1. 引言
古代玻璃是中西方通过丝绸之路进行文化交流的宝贵物证。古代玻璃易受环境的影响而风化,在风化过程中,由于内部元素与环境元素进行大量交换,导致其化学成分比例发生变化,影响对玻璃类别的判断,从而影响对其产地、原料的来源以及制作工艺的考古研究 [1]。因此,对古代玻璃的化学成分分析和类别鉴定具有重要研究意义。
早期研究指出,古代玻璃的成分分析与类别鉴定易受环境的影响。文献 [2] 研究了古代玻璃的化学元素组成;文献 [3] [4] 研究了古代玻璃的化学成分组成。文献 [5] 研究了古代玻璃经历风化后的化学成分衰变。文献 [6] 研究了古代玻璃的类别鉴定。这些研究表明,研究古代玻璃的化学成分分析和类别鉴定是十分必要的。
本文在前人研究的基础上,对高教社杯数学建模C题中提供的实验数据 [1] 进行建模,使用描述性统计分析和卡方检验分析研究玻璃文物样品表面有无风化化学成分含量的统计规律,得到玻璃表面风化与类型的关系;再依据玻璃表面风化与类型的关系的结论,使用系统聚类算法模型研究不同类别玻璃文物样品的化学成分之间的关联关系;最后依据关联关系的结论使用Fisher判别模型,得到玻璃类别鉴定的Fisher判别公式,对未知类别的玻璃文物进行类别鉴定。
2. 玻璃的表面风化与类型的关系
由于实验数据量较大,无法直接得出玻璃的表面风化与类型是否存在相关性。在无明显的相关性时,直接使用卡方检验分析可能会导致结论误差较大,所以先进行玻璃表面有无风化的描述性统计分析来初步确定是否存在相关性,再通过卡方检验分析验证相关性存在并且研究相关性的强弱。
2.1. 数据预处理
实验数据 [1] 给出了这些文物的分类信息和相应的主要成分所占比例。因检测手段等原因可能导致其成分比例的累加和非100%的情况。根据实验要求有效数据是成分比例累加和介于85%~105%之间,为了方便之后数据的使用,首先对数据进行数据预处理。附件表单2 [1] 中15号文物采样点的化学成分比例累加和为79.47,17号文物采样点的化学成分比例累加和为71.89,在之后的计算过程中都去除无效数据15号和17号,未检测到数据的空白处记作0,其余实验数据可以正常使用。
2.2. 描述性统计分析
为了结合玻璃类型,分析文物样品有无风化化学成分含量的统计规律,进而分析出玻璃的表面风化与类型的关系,使用实验数据 [1],划分高钾有无风化和铅钡有无风化进行描述性统计分析,分别求出14种化学成分含量的平均值、标准差、方差、峰度和偏度。在玻璃类型固定的情况下,在某一种化学成分下,比较其在风化和无风化下的成分含量统计规律。
2.2.1. 峰度系数
峰度系数(
)用来反映峰部的尖度程度。若
,说明该分布相比与正态分布顶端更加尖锐或者尾部更加粗;若
,则说明说明该分布相比与正态分布顶端更加平坦或者尾部更加细;若
,说明该分布与标准正态分布顶端尖锐程度和尾部粗细程度相当。所以峰度可以作为衡量偏离正态分布形状的尺度 [7]。峰度的计算公式:
其中,E(X)为均值,Var(X)为方差,vn表示n阶中心矩。
2.2.2. 偏度系数
偏度系数(
)常用于衡量样本数据分布偏离对称性的程度。若
,则认为处于均值右边的数据偏多;若
,则认为处于均值左边的数据较多;当
接近与0时,认为样本数据是对称分布的 [8]。偏度的计算公式:
其中,E(X)为均值,Var(X)为方差,vn表示n阶中心矩。
2.2.3. 描述性统计分析求解
