1. 引言
目前国内主要采用人工目视法检测蓝膜缺陷,但是这种方式效率低且人工成本高。而随着机器视觉技术的发展,面对单一场景的检测往往可以取得优异的效果,但面对复杂多变的场景时缺乏泛化性 [1]。采用深度学习技术来解决这些局限性是目前比较常用的方法。在电芯工业生产中,正常蓝膜样本数量远远大于有缺陷的异常样本,并且缺陷面积较小。基于深度学习的表面缺陷检测中,缺陷样本少、缺陷小导致无法获得准确的检测结果,通常难以满足工业上的需求,基于无监督学习的异常检测方法通常用来解决此类问题 [2]。
在该领域国内外学者进行了一系列研究,Kang [3] 采用深度去噪编码器,利用其误差重建以此检测绝缘子图像中的缺陷。LSA [4] 在其潜在空间训练自回归模型,而OCGAN [5] 试图强制将异常输入重构为正常输入。基于GAN的方法,如f-AnoGan [6]、GANomaly [7] 在AnoGan [8] 的基础上添加额外的编码器以减少推理时间,在异常检测与定位上表现良好,但在单类缺陷检测上效果还有待提高。以上这些无监督学习方法适用于异常样本少的场景,但是很难同时满足异常检测和精确定位,且模型计算量大、实用性较差。
知识蒸馏采用预先训练的网络作为教师网络,将学习到的特征“蒸馏”到学生网络中,在保证精度的同时减少模型的计算量。Salehi [9] 等提出一种多尺度知识蒸馏方法,通过将一个在ImageNet上预先训练的源网络上的各层知识,提取到一个结构相同但模型尺寸较小的克隆网络上,可以有效利用教师网络中间层信息,表现出良好的异常检测性能。但是该方法缺乏对图像局部信息的关注,因而在针对小目标检测上效果有待提高。
在小目标检测领域,DSSD [10] 采用反卷积技术用于SSD的所有特征图上,目的是得到放大比例的特征图,但是由于是在所有特征图上应用反卷积,增加了模型的复杂度导致速度变慢。
针对以上问题本文提出一种改进多尺度知识蒸馏的方法,采用正常数据训练解决缺陷样本少的问题。通过在多尺度知识蒸馏骨干网络上结合残差注意力模块,使网络聚焦图像中的局部信息,提高对于小目标的检测准确性,解决小目标缺陷检测精度差、定位难的问题。相较于传统缺陷异常检测,本文的方法更容易捕获小的图像细节,获得精确的异常定位结果。
2. 数据准备和预处理
锂电池电芯出厂时会包裹一层蓝膜,可以起到对电芯的保护作用。本文电芯蓝膜图像通过工业线扫平台以及工业线扫相机对电芯扫描得出,实验室环境下蓝膜图像数据采集装置示意图如图1所示,工业现场扫描得到的原始图像大小为4000 × 18,000。由于图片过大影响模型正常学习,而且蓝膜表面缺陷面积相对于整张图像非常小,因此将其切割成1024 × 1024大小的图像。

