1. 引言
丝绸贸易开辟了古代中国与西域国家的贸易之路,使得中国文化得以广泛传播。丝绸是丝绸图案的主要载体,丝绸图案的风格与题材随年代发展不尽相同,深刻的反映了当时的人文风俗。把目标检测技术用于丝绸研究具有十分深远的历史意义。
目前,丝绸研究人员对丝绸图案的年代和类别的研究主要依赖人眼识别,分类结果往往取决于个人经验。使得丝绸图案研究工作效率偏低,研究结果往往富有主观性而且缺乏一致性。计算机视觉技术日益先进,目标检测技术在文物识别方面有了广泛的应用,但是目标检测在丝绸图案上的应用并不多见,因此对于丝绸目标检测技术的研究十分必要。
主流的目标检测算法可以分为两种类型:1) 基于候选框的两阶段目标检测算法 [1] [2] [3];2) 基于anchor的单阶段目标检测算法 [4] [5] [6]。并且经过各种改进这两种算法在PASCAL VOC、MS COCO等公共数据集上的效果不分伯仲。然而简单得将这两类深度学习算法应用到古代丝绸图案检测上并不能达到理想的效果,其中最主要的原因在于,丝绸数据种类多数量少的特点,经过多轮迭代训练不能得出具有泛化性能的模型。
针对小样本问题,人们希望模型能具有人类的学习能力,只需通过简单的学习就能分辨出不同的事物。学者们纷纷从各个角度提出不同的解决方案。基于微调的迁移学习方法 [7],研究认为直接在小样本空间上的模型缺少泛化性,提出迁移学习策略。首先让模型在分布相似的大数据集上进行粗略的学习,初始化目标域的相关参数,然后固定住底层网络参数,让具有初始化参数的模型在目标域上继续学习目标域独有的特征,但是这种方法会忽略源域和目标域的重要目标知识,降低模型的可传递性 [8]。基于度量学习 [9] [10] [11] 的方法在孪生网络的基础上进行改进,首先基于网络共享提取查询图像和目标图像的特征,然后将该特征作为可学习度量网络的输入,网络输出查询图像和目标图像相似度作为分类结果。但是基于度量学习的模型只适用于单个目标的输入,缺乏普适性。基于元学习的目标检测算法 [12] 提出将元学习方法应用在传统的目标检测上,通过元学习的策略学习一个具有普适性的目标检测模型,该模型能快速从少量数据中学习数据的分布。Meta R-CNN [13] [14] 等提出基于Faster R-CNN增加了类注意力机制,类注意模块与Faster R-CNN共享特征提取层,从Support集中提取类别信息作为Faster R-CNN分类器的指导信息,提高模型的准确率。
中国古代丝绸上的图案以有序为美,同样的图案会重复出现,并且有大小变换。当Support集中的图案尺寸与Query集中的尺寸有较大差别时,基于元学习的目标检测算法效果有明显下降的趋势。针对该问题本文在Meta R-CNN基础上提出多尺度类注意力改进算法。在注意力网络中采用金字塔结构输出不同尺度的类注意力特征图,再由原型网络针对每一个类别提取类向量,分别与Faster R-CNN中不同尺度的特征图进行匹配,尽可能找出各种尺度目标物候选框,提高检测效果。
2. 相关方法
2.1. Faster R-CNN
Faster R-CNN [2] 是典型的两阶段目标检测算法在准确率方面保持着一定的优势,因此,本文将Faster R-CNN框架作为小样本目标检测的底层框架。Faster R-CNN的网络结构如图1所示。Faster R-CNN主要包括:1) 特征提取网络:提取输入图像的特征的高维特征表示最为后续网络的特征输入。目前主流的用于特征提取的网络有ResNet [15],MobileNet [16],VGG [17] 等。2) RPN (Region Proposal Network)网络,该网络将(1)中的特征图作为输入,生成一系列不同尺寸的候选框
,其中每一个候选框都含有一个目标物或者背景。3) ROI (Region of Interest, ROI)层,RPN网络生成的候选框因目标本身尺寸有所不同,这不利于后续网络对候选框进行分类运算。ROI层计算出每一个候选框的特征图,然后经过池化操作统一特征图尺度,这些特征图作为检测和分类网络的输入。4) 分类与回归网络,该网络计算出每一个候选框的类别概率,并利用边界框回归对候选框偏移量进行估计,修正边界框的位置。