利用SPSS分别求解高钾玻璃和铅钡玻璃表面有无风化化学成分含量的统计规律。
由表1知,在高钾玻璃条件下,通过分析14种化学成分含量的平均值、标准差、方差、峰度和偏度,我们发现:二氧化硅在风化的情况下含量更高;五氧化二磷、氧化钾、氧化铜、氧化铁、氧化钙、氧化镁和氧化铝在无风化的情况下含量更高;二氧化硫、氧化锡和氧化钠在分化的情况下不存在,在无风化的情况下,存在含量也较少;氧化锶、氧化钡和氧化铅在两种情况下含量都较小,而且含量变化不明显。

Table 1. The statistics of high potassium glass surface weathering chemical composition content
表1. 高钾玻璃表面有无风化化学成分含量的统计
由表2知,在铅钡玻璃条件下,通过分析14种化学成分含量的平均值、标准差、方差、峰度和偏度,可知,五氧化二磷、氧化铜、氧化钡、氧化铅和氧化钙在风化的情况下含量更高;二氧化硅、二氧化硫、氧化钠和氧化铝在无风化的情况下含量更高;氧化锶、氧化锡、氧化钾、氧化铁和氧化镁在两种情况下含量都较小,而且含量变化不明显。
Table 2. The statistics of lead barium glass surface weathering chemical composition content
表2. 铅钡玻璃表面有无风化化学成分含量的统计
筛选出铅钡玻璃和高钾玻璃风化前后相对重要的化学成分,利用Matlab分析其频率分布直方图。
由图1可以看出高钾玻璃在风化后主要化学成分含量呈下降趋势;铅钡类玻璃在风化后主要化学成分含量呈上升趋势。
通过玻璃表面有无风化化学成分的统计规律的描述性分析和不同玻璃类型在风化前后主要化学成风含量的变化分析知,玻璃的表面风化与类型存在一定的相关性。
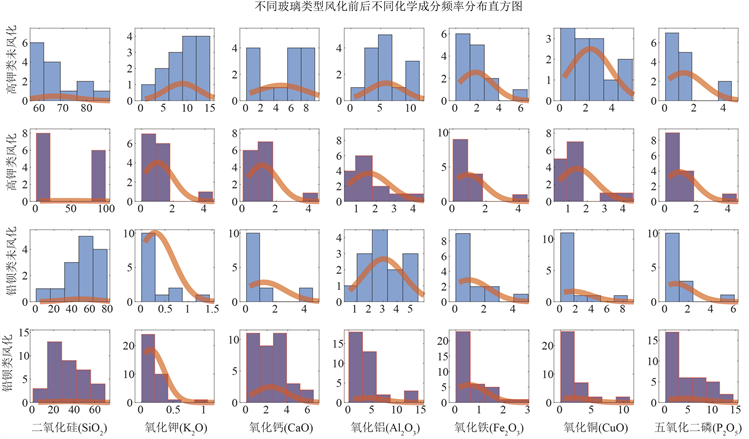
Figure 1. Distribution histograms of chemical composition frequencies before and after weathering for different glass types
图1.不同玻璃类型风化前后化学成分频率分布直方图
2.3. 卡方检验分析
由描述性统计分析和频率分布直方图可以看出,玻璃的表面风化与类型具有相关性,为了进一步研究二者的相关性强弱,对玻璃的表面风化与类型进行卡方检验分析。
2.3.1. 卡方检验
为了对这些玻璃文物的表面风化与其玻璃类型、纹饰和颜色的关系进行分析,由于此时附件表单1 [1] 中的纹饰、类型、颜色和表面风化均为定类变量,所以,表面风化与其玻璃类型、纹饰和颜色的关系分析使用卡方检验。
卡方检验主要是比较定类变量与定类变量之间的差异性分析。通过统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小 [9]。
卡方检验公式:
其中,A代表颜色、类别或纹饰的观察频数,E代表基于假设HO计算出的期望频数,A和E的差称为残差。
提出假设:
H0:表面风化与玻璃类型、纹饰或颜色相互独立不相关。
H1:表面风化与玻璃类型、纹饰或颜色有关联。
2.3.2. 卡方检验求解
使用SPSSPRO软件进行交互分析,得出如下表所示的卡方检验分析结果。模型检验的结果包括数据的频数、卡方值、显著性P值。
变量X:表面风化;变量Y:颜色,类型,纹饰。
