1. 引言
随着知识图谱数据规模的爆炸式增长,各个领域的数据用户希望能够准确、快速地获取所需的信息。问答系统作为信息检索的一种形式,它能以简单、准确的自然语言结果回答自然语言问题。问答系统是目前人工智能和自然语言处理领域中一个倍受关注并具有广泛发展前景的研究方向,在开放领域 [1] 和许多特定领域已经取得了不错的效果,例如生物医学问答系统 [2],地理领域问答系统 [3]。按照数据来源的不同,问答系统可以分为基于知识图谱的问答系统,基于阅读理解的问答系统,基于问答对的问答系统,本文研究的内容是基于知识图谱的问答系统。
问答系统的主流研究方法可以分为三类:1) 基于语义解析的方法。该方法的主体思想是将自然语言转化为格式化的逻辑形式,将问题的语义信息生成对应的逻辑形式。Liang [4] 通过解析器将问句转换成lambada-DCS表达式,并在知识图谱中检索得出答案。2) 基于信息抽取的方法。该类方法通过提取问题中的关键信息,通过检索知识图谱得到一系列候选答案,然后分别对问句和候选答案进行特征抽取得到特征向量,建立分类器对候选答案进行筛选。Yao等人 [5] 使用依存分析技术找到问句中的主要实体,利用实体信息从知识图谱中找到实体子图,抽取问句和实体子图的多种特征进行筛选,从而确定答案。3) 基于深度学习的方法。该类方法通过分布式表示把问题和候选答案都映射到同一向量空间,通过训练模型提高问题向量和正确答案向量的相似度得分。模型训练完成后则可根据候选答案的向量表示和问题表示的得分进行筛选。Dong等人 [6] 基于卷积神经网络提出了MCCNNs,模型使用答案路径、答案类型、答案上下文的向量表示之和作为问题的向量表示。
相较于英文问答系统的研究成果,中文问答系统的研究在规模和研究水平上存在很多差距。其中主要原因有两个。一方面,中文不像英文那样,词与词之间均使用空格分开,这就造成数据预处理中有额外的分词步骤。同时,这也使英文问答系统中现有的部分技术和已经产生的研究成果不可以直接投入使用。另外一方面,中文知识图谱的资源缺乏也是其一,而大规模的英文知识图谱却有很多,例如Freebase,YAGO,WordNet等。
NLPCC-ICCPOL发布的中文知识图谱以及相应的问答数据集,解决了数据缺乏这一问题。因此,本文拟采用深度学习、信息抽取相结合的方法,在开放领域的中文知识图谱问答做进一步探索。本文提出的知识图谱问答系统分为命名实体识别、属性抽取和答案检索三个部分。在命名实体识别阶段,通过改进BERT提出的BERDAT (Bidirectional Encoder Representation from Dynamic Attention Transformers)模型得到问句的Embedding向量,将此向量输入到BLSTM-CRF模型中,得到最佳的标记序列,从而识别出正确实体。属性抽取阶段通过BERDAT模型得到“问句–候选关系”对的Embedding,通过分类器判断出正确的属性值。最后在知识图谱中进行答案检索得到最终答案。通过对比实验,本文提出的知识图谱问答模型在NLPCC-KBQA数据集上取得了97.54%的F1分数,超越了此前公开的最佳模型。
2. 相关理论
2.1. 命名实体识别
命名实体识别(Named Entity Recognition, NER)是NLP中一项非常基础的任务,通过对输入文字的每个位置标注出相应的实体信息,实现实体识别的功能。常用的实体标注方法有BIO、BIOES、BMES,本文实验采用BIO标注方法。BIO将实体X标注为B-X、I-X、O的格式,其中B-表示实体的起始位置,I——表示实体的中间或结尾,O——表示不属于实体。
早期主要采用基于规则的方法,这些方法主要基于人工定义的语义和句法规则来识别实体,从而造成人工成本高、可移植性差等问题。因此,目前的研究主要集中在基于概率统计和基于深度学习的方法上 [7]。根据特征提取的方式不同,可以分为基于字符和基于词的嵌入方式。Lample等人 [8] 利用BiLSTM提取字符级特征,与词典中的词向量融合形成最终输入向量,并将BiLSTM和CRF模型相结合进行命名实体识别,在英语、德语、西班牙语等测试语料库中取得了良好的效果。Strubel等人 [9] 提出了一种基于扩张卷积神经网络(ID-CNNs)的模型,其通过skip-n-gram方法在 SENNA 语料上训练词嵌入向量。
