:设
、
和
为任意三个概率语言术语集,其运算规则如下所示:
(1)
(4)
(2)
(5)
(3)
(6)
(4)
(7)
其中,
、
和
分别表示语言术语
、
和
的下标。
定义7 [21]:设
为语言术语集S上的一个概率语言术语集,则
的期望函数
和方差函数
分别为:
(8)
(9)
其中,
表示语言术语
的下标。
由此可得,
的得分函数为:
。根据得分函数
,对于任意两个概率语言术语集
和
,得分函数数值越低,说明概率语言术语集越小,反之越高,即:
(1) 若
,则
;
(2) 若
,则
。
定义8 [21]:对于任意两个概率语言术语集
和
,其中
表示
中语言术语
的下标,
表示
中语言术语
的下标,则二者之间的标准化汉明距离为:
(10)
其中,
表示概率语言术语集
和
中的元素个数。
定义9 [22]:设
为n个概率语言术语集,其对应的权重向量为
,满足
,
且
,则概率语言加权平均(PLWA)算子定义为:
(11)
其中,
表示语言术语
的下标。
3. 基于TODIM的属性权重未知的混合多属性群决策方法
TODIM方法的主要思想是基于前景理论给出的价值函数,构造某一方案相对于其他方案的优势度函数,并根据总体优势度对所有备选方案进行排序。由于决策环境的不确定性与评价属性的多样性,为了准确地表达决策者的偏好信息,允许决策者利用不同类型的数据表示其对备选方案的评价信息。同时,考虑到决策者的心理行为和理性预期,提出了基于TODIM的属性权重未知的混合多属性群决策方法。首先,对不同数据类型的评价值进行规范化处理,将其转化到[0, 1]。然后,为了避免不同类型数据转化过程中的信息丢失,提出了将规范化评价值包括精确数、区间数、语言术语转化为概率语言术语集的方法。最后,在利用离差最大化思想确定属性权重的基础上,将传统TODIM方法拓展至概率语言环境下,通过计算各方案的总体优势度,确定方案的最终排序。
针对属性权重未知的混合多属性群决策问题,设有s个决策者
,m个方案
,n个评价属性
,对应的权重向量为
,满足
,
且
。决策者
给出的方案
在属性
下的评价值为
,构成的个体决策矩阵记为
。n1、n2和n3分别表示评价值为精确数、区间数和语言术语的属性下标集合,且
。如果
,则评价值
为精确数;如果
,则评价值
为区间数;如果
,则评价值
为语言术语。
3.1. 不同数据类型的规范化方法
获取个体决策矩阵
后,为了消除量纲的影响和便于将不同数据类型进行一致化处理,需要对数据进行规范化处理,求得规范化个体决策矩阵
。具体处理方式如下所示:
(1) 当属性
(
)时,精确数
的规范化处理方法为:
(12)
(2) 当属性
(
)时,区间数
的规范化处理方法为:
(13)
(3) 当属性
(
)时,每个语言术语
的隶属函数均与一个三角模糊数
相对应。如果三角模糊数不位于[0, 1],则需要对其进行规范化处理:
(14)
其中,CB和CC分别表示效益型属性集和成本型属性集。
3.2. 不同数据类型转化为概率语言术语集
为了解决混合数据环境下的评价信息集结问题,本文提出了将规范化评价值包括精确数、区间数、语言术语转化为概率语言术语集的方法。假设概率语言术语集对应的语言术语集为:S = {s0 = 非常差, s1 = 很差, s2 = 较差, s3 = 一般, s4 = 较好, s5 = 很好, s6 = 非常好},其隶属函数如表1和图1所示。

Table 1. Membership functions of linguistic terms
表1. 语言术语的隶属函数
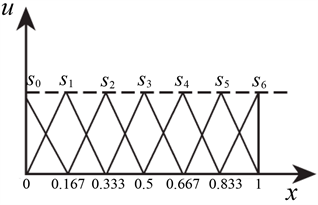
Figure 1. Membership functions of linguistic terms
图1. 语言术语的隶属函数
(1) 精确数转化概率语言术语集
假设决策者
给出的方案
在属性
的规范化评价值为精确数
且同时与两个相邻的语言术语
与
相交(
),其隶属度分别为
和
,如图2所示。
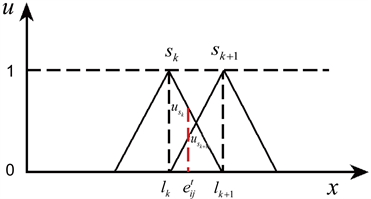
Figure 2. Intersection of crisp numbers with linguistic terms sk and sk+1
