1. 引言
随着互联网的快速发展,在线知识付费产业应运而生,并得到了越来越多人的关注和青睐。目前国内关于知识付费平台的研究较多,但主要以分析商业运营模式和通过平台数据定性研究为主,如国内学者郭高添 [1] 与李雨洁 [2] 分别定性分析了知识付费市场的供需和用户特征行为的问题,李慢 [3] 使用问卷调查和描述性统计等方法研究了信号理论与顾客付费意愿的关系,吕沅羲 [4] 使用方差分析和线性回归分析等方法研究了知识产品付费意愿的影响因素。而国外对知识付费产品的研究大多集中于对平台安全性和产品定价的研究,如Hsieh [5] 研究指出提问者愿意在难度更高的问题上支付更高昂的费用等。本文基于知识付费平台“得到APP”,从音频信息、文本信息、价格以及热度四个维度的指标,使用带惩罚项的泊松回归模型,定量分析影响用户付费意愿的因素。本文旨在为知识付费平台提高竞争力提供有数据支撑的科学建议,提高用户服务质量,推动在线知识付费产业的长远健康发展。
2. 研究设计
为研究影响消费者知识付费意愿的影响因素,首先建立指标体系,使用爬虫抓取数据信息。使用jieba分词等方法进行文本预处理,基于惩罚项的泊松回归对各变量的影响因素进行分析。本文的研究流程图见图1。
3. 模型介绍
泊松回归是针对计数数据的一种回归分析,其模型形式为 [6] :
(1)
其中
为因变量的预测值向量,
为回归方程回归系数,
为自变量矩阵,p为变量的总个数,n为样本量,
为随机误差。
本文采用基于惩罚的的泊松回归模型研究影响影响因素,下面分别对惩罚函数及选择参数的交叉验证的原理进行介绍。
3.1. 惩罚函数
1) 基于L1惩罚 [7] 的泊松回归:
LASSO (Least Absolute Shrinkage and Selection Operator)是一种同时进行变量选择和参数估计的方法,模型中加入了L1正则化项,对回归系数的L1范数进行惩罚,可以对系数连续压缩。惩罚函数L1形式及惩罚系数估计如下式:
(2)
(3)
其中
为因变量的实际值向量。调整参数
越大,回归系数的压缩越大,甚至压缩为0,从而实现变量选择和影响因素分析。
2) 基于MCP惩罚的泊松回归:
MCP (Minimax Concave Penalty)惩罚 [8] 方法解决了近似无偏估计和如何找到凹度最小的惩罚的计算困难问题。采用坐标下降算法来获得目标函数的最小值。它的惩罚函数为:
(其中
且
) (4)
其惩罚系数估计如下式:
(5)
3.2. k折交叉验证
k折交叉验证 [9] 将原始数据随机分成k份(k值的选择根据数据调节),不重复地选取其中一份做测试集,用剩余
份做训练集训练模型,进而计算该模型在此测试集上的均方误差
(Mean Squared Error),其中i是测试集的编号,
。对于每一个测试集,均方误差的计算公式为:
. (6)
其中
表示模型中
的预测值,
为第i份数据的样本量。将k次
取平均,衡量回归的测试误差作为最终模型的评价指标
(Cross-Validation),其表达式如下:
. (7)
该方法的核心思想在于对数据集进行多次划分,对多次评估的结果取平均,从而消除单次划分时数据划分不平衡造成的不良影响,它可以有效避免过拟合和欠拟合状态的发生。k折交叉验证的流程图见图2:
Figure 2. Flowchart of Poisson regression with penalty function
图2. 带惩罚项的泊松回归流程图
4. 模型建立
4.1. 指标选取与样本整合
为研究影响消费者知识付费意愿的因素,本文选取“得到APP”作为知识付费平台的代表样例进行研究,对其进行信息抓取并结合研究内容进行变量筛选。
4.1.1. 变量选取
为研究消费者知识付费意愿的影响因素,从“得到APP”中选取对购买意愿可能存在影响的各因素作为自变量。具体的因变量和自变量如下表1所示:
本文研究的因变量为购买人数,并将自变量归纳为音频信息、文本信息、价格、热度四个维度进行考虑。本文借助爬虫从“得到”网页版获取得到近三百门课程的有效信息。

Table 1. The description of response variable and covariates