Figure 1. Sketch map of blue membrane image data acquisition device
图1. 蓝膜图像数据采集装置示意图
在生产过程部分蓝膜中会由于外力作用产生破损(a)或者粘附异物(b)如图2所示,其中异物以白色异物居多,少量的黑色异物以及其他颜色异物,在3.2实验分析一节中给出了不同缺陷的定位效果图。缺陷会极大影响蓝膜质量导致电芯出现安全问题,有必要对蓝膜图像进行缺陷检测,本文采用异常检测的方法识别有缺陷的蓝膜样本,因此将含有缺陷的蓝膜图像统一视为异常样本。
蓝膜数据集包含训练集与测试集,训练集全部是没有缺陷的正常样本。实验结果通过梯度图可视化的方式进行展示。由于训练样本是正常图像数据,因此只需对含有缺陷的测试集进行标注,标注方法与图像分割相同,标签类型为缺陷,采用的标注工具为海康深度学习软件VisionTrain1.4.1。训练集有600张正常图像,测试集有205张图像,包含55张正常图像,150张异常图像。
3. 改进的多尺度知识蒸馏
知识蒸馏是一种模型压缩的方法,通过构建一个轻量化的小型网络,利用性能更好的大模型的监督信息,来训练这个小模型,在降低计算成本的情况下,能达到更好的性能和精度,蒸馏得到的小模型在实际生活中更易于部署到算力受限的终端。在新能源电芯工业生产车间里由于环境限制,蓝膜缺陷检测设备通常难以具备较大的计算能力,因此知识蒸馏方法较为适用。
电芯蓝膜图像颜色表现为单一的蓝色,背景像素统一无其他明显特征。基于多尺度知识蒸馏的异常检测方法在处理这类问题时表现出较好的效果。但是蓝膜图像中具有一部分尺寸细小的缺陷,而多尺度知识蒸馏方法缺乏对图像局部信息的关注,采用此方法处理小目标缺陷时往往检测率不高。因此考虑在该方法基础上进行改进,以适应蓝膜缺陷检测的需求。本文通过在骨干网络上添加残差注意力机制增加网络对局部信息关注度,以此提高小目标缺陷检测效果。
3.1. 多尺度知识蒸馏
多尺度知识蒸馏网络结构主要包括源网络S与克隆网络C两部分。通过训练一个较小的克隆网络模仿源网络在正常数据上的整个行为,根据在训练中看到的正常样本,识别出对模型来说新颖的测试时输入。由于克隆网络需要从正常数据的特征中预测样本的偏差,所以需要对正常数据特征极为了解,训练时输入的训练集只包含正常数据,目的是训练一个克隆网络C用于检测测试集中的异常图像。两个网络间行为的差异由一个总损失函数来表示。源网络采用VGG-16在一个大的自然数据集ImageNet上预训练而来,克隆网络C与源网络S采用一样的结构,但模型尺寸较小,实验表明选择较小的克隆网络能有效提高网络性能 [11]。
知识蒸馏为了节省计算成本致力于将知识从一个网络转移到另一个较小网络。但是多数知识蒸馏仅仅把S的最后输出传给C,这样做会丢失很多中间信息。由于神经网络各层对应着不同的抽象信息,所以仅把最后一层输出传给C,只包含一部分信息。基于此,采用一种多尺度知识蒸馏方法,在网络几个关键层之后计算S与C的loss能传授给克隆网络更全面的信息。将知识视为激活函数的值,在本文中将知识定义为关键层激活值
的距离
和方向
,
表示网络的第i个关键层。克隆网络C的激活值用
表示,所以损失函数有两个,距离损失为:
(1)
表示关键层
的神经元数量,
表示关键层
的第j个激活值。但是单一的距离损失难以完整表达向量间的相似性,因此采用余弦相似度作为方向损失
进行补充:
(2)
其中
表示任意维矩阵x变换成一维向量的函数,总损失
:
(3)
设置
比例因子以调节两部分损失达到比例相同,训练时使用
作为完全收敛标准。
3.2. 改进的多尺度知识蒸馏网络结构
Wang [12] 等研究表明注意力机制可以让网络聚焦于图像中的一部分。为了提高小目标检测率,在VGG骨干网络上,额外添加注意力机制以创建不同分辨率的特征映射。本文将单阶段残差注意力模块置于第2层conv2_2以及第7层conv7_3之后。每个残差注意模块结构由主干与掩码两个分支组成,主干分支由两个残差块组成,残差块包含3个卷积层。掩码分支经过一个上下采样与残差连接后输出注意特征图,经sigmoid函数激活然后乘以主干分支的输出,得出被注意特征图。最后经过残差块、relu激活函数之后与克隆网络对应层的输出计算损失,改进前后网络结构对比示意图如图3所示。
4. 实验结果及分析
4.1. 评价指标
在本文中,评价指标采用AUROC曲线来反映模型的学习效果,该曲线能够表现出模型的预测结果中正误的变化关系。曲线纵轴为真正类率(true postive rate, TPR),
(4)
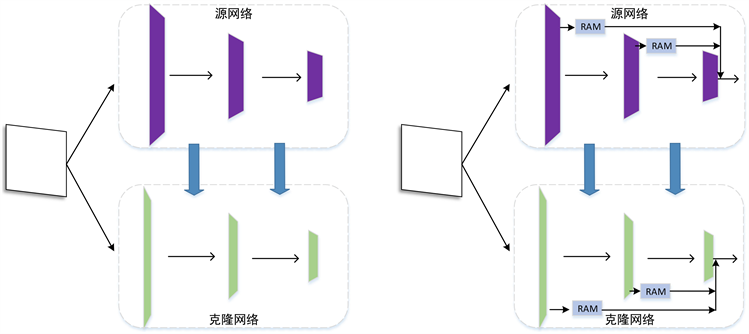
Figure 3. Improved multiresolution knowledge distillation structural comparison diagram
图3. 改进多尺度知识蒸馏结构对比图
表示模型预测结果的正样本中实际正样本占所有正样本的比例。TPR的值越大,说明预测的正样本中实际的正样本越多。TP表示预测正确的正样本,FN表示正样本被预测为负样本。曲线横轴为假正类率(false postive rate FPR),
(5)
表示模型预测的正样本中实际负样本占所有负样本的比例。FPR的值越大,说明预测的正样本中实际的负样本越多。FP表示负样本被预测成正样本,TN表示正确预测的负样本。
4.2. 实验结果与分析
实验环境:Win10操作系统,处理器为Intel(R) Core(TM) i5-11400H @2.70GHz,显卡是NVIDIA GTX 3080。采用Pytorch框架实现算法搭建,训练epoch为600,学习率0.001,损失函数权重因子λ设置为0.5。在训练过程中每10个epoch之后用验证集测试训练效果,以此验证模型学习效果,在经过600个epoch后,训练loss值接近为零且趋于稳定状态。
本文在蓝膜数据集上与现有的几种方法LSA、AnoGAN、VAE-grad、GT、CNN-Dict、MKD,包括自监督、生成对抗网络、基于自编码器方法、基于多尺度知识蒸馏等进行了比较,在公开数据集MVTecAD上选取了五种与蓝膜图像纹理相似的种类,包括Capsule、Carpet、Hazelnut、Wood、Leather,最终的检测结果如表1与图4所示,缺陷定位效果如图5、图6所示。