这两种方法的各自优缺点也很明显,基于字符的嵌入方式切断了词的边界信息,丢失了隐藏在词中的语义特征。基于词的嵌入方法虽然保留了词的边界信息和语义特征,但是在数据训练过程中要先进行分词,如果分词错误就会影响整个模型的训练效果。为了综合各自的优点,Ma等人 [10] 利用CNN提取单词的字符级Embedding向量,然后将字符和词的Embedding向量相连接后输入到RNN上下文编码器。Peters等人 [11] 提出了基于字符卷积的ELMO词表示方法,可以根据上下文语境来生成相应词的向量表示。
2.2. BERT
BERT [12] 被Google提出后,在多项任务中都取得了突破性的进展。其网络架构使用的是多层Transformer结构,Transformer最大的特点是引入Attention机制,从而增加词向量模型泛化能力,充分描述字符级、词级以及句子级的关系特征。具体的模型结构如图1所示,其中输入的Embedding向量是由PositionEmbedding,SegmentEmbedding,TokenEmbedding相加得到。PositionEmbedding是编码单词出现的位置,SegmentEmbedding用于区分每一个单词属于句子A还是句子B,TokenEmbedding是每个单词的Embedding,三个形式的Embedding都是通过训练学习得到。

Figure 1. Network architecture of BERT
图1. BERT的网络结构
Transformer结构 [13] 是Google提出的注意力机制模型,该模型分为编码器和解码器两部分。在BERT中只用到了Transformer编码器,该编码器主要分为4个部分:多头注意力模型、归一化层、前馈网络层和归一化层。
3. 知识图谱问答模型
3.1. 模型流程
本文提出的知识图谱问答模型分为三大模块:命名实体识别、属性抽取和答案检索。首先通过命名实体识别步骤提取问句中的实体,然后检索知识图谱返回候选答案的三元组集合,最后通过属性抽取步骤对候选三元组中的属性进行筛选排序,最终输出得分最高的三元组中的答案。具体流程如图2所示。其中,命名实体识别和答属性抽取模型都使用BERDAT模型做特征提取,然后将特征作为输入,利用不同的网络结构完成相应的功能。

Figure 2. Flow chart of knowledge-based Question Answering
图2. 知识图谱问答流程图
3.2. BERDAT
Jawahar等人 [14] 等人通过实验验证了BERT每一层Transformer对文本的理解都有所不同,从浅层到高层可以分别学习到短语级别的,句法级别的,和语义级别的信息。因此,本文为了是输出向量更好的涵盖更多的信息,对BERT进行了改进,将十二层Transformer生成的向量进行动态融合,提出了BERDAT模型。
模型的设计如图3所示,其中[CLS]、Toki是模型对输入格式,Ei是对输入进行Embedding后得到的结果。Embeddingi是模型的第 层Transformer输出的结果向量。拼接层首先将每一层Transformer输出的向量先进行扩维,然后再进行合并,例如Embeddingi的维度是(64, 64, 768),那么12层Transformer进行拼接后的维度是(64, 64, 768, 12)。1 × 1卷积层的作用是把拼接后的向量降维,得到维度是(64, 64, 768, 1)的向量,最终对其进行调整,得到维度是(64, 64, 768)的输出向量。这和BERT的输出向量是相同的维度,达到了对多层Transformer融合的效果,同时也便于后文在BERDAT的基础上构建命名实体识别模型和属性抽取模型。