表1. 因变量、自变量及其说明
4.1.2. 样本整合
“得到”网页版将课程分为20类课程,为了更好地研究不同类别课程对购买者付费意愿的影响程度,本文将性质相近的课程进行整合,最终归纳为6大类课程,既保证了课程分类的条理性,也保证了各课程类别中的样本数量充足。课程的原始分类及整理后的类别如下表2所示:
Table 2. Classification of courses and the size of samples
表2. 课程分类及信息量
下文分析均基于上表六大分区展开。
4.1.3. 数据描述
六个分区课程购买人数的平均值分别为56,425、71,207、49,259、44,009、76,060、106,250人,最小值为6255 (“社会政治与哲学法律”分区),最大值为545,682 (“经济与商业”分区)。依据数据做出六个分区课程购买人数分布的箱线图(见下图3),并以“人际关系与自我提升”分区为例,做出购买人数分布图(见下图4)。从图3中发现数据分布较为集中,每个分区均有少量离群点数据远大于平均值。
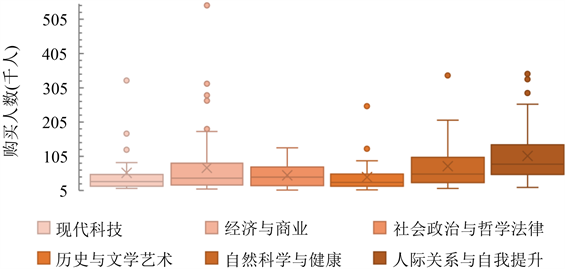
Figure 3. Boxplot of courses’ purchasers
图3. 课程购买人数分布箱线图

Figure 4. Distribution of purchasers in “relationship and self-improvement”
图4. “人际关系与自我提升”分区购买人数分布图
4.2. 文本挖掘
考虑到样本同时包含数值型数据和文本信息,首先对文本信息进行数值化处理,以便后续研究。
4.2.1. 标题语气与标题长度
本文所指标题语气即标题是否为提问式标题。若标题中存在问号或“吗”、“为什么”、“如何”等提问信号词,则将其判定为提问式标题,并选取0-1模型进行表示。
同时,统计课程标题的字数,将标题长度转换为数值。
4.2.2. 基于jieba算法的高频词提取
本文选取各分区课程亮点/发刊词中出现频次最高的三个词作为该分区高频词。首先使用jieba算法,对文本信息进行分词,并在获取停用词词库“哈工大停用词表”的基础上去停词,最终获得不含停用词的分词文件。下表3展示了对词语进行词频统计后得到的各分区课程亮点/发刊词中前三个高频词。
4.3. 回归模型建立
通过前文对文本信息的挖掘与处理,将得到的各分区数值型数据及赋予的变量名列于下表4中。
Table 3. Extraction of high-frequency words from courses’ highlights and publication words and their frequency statistics
表3. 课程亮点及发刊词的高频词提取及词频统计
Table 4. Integrated numerical variables based on text mining
表4. 文本挖掘后整合所得的数值型变量
其中i表示分区标号。
5. 研究结果与分析
5.1. 模型结果
在进行带惩罚的泊松回归时,由于试听人数变量影响的显著程度远大于剩余变量,且剩余变量受其影响大多被压缩为0,考虑到本文研究目的为探究各因素的影响大小,因此为了更有效得分析系数,先将试听人数视为影响最显著的变量并将其剔除,再对剩余变量进行第二次泊松回归。各分区进行泊松回归过程中所带惩罚函数及对应的交叉验证折数如下表5所示。
Table 5. Penalty functions and cross-validation folds used in Poisson regression
表5. 泊松回归对应的惩罚函数及交叉验证折数
回归复杂度调整的程度由参数控制,不同的
对应不同的模型。本文使用k折交叉验证误差最小原则进行模型的选择,下图展示了第三个分区回归所得的不同
对应模型的误差图,见图5。
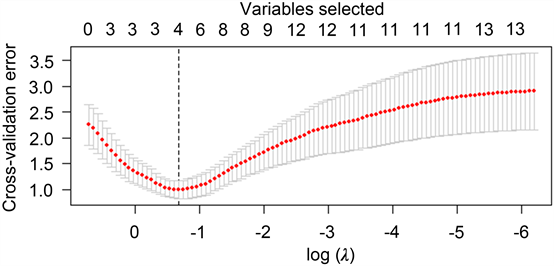
Figure 5. Profiles of cross-validation error as the tuning parameter
varied
图5.