Table 1. Detection AUROC (%) on datasets of blue membrane and MVTecAD
表1. 在蓝膜以及MVTecAD数据集上的检测AUROC(%)

Figure 4. Auroc curve of detection on blue membrane dataset
图4. 蓝膜数据集上检测AUROC曲线图
如图5所示是公开数据集MVTecAD中五个种类缺陷的异常定位测试效果图,图6是蓝膜缺陷图的单张定位测试效果图,用梯度图可视化的方式显示缺陷定位。其中Wood、Carpet、Leather相比其它两类与蓝膜纹理更为相似,因此检测效果更好,对于小目标缺陷的检测也更准确;而Capsule与Hazelnut的异常检测效果相对有待提高。所以本文方法对于图像背景像素单一、缺陷目标小场景下的异常检测更为适用。

Figure 5. MVTecAD defect location rendering
图5. MVTecAD缺陷定位效果图

Figure 6. Blue membrane defect detection results
图6. 蓝膜缺陷检测结果图
本文提出的在知识蒸馏骨干网络上添加残差注意力机制的方法,能够有效弥补传统知识蒸馏在检测小缺陷方面的不足,在蓝膜Small数据集上检测准确率较MKD方法提高了3.91%,在其他场景的缺陷检测上准确率也有提高。而采用多尺度知识蒸馏方法进行训练,在节省资源的同时也让缺陷定位更为准确,因此无论是在异常检测任务上还是在异常定位任务上,在蓝膜数据集与公开数据集上本文提出的方法均表现出较好效果。
5. 总结
为了解决工业生产中电芯表面蓝膜缺陷样本量少导致模型拟合难度大、缺陷目标小导致检测精度差、定位难的问题,本文提出一种改进多尺度知识蒸馏的方法。在多尺度知识蒸馏骨干网络上结合残差注意力模块,使网络聚焦图像中的局部信息,提高对于小目标的检测准确性。采用无缺陷的正常数据进行训练,有缺陷的异常数据进行测试,在公开数据集MVTecAD和电芯蓝膜缺陷数据集上进行了异常检测以及异常定位实验。实验结果表明本文方法在处理缺陷背景呈相似像素的图像以及检测小目标缺陷方面的良好效果。本文方法的不足之处是面对公开数据集中背景变化较大的图像时,检测精度还有待提高。