3.3. 命名实体识别模型
命名实体识别模型BERDAT-BiLSTM-CRF可分为特征提取和实体标注两部分,具体结构如图4所示。在特征提取部分中,长度为 的输入问句被处理成序列
,经过词嵌入后得到
个词向量,将其输入到BERDAT模型中后,得到的输出向量即为提取的特征向量。实体标注部分使用常见BiLSTM-CRF网络,首先将特征向量输入到双向LSTM层,将每个时间序列的正向反向输出拼接,经过全连接层映射为一个维度为标注类型数的向量。由于本文仅定义了一种实体类型,因此标注类型有3种,分别是“B-ENT”、“I-ENT”、“O”。最后,CRF层对上一层的输入向量求出条件概率最大的标注序列,将问句的每个位置打上了标注信息。
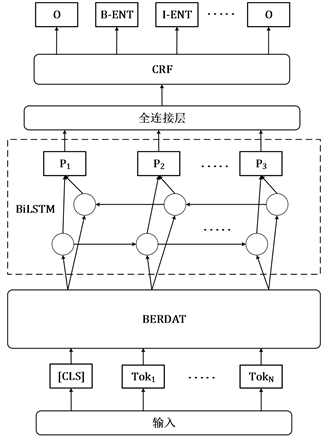
Figure 4. Named entity recognition model
图4. 命名实体识别模型
3.4. 属性抽取模型
完成命名实体识别后,在知识图谱中检索预测实体,将包含该实体的三元组作为候选三元组集合。然后将问句和三元组中的属性值做预处理,形成一个新的输入序列:“
问句
属性值
”。最后通过Softmax进行二分类,从而判断该序列中的属性是否正确。在训练过程中,标签为0的Softmax概率小则为错误属性,标签为1的概率大则为正确属性。
属性抽取模型如图5所示。特征提取的过程与命名实体识别模型一致,经过BERDAT网络后,取输出向量中
位置的向量
作为输入序列的特征向量,得到一个维度是(1,隐藏层个数)的特征矩阵。然后依次经过全连接层和Softmax层,得到两种分类各自的概率值,通过比较两个概率值确定该属性的分类。分类为0代表属性和问句不符合,反之则是正确属性。
4. 实验与结果分析
4.1. 数据集及实验环境
本文使用NLPCC-ICCPOL-2016发布的KBQA数据。该数据集提供了包含14,609个问答对的训练集和包含9870个问答对的测试集。本文从总的训练集划分出2609个问答对作为验证集,剩余12,000个问答对作为训练集。但是知识图谱中的数据是从百度百科中自动抽取的,导致数据集中存在不少的噪声,因此在实验之前首先对数据进行数据预处理。比如去除属性中出现空格和部分非中文字符,将所有大写字母转化成小写,去除信息缺失和信息不匹配的三元组数据。最终,NLPCC-KBQA数据集的划分情况如表1所示。

Table 1. Data set situation partition
表1. 数据集划分情况
本文实验运行在CPU为InterE5-2650、内存为62GB的计算机上,模型训练所用显卡为NvidiaGTX1080Ti,显存22GB,所用深度学习框架为Tensorflow1.12,操作系统为ubuntu18.04,知识图谱数据存储和检索使用MySQL8.0。
4.2. 命名实体识别
在命名实体识别的步骤中,使用NLPCC-NER数据集进行实验。该数据集是由预处理后的NLPCC-KBQA数据集通过实体标注生成的。具体的方法是利用问答对中的标准答案,反向查找问句对应的实体位置进行BIO标注。
实验中将学习率的区间设置为[3e−5, 5e−5],优化损失函数采用带权值衰减的Adam优化器 [15]。模型训练的超参数设置是:最大序列长度为128,Transformer多头数为12,Transformer层数为12,Transformer隐藏层的维度为768,LSTM神经元个数为128,dropout比率为0.9。最终BERDAT模型在NLPCC-NER的实验中,当学习率为4e−5时效果最好。相应的,验证集和测试集的评价结果如表2所示,精确率、召回率和F1分数均在97%以上,达到了很高的水平。
Table 2. Named entity recognition result (unit: %)
表2. 命名实体识别结果(单位:%)
4.3. 属性抽取