-交叉验证误差关系图
根据CV值自动选择最优模型,将回归结果进行整理,得到各分区最终的回归表达式如下:
由上式即可得到各分区对购买意愿的影响模型,下文基于此展开分析讨论。
5.2. 研究结果分析
依据该回归模型,本文依据表4中四个变量维度的顺序依次探究其对知识付费意愿的影响。
1) 音频信息的影响分析:
在音频信息的三个因素中,总讲数与单讲时长的系数均除了一个分区外都被压缩为0,而发布时间点的系数均为正数且在同分区内的绝对值较大。说明总讲数与单讲时长对购买意愿的影响微乎其微,相反发布时间则为促进购买量的重要因素。此外,总讲数对“社会政治与哲学法律”分区产生了正向影响,而单讲时长对“现代科技”分区产生了负向影响,说明对两个分区可以分别适当增加总讲数和缩短单讲时长。
2) 文本信息的影响分析:
观察变量系数发现,标题形式和标题长度仅对个别分区产生显著作用。标题长度变量仅在“经济与商业”分区中产生显著作用,系数为0.034,其绝对值相比同分区其他自变量相对较小。同时,标题形式变量仅在“现代科技”分区中产生显著作用,系数为0.032,说明此分区中,提问式标题会更加引人注目,标题的提问常常与知识购买者的疑问契合度更高,从而提高消费者的认可度。但对比同分区其他自变量,该变量系数的绝对值同样相对较小。
考虑到各分区关键词不同,故对六个分区分别分析如下。对“现代科技”、“经济与商业”、“社会政治与哲学法律”、“历史与文学艺术”分区,正向作用最显著的关键词分别为“世界”、“公司”、“世界”、“中国”。这些词与分区的关联度都很高,与本文得出的有显著正向影响的结论相吻合。而“人际关系与自我提升”分区中所有与词语相关的变量前系数均被压缩为0。在“自然科学与健康”分区中“科学”一词的系数为负,因此本文认为,需要区别“高频词”与“关键词”的概念,分区筛选出的出现频率高的词不一定就是该分区的“关键词”,也可对购买量产生负向影响。进一步,本文将对购买量产生显著正向影响的词语作为该分区的关键词,得到六个分区的关键词分别见下表6:
Table 6. Keywords selected based on text mining
表6. 各分区筛选所得关键词
3) 价格的影响分析:
价格这一因素的系数在大多数分区都被压缩为0,价格因素对购买意愿的影响总体来说不显著,说明“得到APP”大部分课程的定价较为合理,基本处于消费者的可接受范围内。仅有“现代科技”分区和“经济与商业”分区的价格因素有非零系数−0.020和0.142,分别对购买量产生了轻微的负向和正向影响,说明“现代科技”分区的定价略高于购买者预期,而“经济与商业”分区的定价非常优惠合理且性价比较高,因此购买者对其价格的接受度极高,说明合理的定价可以有效拉动购买意愿。
4) 热度的影响分析:
课程热度对消费者知识付费意愿的影响在所有因素中最大,效果十分显著。试听人数作为最显著的正向影响变量,说明试听人数对消费者的购买量起到了最关键的作用。本文结合“得到APP”的运营方式,尝试对这一现象做出解释。由于“得到APP”会在每日更新且受众面最广的首页免费音频中对某些课程进行推广并播放部分课程片段吸引消费者,因此不仅大大提高了该门课程的知名度,使购买者对其耳熟能详,更是对该门课程进行了直接的引流,大大提高了该课程的试听人数,进而助推购买量增长。
同时,授课者粉丝数的系数除一个分区被压缩为零外,其余各分区均为正数且绝对值与同分区其他变量前系数相比较大。说明授课者粉丝越多,消费者对其课程质量的信赖程度越高,从而有效激发了消费者对该课程的购买意愿。
6. 结语
本文选取“得到APP”作为知识付费平台的代表样例进行研究,通过带惩罚项的泊松回归观察得各变量对消费者知识付费意愿的影响程度。基于上述研究得到以下结论:1) 总讲数、单讲时长、标题长度、标题形式以及价格仅对个别分区产生显著影响,总体上作用不显著;2) 发布时间、试听人数和粉丝数对各分区消费者购买意愿的影响都较为显著,其中试听人数最为关键;3) “高频词”不等于“关键词”,进而筛选出各分区对购买意愿产生较大影响的“关键词”。
基于上述结论,本文为以“得到APP”为代表的知识付费平台提出以下建议,从而使其提高竞争力,促使线上知识付费产业的长远健康发展。建议概括如下:1) 音频信息层面,总体上保持课程总讲数和单讲时长现状,加强对新课程的推广,同时通过定期引流、经典回顾专栏等方式兼顾对经典课程的宣传;2) 文本信息层面,除了为受标题形式和长度影响显著的课程选择有利的标题形式与长度外,可进一步围绕上文提出的各分区关键词打造相关课程;3) 课程价格层面,考虑到合理的定价可以大大促进购买意愿,因此建议保持当前相对合理的定价水平,同时适当调整定价偏高分区的价格,并通过优惠促销活动等拉动购买量;4) 课程热度层面,重视首页推广对课程引流的重要性并优化其推广策略,在推广热门课程的同时,也加强对粉丝数较少但内容优质课程的推广,尽可能避免优质课程资源的浪费。
NOTES
*通讯作者。