图2. 精确数与语言术语sk与sk+1相交
为了将精确数
转化为概率语言术语集,首先利用公式(15)分别计算精确数
在语言术语
与
上的隶属度:
(15)
然后,对隶属度进行规范化处理,求得精确数
属于语言术语
与
的概率:
(16)
最后,求得精确数
对应的概率语言术语集为:
。特殊地,当精确数
仅与一个语言术语
相交,即与语言术语
的峰值重合时,
属于
的概率为1,其对应的概率语言术语集为:
。
(2) 区间数转化概率语言术语集
假设决策者
给出的方案
在属性
的规范化评价值为区间数
且与两个相邻的语言术语
与
相交(
),如图3所示。
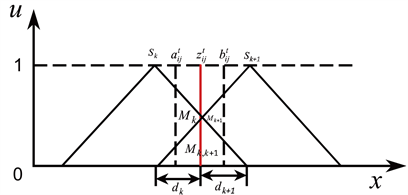
Figure 3. Intersection of interval numbers with linguistic terms sk and sk+1
图3. 区间数与语言术语sk和sk+1相交
为了将区间数
转化为概率语言术语集,首先利用公式(17)和(18)分别计算区间数
在语言术语
与
交叉面积
的分配因子:
(17)
(18)
其中,
与
的单独相交面积为
,
与
的单独相交面积为
,
表示
峰值与区间数
的中点值
之间的距离,
表示区间数
的中点值
与
峰值之间的距离。
然后,利用公式(19)分别求得区间数
属于语言术语
与
的概率:
(19)
最后,求得区间数
对应的概率语言术语集为:
。
(3) 语言术语转化概率语言术语集
假设决策者
给出的方案
在属性
的规范化评价值为语言术语
,且每个语言术语的隶属函数为三角模糊数
并与两个相邻的语言术语
与
相交(
),如图4所示。
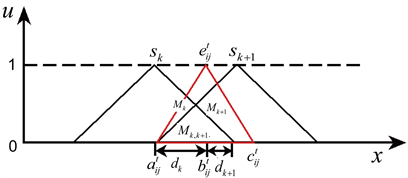
Figure 4. Intersection of linguistic term with linguistic terms sk and sk+1
图4. 语言术语与语言术语sk和sk+1相交
类似于区间数,为了将语言术语
转化为概率语言术语集,首先利用公式(20)和(21)分别计算
在语言术语
与
交叉面积
的分配因子:
(20)
(21)
其中,
与
的单独相交面积为
,
与
的单独相交面积为
,
表示
峰值与
峰值
之间的距离,
表示
峰值
与
峰值之间的距离。
然后,利用公式(22)分别求得语言术语
属于语言术语
与
的概率:
(22)
最后,求得语言术语
对应的概率语言术语集为:
。除此之外,还需要注意以下三种特殊情形下的转化方法:
a) 当语言术语
完全位于语言术语
的隶属函数内时,
属于
的概率为1,对应的概率语言术语集为:
。
b) 当语言术语
仅与语言术语
相交,且不与其他语言术语相交时,无论其是否完全位于语言术语
的隶属函数内,
属于
的概率为1,对应的概率语言术语集为:
。
c) 当语言术语
同时与两个以上语言术语相交时,可以参照公式(20)和(21)分别计算
在各语言术语交叉面积的分配因子,以求得
属于每个语言术语的概率。
3.3. 确定属性的权重
利用上述不同数据类型转化为概率语言术语集的方法,规范化个体决策矩阵
转化为概率语言个体决策矩阵
。在此基础上,为了对概率语言个体决策矩阵进行集结,利用离差最大化思想确定属性的权重,具体步骤如下:
Step 1:利用定义9中的PLWA算子对概率语言个体决策矩阵
进行集结,求得概率语言群体决策矩阵
。
Step 2:计算属性
下,方案Ai与其他方案
的评价值之间的偏差:
(23)
Step 3:计算属性
下,所有方案的偏差和:
(24)
Step 4:利用离差最大化思想,确定属性
的权重向量
。根据离差最大化的思想,当某一属性下所有方案的评价值存在较大差异时,说明该属性包含的评价信息量较大,该属性应被赋予较大的权重,反之赋予较小的权重。当不存在差异,即所有方案的评价值相等时,该属性在决策过程中不起任何作用,因而权重为零。
(25)
其中,
且
。
3.4. 基于概率语言术语集的TODIM方法
基于概率语言群体决策矩阵 ,本文将传统TODIM方法拓展至概率语言环境下,通过计算各方案的总体优势度,确定方案的最终排序,具体步骤如下:
,本文将传统TODIM方法拓展至概率语言环境下,通过计算各方案的总体优势度,确定方案的最终排序,具体步骤如下:
Step 1:选取权重最大的属性作为参照权重,记作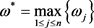 ,并计算属性
,并计算属性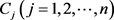 的相对权重
的相对权重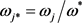 。
。
Step 2:计算属性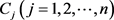 下,方案Ai相对于其他方案
下,方案Ai相对于其他方案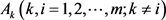 的优势度:
的优势度:
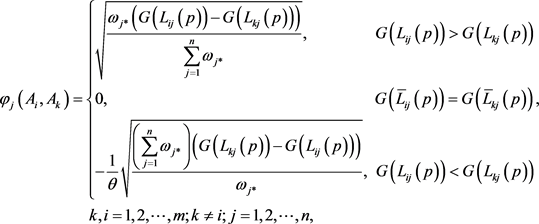 (26)
(26)
其中,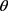 代表损失衰减系数,该系数受决策者个人偏好的影响,该系数取值越小,表明决策者的损失规避程度越高,根据前景理论,通常取
代表损失衰减系数,该系数受决策者个人偏好的影响,该系数取值越小,表明决策者的损失规避程度越高,根据前景理论,通常取 ;
; 表示
表示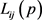 的得分值。
的得分值。
Step 3:计算方案Ai相对于其他方案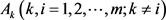 的综合优势度:
的综合优势度:
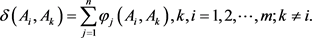 (27)
(27)
Step 4:计算方案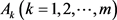 的总体优势度:
的总体优势度:
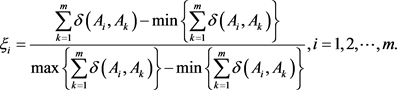 (28)
(28)
Step 5:按照方案总体优势度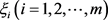 由大到小的顺序,对备选方案进行排序。
由大到小的顺序,对备选方案进行排序。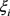 越小,代表该方案越差;
越小,代表该方案越差;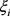 越大,代表该方案越好。
越大,代表该方案越好。
4. 算例分析
某理财公司准备将资金投给某一项金融理财产品,经过一段时期的市场分析,大致确定了四项理财产品作为备选方案,对应的备选方案集为 。该公司邀请了3名投资顾问组成专家团队
。该公司邀请了3名投资顾问组成专家团队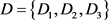 在市场占有率(C1)、历史收益率(C2)、预期收益率(C3)、风险控制水平(C4)四个属性下对理财产品进行评估,所有属性均为效益型属性,其中市场占有率(C1)和预期收益率(C3)用精确数表示、历史收益率(C2)用区间数表示,风险控制水平(C4)用语言术语(语言术语的隶属函数如表2所示)表示。3名专家给出的决策矩阵如表3所示。
在市场占有率(C1)、历史收益率(C2)、预期收益率(C3)、风险控制水平(C4)四个属性下对理财产品进行评估,所有属性均为效益型属性,其中市场占有率(C1)和预期收益率(C3)用精确数表示、历史收益率(C2)用区间数表示,风险控制水平(C4)用语言术语(语言术语的隶属函数如表2所示)表示。3名专家给出的决策矩阵如表3所示。
Table 2. Membership functions of linguistic terms corresponding risk control level
表2. 风险控制水平对应的语言术语的隶属函数
Table 3. Individual decision matrices
表3. 个体决策矩阵
