1. 引言
光谱解混是高光谱图像众多应用中需要解决的一个关键问题 [1] 。传统的光谱解混方法假定每类地物仅有一种端元光谱,其端元集是固定的 [2] 。由于地物的复杂多样性和成像条件的影响,在高光谱图像中“同物异谱”和“异物同谱”现象普遍存在 [3] [4] ,导致用固定的端元集对高光谱图像进行解混时,精度将受到很大的限制。因此,研究端元可变的高光谱图像光谱解混算法对提高高光谱图像的应用效果具有重要的意义。
目前国内外学者已经提出了一些可变端元提取算法,如Bateson提出了一种端元束的概念表示可变端元 [5] ;2003年Xiaofeng Ren提出了超像元的概念 [6] ,利用像元之间特征的相似程度对像元进行分组,很大程度的降低了后续图像处理的复杂度;2011年Martin等人提出了基于区域的空间预处理的端元提取算法 [7] ,主要利用图像分割进行预处理,并通过正交子空间投影(Orthogonal subspace projection, OSP)确定均值区域,用于最终的端元提取;Torresmadronero MC等人提出了对高光谱的端元提取使用聚类分析 [8] ,所得到的聚类结果用于模拟图像中的可变端元成分;基于高光谱的端元束提取(Image-Based Endmember Bundle Extraction, EBE) [9] 算法从高光谱图像上随机选取子集进行端元提取,然后合并所有的端元,最后对所有的端元光谱进行聚类,从而使每种地物都由一组端元光谱(端元束)来表示;2015年Mingming Xu等人提出了PPI结合光谱空间信息(Pure Pixel Index Combined with Both Spatial and Spectral In-formation, PPISS, PPISS) [10] 的端元束提取算法,首先利用PPI端元提取算法进行预处理,假设纯像元更有可能位于均质区域,利用均质性指数(Homogeneity index, HI)指数来自适应地为每一块区域选择不同的阈值,并对端元光谱聚类分析。相比EBE算法,PPISS算法性能有所提升。
上述端元束提取算法存在两个主要问题:1) 同一超像素内可能提取多个端元;2) 没有考虑最后冗余端元的去除。针对这两个问题,借鉴PPISS算法中PPI提取候选端元的思想和均质性指数的定义,结合超像素分割,本文提出了一种像元纯度指数结合超像素分割(Pure Pixel Index Combined with Super-pixel Segmentation, PPISPS)的端元束提取算法。该算法的基本思想是:通过PPI提取初始候选端元,每个超像素内保留一个候选端元并以超像素为邻域计算其均质性,对保留的端元根据均质性指数进行筛选,筛选后的候选端元进行聚类分析,每类地物都得到一束端元光谱,并进一步去除同类端元束的冗余端元。
2. 相关理论基础
2.1. 基于熵率的超像素分割
超像素是指根据图像颜色和距离等相似性度量,把图像分割成若干个均匀、形状规则且互不重叠的子区域的过程,每个子区域都包含着一定的空间纹理特征。基于熵率超像素分割方法 [11] 是目前用得比较多的一种方法,其基本思想是将图像映射成加权无向图
,其中
表示图像像素的集合,
表示边的集合,利用无向图上随机游走的熵率作为评价每个超像素均匀且紧凑的标准,将
分成几个连通子集,每个连通子集为一个超像素。
假设
是选定的边集,则图
的随机游走的熵率为:
(1)
其中𝑢表示随机游走中的平稳分布状态,pi,j表示随机游走转移的概率。平衡函数定义为:
(2)
其中
是分割后连通子集的数目,对A的分割结果为
。组合了熵率和平衡函数的
目标函数表示为:
(3)
其中
为平衡系数。
如果要把一张图像分割成k个超像素,通过不断优化目标函数(3),就会得到k个集合,每个集合就是一个超像素。
2.2. 基于纯像素指数的端元提取算法
纯像元指数端元提取(Pixel Purity Index, PPI) [12] 算法假定高光谱所有混合像元位于单形体的内部,而端元位于单形体的边缘,主要步骤如下:
1) 利用主成分分析 [13] 或最大噪声分离变换 [14] 方法对高光谱数据进行降噪处理和降维处理。
2) 将特征空间中的所有像元投影到随机生成的向量上。
3) 统计每个像元投影在向量两端的次数,即为每个像元的纯净像元指数。
4) 像元的纯净指数越高,表明该像元为端元的概率越大。
3. PPISPS算法
PPISPS算法流程如图1所示,整个算法分6个步骤,具体过程如下:
1) 超像素分割