为了训练属性抽取模型,需要使用预处理后的NLPCC-KBQA数据集生成属性抽取数据集。在这个过程中,不仅要有正确的“问句–属性”对,还需要人为生成错误的“问句–属性”,从而提高模型的区分能力,避免出现过拟合的现象。制作正样本是在“问句–属性”对后面加上数字“1”,表示这是正确的样本;制作负样本则是在“问句–错误属性”对后面加上数字“0”,其中错误属性是在知识图谱的所有属性集合中随机选取5个,从而使得一个正样本能够生成5个负样本。得到的属性抽取数据集规模如表3所示。
Table 3. The size of attribute extraction dataset
表3. 属性抽取数据集规模
将属性抽取训练集数据送入BERDAT模型进行训练。超参数选取除了没有LSTM以外,与命名实体识别一致。属性抽取模型在验证集和测试集的测试结果如表4所示。属性抽取模型在验证集和测试集的准确率相差不大且均达到了98%以上。同时结合AUC指标,可以看出模型的属性区分能力很好,为知识图谱问答模型提供了有力的保障。
Table 4. Results of attribute extraction
表4. 属性抽取的结果(单位:%)
4.4. 知识图谱问答结果
通过命名实体识别和属性抽取步骤后,选择各自表现最好的超参数,应用在知识图谱问答系统中,最终的测试结果如表5所示。其中验证集和测试集都来源于NLPCC-KBQA预处理后的原始问答对。在测试集取得了很好的实验结果,三个评价指标均超过了96%。
Table 5. Result of knowledge-based Question Answering
表5. 知识图谱问答的结果(单位:%)
在公开的评价指标中以测试集的F1分数为准。本文对比了与其他公开模型的测试结果,如表6所示。其中,DPQA [16] 是王玥等人基于无监督方法提出的动态规划知识图谱问答,虽然无监督的方式可以减少人工标记的工作量,但其问答效果不算太好。InsunKBQA [17] 是周博通等人基于知识图谱三元组中谓词的属性映射构建的问答系统。PKU [18] 是NLPCC-ICCPOL-2016KBQA任务评测成绩的第一名,主要依靠人工规则来提高问答系统的性能,例如构造正则表达式去掉问句中的冗余信息。WHUT [19] 是张芳容等人通过句法分析等方式实现的问答系统。SCU [20] 使用BERT进行特征提取,将答案选择分解为答案匹配和阈值选择两个步骤。
Table 6. Comparison of results of different question answering models in test set
表6. 不同问答模型在测试集的结果对比(单位:%)
与上述问答模型相比,本文问答模型的F1分数分别提升了26.54%、16.19%、15.07%、14.6%、10.49%,取得了目前公开模型中最高的分数。主要原因是本文在BERT的基础上改进,提出了BERDAT模型,提高了对语言的理解能力,从而更好的提取问句中的特征,让命名实体识别模型和属性抽取模型的性能均得到提升。
5. 结语
本文根据NLPCC-ICCPOL-2016提供的开放领域的问答数据集,提出了基于BERDAT的知识图谱问答模型,分为命名实体识别、属性抽取和答案检索三个部分。首先通过命名实体识别模型提取问句中的实体,然后以该实体为关键词检索知识图谱,得到候选三元组集合,接着通过属性抽取模型对候选三元组集合中的每一个属性值进行判断。最后,通过筛选的三元组视为预测三元组,并将其中的第三个元素作为答案输出。
命名实体识别和属性抽取是大规模知识图谱问答的两个难点,本文提出了相应的模型解决这两个问题。在进行命名实体识别时,先使用BERDAT进行特征提取,然后使用BiLSTM-CRF模型进行实体预测。在进行属性抽取时,将其看作二分类任务,结合BERDAT和Softmax来判断属性是否正确。最后,本文方法在NLPCC-KBQA数据集上的F1分数为97.54%,与以往已公开的方法相比取得了更好的结果。