Step 1:利用公式(12)~(14)对个体决策矩阵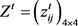 进行规范化处理,求得规范化个体决策矩阵
进行规范化处理,求得规范化个体决策矩阵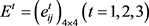 ,如表4所示。
,如表4所示。
Table 4. Normalized individual decision matrices
表4. 规范化个体决策矩阵
Step 2:基于表1所示的概率语言术语集对应的语言术语的隶属函数,利用3.2节的不同数据类型转化为概率语言术语集的方法,将规范化个体决策矩阵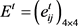 转化为概率语言个体决策矩阵
转化为概率语言个体决策矩阵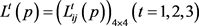 ,如表5所示。
,如表5所示。
Table 5. Probabilistic linguistic individual decision matrices
表5. 概率语言个体决策矩阵
Step 3:利用定义9中的PLWA算子对概率语言个体决策矩阵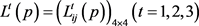 进行集结,求得概率语言群体决策矩阵
进行集结,求得概率语言群体决策矩阵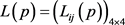 ,如表6所示。
,如表6所示。
Table 6. Probabilistic linguistic group decision matrix
表6. 概率语言群体决策矩阵
Step 4:根据离差最大化思想,利用公式(23)~(25)确定属性的权重,如下所示:
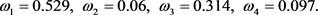
Step 5:选取权重最大的属性C1作为参照权重,计算每个属性的相对权重,如下所示:
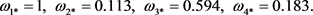
Step 6:取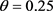 ,利用公式(26)和(27)计算方案Ai相对于其他方案
,利用公式(26)和(27)计算方案Ai相对于其他方案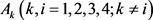 的综合优势度,如下所示:
的综合优势度,如下所示:
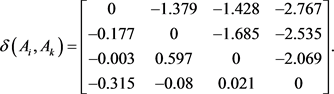
Step 7:利用公式(28),计算方案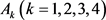 的总体优势度,如下所示:
的总体优势度,如下所示:
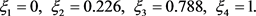
Step 8:按照方案总体优势度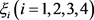 由大到小的顺序,对备选方案进行排序:
由大到小的顺序,对备选方案进行排序: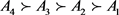 。由此可得,A4为最满意方案。
。由此可得,A4为最满意方案。
5. 结论
本文提出了基于TODIM的属性权重未知的混合多属性群决策方法,该方法考虑到决策者的知识背景、社会经验和信息对称等差异以及决策问题本身的复杂性和不确定性,允许决策者采用不同类型的数据给出其评价信息,并将决策者的心理行为和理性预期引入决策过程过程中。首先,为了对评价信息进行集结,在对评价信息进行规范化处理的基础上,提出了将精确数、区间数和语言术语转化为概率语言术语集的方法。然后,通过对个体决策矩阵进行集结,利用离差最大化思想确定属性的权重,并将传统TODIM方法拓展到概率语言环境下,计算每个方案相对于其他方案的综合优势度,构造损益矩阵,进而求得各方案的综合优势度以确定方案的最终排序。最后,通过算例验证了该方法的可行性。
基金项目
教育部人文社会科学研究青年基金(19YJC630107)、对外经济贸易大学中央高校基本科研业务费专项资金资助(20YQ04)、对外经济贸易大学中央高校基本科研业务费专项资金资助(17QN01)。