由于高光谱数据的波段数较多,为了加快计算速度并且减小噪声波段的影响,首先利用主成分分析法对数据进行降维,选取特征值最大的3个分量。然后调用基于熵率的超像素分割算法,得到超像素集合。
2) 端元提取
PPI提取初始候选端元集E1,并记录每个端元在图像中的坐标。
3) 端元筛选
对初始候选端元集E1中的端元进行筛选,得到端元集E2。筛选方法为:如果一个超像素内如果存在多个端元,则计算其内每个端元的均质性指数(Homogeneity index, HI),HI指数越小,越有可能是端元,只保留超像素中HI指数最小的端元。如果一个超像素内只含有1给端元,则直接保留该端元。
用光谱信息散度(Spectral Information Divergence, SID)度量两个光谱的相似性,HI指数定义为
(4)
(5)
其中,
为超像素中的一条端元光谱,
为
所在的超像素,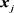 为
中的一个像元,
,
,L为波段数。
为
中的一个像元,
,
,L为波段数。
4) 端元聚类
利用K-means算法对端元集E2中的元素进行聚类分析,得到聚类后的端元束E3。通过不断计算所有像素点到种子点的相似性度量值的距离,从而确定各个像元属于哪个类。K-means采用如下相似性度量:
(6)
其中
和
为两个端元光谱。
越小,两个端元越相似。
5) 冗余端元去除
聚类以后,同类地物的端元束中仍可能会存在非常相近的端元光谱,因此,需要进一步去除这些同类冗余端元。以端元束E3中第i类端元
为例,首先对
进行排序,使得
。同类冗余端元去除的伪代码如下:如表1所示

Table 1. Redundant endmember of removing pseudo code
表1. 冗余端元去除伪代码
其中
表示排序后
中的第k条光谱,
表示
中的端元数,
为
去除冗余端元后的端元集,m为参数,T为阈值,其值可设为
中各个端元第m个波段最大值的0.05。
4. 实验结果
4.1. 仿真数据实验
从DIRSIG光谱库中选取了4类地物光谱并且保证类内光谱的欧式距离大于一定的值,使得它们具有区分度。光谱的种类和个数分别为:泥水8个,草地11个,混凝土9个,沥青9个,总波段数为178,光谱曲线如图2所示。
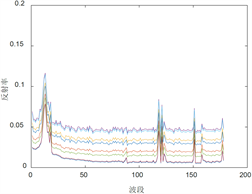 (a) Muddy water
(a) Muddy water 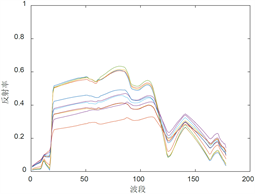 (b) Grassland
(b) Grassland 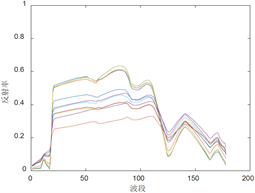 (c) Concrete
(c) Concrete 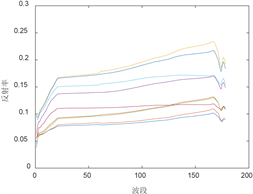 (d) Asphalt
(d) Asphalt
Figure 2. Four types of selected endmember spectra
图2. 选取的四类端元光谱曲线
用上述的4种端元光谱,按照如下的方式合成高光谱图像:将100 × 100的矩阵分成20 × 20个区域,即每个区域的大小为5 × 5个像素,每个区域的像素中分别存放四类地物端元光谱数据,每类地物随机选取一条类内光谱以随机的比例系数合成。随机的比例系数都满足和为一、非负两个条件。为了更加贴近真实的高光谱数据,添加信噪比为50 dB的高斯白噪声。第11波段的合成图像如图3所示。

Figure 3. Grayscale of synthetic image (band 11)
图3. 合成图像第11波段的灰度图像
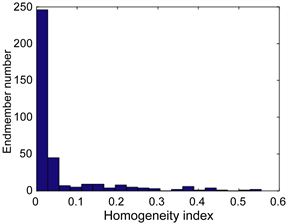
将本文提出PPISPS算法与平均分块结合PPI端元提取(Uniform segmentation combined with PPI, USPPI)、EBE以及PPISS这三种算法做对比实验,从而验证PPISPS算法的性能。其中USPPI是指将图像均匀地分块,对每块PPI提取端元,合并端元集再进行聚类分析。PPISPS算法中超像素分割一共把图像分割成625个超像素,超像素分析筛选后的端元的HI指数直方图如图4所示,去除了一部分HI指数较高的端元,最后一共提取了62个端元。
 (a) PPISS
(a) PPISS 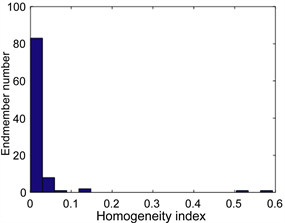 (b) PPISPS
(b) PPISPS