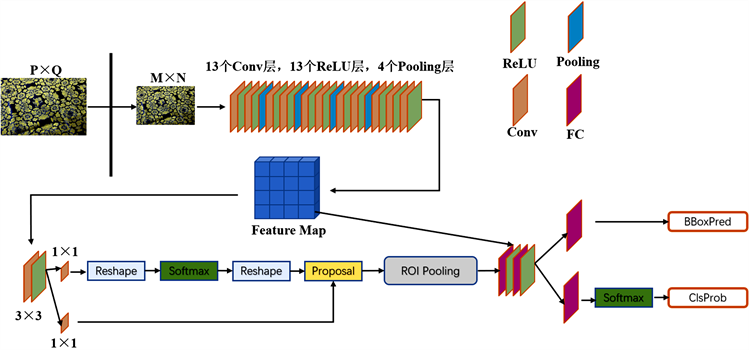
Figure 1. Framework of faster R-CNN model
图1. Faster R-CNN网络结构
尽管Faster R-CNN在目标检测方面有较好的表现能力,但是Faster R-CNN模型训练非常依赖大量标定好的数据,Faster R-CNN模型不能很好的解决小样本中的检测问题。面对训练数据不足的情况,大多数基于深度学习的模型都会产生严重的过拟合现象。
2.2. 元学习
元学习也叫“学会学习”,元学习以任务为学习单位,通过学习不同任务的共性,增强模型的泛化能力,使模型在缺少训练数据的情况下依然具有较好的表现力 [18]。元学习不是简单地学习一个从输入空间到输出空间的映射模型,而是希望模型通过对每一项历史任务的学习和经验积累,从而面对新任务时可以更加容易,所需要的训练样本更少,同时还能保证一定的算法精度。以任务为学习单位的元学习模型能够从不同的任务中获得有用的经验,模型更多的关注自身的学习能力,然后将这种学习能力抽象成函数
若出现新的任务,模型
利用极少量样本继续学习新任务的中的信息,从而快速适应和掌握新任务,也就是抽象出对应任务
的函数模型
。Meta Learning的结构如图2所示。现阶段,元学习方法在模式识别中使用较为广泛,但是将元学习用于目标检测的研究并不常见,主要因为目标检测任务相对于模式识别,图像分类等任务更为复杂,目标检测背景更为复杂,图像中多个目标于背景相互交叉重叠,对模型的要求更高。
2.3. Meta R-CNN
Meta R-CNN将元学习策略应用在目标检测框架上,结合Faster R-CNN框架,实现小样本目标检测任务。Meta R-CNN的目的是学习一个能快速适应小样本数据集的模型。Meta R-CNN采用标准元学习的学习策略,以多个小样本目标检测任务作为训练样本,把快速对仅有少量新类样本的数据集实现检测任务作为训练目标。
对于K-way N-shot问题,在元学习范式中,每一个任务共有K个类别,每个类别有N个样本,元学习把这
样本作为支撑集
,其中支撑集中的样本都具有实例级标签,然后针对其中部分类别随机抽取一个样本作为查询集
,其中
。Meta R-CNN利用原型网络从
学习每一个类别的先验知识
。在Meta R-CNN模型中原型网络和Faster R-CNN的特征提取网络实现参数共享。
(1)
其中,
表示
中第k个类别的原型特征,
表示第k个类别中第i个样本的区域特征。查询集样本通过共享的特征网络生成查询样本的特征
,然后与支撑集中的每一个原型特征向量
进行卷积,生成新的特征图
。
(2)
将
特征图作为Faster R-CNN网络的输入,
特征图融合了类别信息,所以Faster R-CNN网络在生成区域候选框的过程中更加关注具有类别特征的区域,于原始Faster R-CNN网络相比,Meta R-CNN中的候选框更有针对性,大大降低区域候选框的数量。
但是,在本文中的丝绸图案检测中,Meta R-CNN网络的效果并不理想,主要因为古代丝绸图案的表现形式,同一种图案会以不同的尺寸重复出现,当Support中的图案与Query中的图案尺寸相差较大时,模型的识别能力明显下降。本文针对该问题提出了模型改进。
3. 方法改进
针对Meta R-CNN网络在小样本目标检测中对不同尺度目标检测效果不佳问题,本文提出多尺度类注意力模块,使用原型网络融合多种尺度的类别特征,从而Faster R-CNN能获得更多的类别信息,提高目标检测准确率。改进后的小样本目标检测框架如图3所示。小样本目标检测主要分为两个部分:1) 原型网络,本文利用原型网络完成多尺度类注意力提取。2) Faster R-CNN网络,Faster R-CNN网络对融合类别信息特征图实现目标检测。
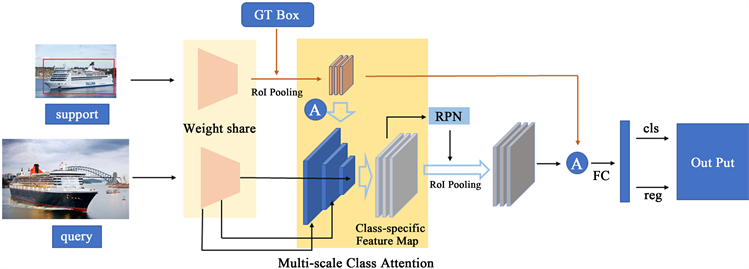
Figure 3. Framework of multi-scale class attention object detection
图3. 多尺度类注意力目标检测结构
多尺度类注意力向量