Figure 4. Histogram of HI
图4. HI直方图
图5给出了端元筛选前后的端元位置图,黄色“o”表示PPI提取的初始端元位置,白色“*”表示筛选之后保留的端元位置。PPISS一共提取了154个端元。对比图5(a)和图5(b),可以看出PPISPS提取的端元位置中每块超像素中只有一个候选端元,PPISS算法提取出的端元分布的很密集,说明PPISS算法得到的各类地物存在很多相似的端元。
 (a) PPISS
(a) PPISS  (b) PPISPS
(b) PPISPS
Figure 5. Position of endmembers
图5. 端元位置
图6分别给出了PPISPS、PPISS、USPPI和EBE四种方法提取的端元束光谱曲线图,其中,USPPI算法中块的大小为4 × 4个像素,平均分割成625块,一共提取了441个端元;EBE算法在全局利用PPI算法,一共提取了90个端元。所有算法用K-means对提取的端元光谱进行聚类分析。从图6可以看出,PPISPS算法提取的各类地物的端元光谱比较完整,而且各类地物中没有冗余的端元;而PPISS算法提取的各类地物的端元则存在较多的相似端元光谱,冗余度较高;USPPI和EBE算法提取的各类地物的端元光谱存在大量的相似以及接近重叠的端元光谱曲线。相比之下,PPISPS提取的端元最具代表性。
为了评价算法的精确性,采用光谱角距离(Spectral Angle Distance, SAD)度量每个提取的端元
和真实端元
之间的相似性
(7)
SAD的值越小,表明提取端元值越精确。但是由于每类地物用的是一束端元光谱表示,因此每类地物的多条端元分别保留和真实端元束计算得到的最小SAD值。图7以盒式图的形式给出了4种方法得到的4类地物的SAD结果。从图7可以看出,USPPI和EBE的SAD明显大于PPISS和PPISPS,并且USPPI相比EBE结果差一些。PPISS和PPISPS相比,除了Muddy,其他三种地物都是PPISPS的SAD更小。因此,四种方法中,PPISPS的结果最好,PPISS的结果次之。
 (a) PPISPS
(a) PPISPS  (b) USPPI
(b) USPPI  (c) EBE
(c) EBE  (d) PPISS
(d) PPISS
Figure 7. Box diagram of SAD
图7. SAD盒式图
4.2. 真实数据实验
仿真数据实验结果表明PPISS和PPISPS的结果优于其他两种方法,因此真实数据实验只对PPISPS算法和PPISS算法进行比较。真实数据采用Cuprite矿物数据(http://aviris.jpl.nasa.gov)。Cuprite图像由AVIRIS传感器获得,实验所用数据大小为250×191个像元,共224波段,去除因水汽吸收和低信噪比波段,实验所用的数据共188波段。
图8为超像素分析筛选后的端元位置图,白色“o”表示PPI提取的初始端元位置,红色‘+’表示筛选之后保留的端元位置。从图8可以看出,PPISS的结果中有很多密集的端元,也就是存在太多的冗余端元。PPISPS的结果中不存在密集分布的端元,这是因为PPISPS中每个超像素内只保留一个端元。
利用K-means聚类分为11类地物,根据与USGS光谱库(http://speclab.cr.usgs.gov)的光谱对比,可以确定每个端元束的类别,图9给出了其中6种端元束的光谱曲线,其中纵坐标为反射率,横坐标为波段号,每类PPISS提取的端元束在上,PPISPS在下。从图9可以看出,PPISS提取的各类地物端元束中都存在光谱曲线近似重叠的端元,而PPISPS则不存在这种现象。由此可见,PPISPS能够有效地减少端元束内的冗余端元。
 (a) PPISS
(a) PPISS  (b) PPISPS
(b) PPISPS
Figure 8. Position of endmembers in Cuprite dataset
图8. Cuprite图像端元位置
5. 结论
本文提出了一种新的基于超像素分割和纯净像元指数的端元束提取的方法,能够提取兼具空间分布合理和同类端元冗余度低的端元束。首先采用超像素的思想,将高光谱数据分割成很多超像素块,每个超像素中选取一个代表端元;然后利用均质性指数二次筛选端元;最后,根据端元光谱间的相似性,对聚类分析之后的每类地物进行端元束筛选,得到每类地物最终的端元束。实验结果表明本文提出基于超像素分割和像元纯度指数的端元束提取(PPISPS)算法有效的提高了端元束提取的准确性。