本文对支持集样本的多个尺度进行实例级特征提取,使原型网络提取的类注意力信息融合多个尺度的类别特征提高Faster R-CNN识别精度。考虑到GPU的算力问题,本文使用三种尺度的特征提取。提取实例级注意力特征的网络结构如图4所示,特征提取网络与Faster R-CNN的特征提取网络参数共享,原型网络针对每个类别的多制度特征生成对应的类注意力向量。特征提取的过程先自上而下特征图尺寸依次缩小1/4,尺寸越小,特征图获取的高维信息就越丰富,较大尺寸的特征图局部特征更丰富。然后做自低向上依次上采样,考虑到位置信息损失,上采样的过程中融合相同尺寸的左侧特征。最后将融合高维语义信息特征和浅层局部信息的类别特征作为原型网络的输入,生成类别注意力特征。
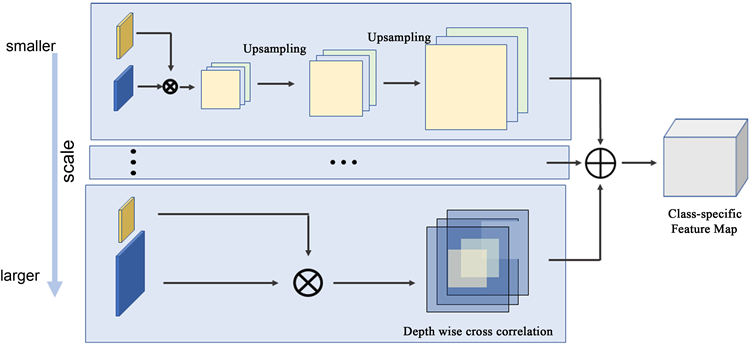
Figure 4. Module of multi-scale class attention
图4. 多尺度类注意力生成模块
4. 实验及结果分析
4.1. 数据集
为验证本文提出算法的正确性和可靠性,本文在融合东华大学丝绸数据集的Pascal VOC2007上进行4-way 5-shot和4-way 20-shot的实验。东华大学丝绸数据集由东华大学服装学院提供古代丝绸仿制织物,东华大学信息科学技术学院进行图像级样本采集,并且进行实例级样本标注,该数据集包含4个类别,共有4000多张彩色图片。示例图如图5。本文中实验数据集共包含24个类别,其中20类数据属于Pascal VOC2007数据集,6个类别数据东华大学丝绸数据集。实验数据划分情况见表1。
 (a) Lion1
(a) Lion1  (b) Lion2
(b) Lion2  (c) Lion3
(c) Lion3  (d) Flower
(d) Flower
Figure 5. Examples of lions and flowers in silk dataset
图5. 丝绸狮子和花卉图案示例
4.2. 实验环境
实验环境配置如下:Intel Xeon W-2150B处理器,内存32GB,Nvidia GeForce RTX 2080ti显卡,Ubuntu18.04操作系统。所有程序均基于开源Pytorch框架设计,并使用GPU加速计算。在所有实验中,使用初始学习率为的Adam算法进行训练,每3000次迭代学习率减半。
4.3. 实验结果与分析
基于4.1节中的数据集,本文所提方法与YOLO-Few-shot [11]、Meta R-CNN [13] [14] 等算法进行对比试验。实验采用4-way 5-shot和4-way 20-shot两种类型的对比。在4-way 5-shot实验过程中,本文将采集到的丝绸数据集的三种不同年代的狮子和一种花卉作为元测试数据集,最终希望模型能够在对比实验结果如表2所示。试验结果表明,与其他小样本目标检测算法相比,本文提出的方法在丝绸数据上优于其他算法,在PASCAL中原有的类别的检测效果也有一定的准确率提升,说明本文方法优化了Meta R-CNN模型的效果。

Table 2. Resulting data of experiment
表2. 试验结果数据
5. 结论
东华大学服装学院的丝绸图案数据集检测问题,目前为止,没有人员提出关于丝绸图案的数据集,所以基于一般CNN网络的目标检测算法在东华大学服装学院的丝绸图案检测中都会存在过拟合问题,本文提出多尺度类注意力目标检测方法,利用元学习的训练策略,训练一个能快速学习小样本数据集的Faster R-CNN模型。并且基于原型网络提出多尺度类注意力模块,多尺度类注意力融合多个尺度的特征信息,为Faster R-CNN的候选框生成提供了更丰富的类别信息,指导RPN网络生成更多与类别相关的候选框,减少冗余信息。Faster R-CNN在后续分类过程中也融合了原型类注意力特征,使模型更关注同类别的信息,提升识别率。
我们利用Pascal VOC2007作为训练集,检验模型在丝绸图案数据集上的检测能力,根据表2中的数据集可知,当模型在Baseclass中具有相当水平时,本文提出的方法在新类的识别上效果最为明显,说明本文提出的方法具有一定的效果。