表3的结果显示:对于表面风化,颜色的显著性P值为0.268,水平上不呈现显著性,接受原假设;纹饰的显著性P值为0.085* (10%显著性水平),水平上不呈现显著性,接受原假设;类型的显著性P值为0.024** (5%显著性水平),水平上呈现显著性,拒绝原假设。因此,玻璃的表面风化与类型存在相关性且相关性较强。
注:***、**、*分别代表1%、5%、10%的显著性水平。
3. 玻璃文物的化学成风之间的关联关系
由卡方检验分析的结论知,玻璃的表面风化与类型相关,且相关性较强。所以当研究玻璃文物的化学成分之间的关联时,将玻璃文物划分为高钾风化、高钾无风化、铅钡风化和铅钡无风化四大类进行分析时结论更加准确。针对不同类别的玻璃文物样品,为了研究其化学成分之间的关联关系,以及关联关系之间的差异性,采用系统聚类算法模型来分析化学成分之间的关联关系,选择轮廓系数比较分析高钾玻璃与铅钡玻璃之间的化学成分关联关系的差异性。
3.1. 系统聚类算法模型的建立
系统聚类分析的原理是按照距离远近,将距离相近的变量先聚成类,距离较远的变量后聚成类,依次进行,直到每个变量都归入合适的类中 [10]。
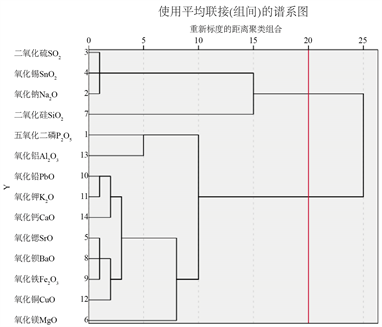
系统聚类过程见图2。
3.2. 系统聚类算法模型的求解
为了得到不同类别玻璃文物的化学成分之间的关联关系,根据系统聚类算法模型的步骤,把高钾风化、高钾无风化、铅钡风化、铅钡无风化四种类别玻璃文物的化学成分数据用SPSS分析,得到四种类别状态下的谱系图。
由图3分析可知,在高钾风化的谱系图3(a)中,化学成分主要分为两类,二氧化硫、氧化钙、氧化纳和二氧化硅分为一类,其他十种化学成分分为第二类;在高钾无风化的谱系图3(b)中,化学成分主要分为三类,二氧化硅和氧化锡分为第一类,氧化纳、氧化铅、氧化钾和氧化钙分为第二类,其他八种化学成分分为第三类;在铅钡风化的谱系图3(c)中,化学成分主要分为四类,氧化铅和氧化锶分为第一类,氧化钡、氧化铜和二氧化硫分为第二类,氧化镁、氧化钙、氧化铁和五氧化二磷分为第三类,其他五种化学成分分为第四类;在铅钡无风化的谱系图3(d)中,化学成分主要分为四类,二氧化硅、氧化铝和氧化镁分为第一类,五氧化二磷分为第二类,二氧化硫、氧化纳、氧化铜和氧化钡分为第三类,其他六种化学成分分为第四类。即高钾风化、高钾无风化、铅钡风化和铅钡无风化的玻璃文物的化学成分的最优分类数目分别为2、3、4、4。
3.3. 玻璃文物的化学成分之间的关联关系的差异性
由系统聚类算法模型的研究知,高钾风化、高钾无风化、铅钡风化和铅钡无风化的玻璃文物的化学成分的最优分类数目分别为2、3、4、4。在系统聚类结果的基础上选择合适的指标进行分类结果差异性的判断,本次选择轮廓系数进行比较分析。
 (a)
(a)  (b)
(b)  (c)
(c)  (d)
(d)
Figure 3. Pedigree map of high potassium glass and lead-barium glass with or without weathering
图3. 高钾玻璃和铅钡玻璃有无风化的谱系图
3.3.1. 轮廓系数
轮廓系数:轮廓系数评价指标说明,轮廓系数的取值在[−1, 1]之间,越趋近于1代表聚类度和分离度都相对较优,即聚类效果越好 [11]。
轮廓系数(si)计算公式:
其中,a(i)表示样本i到同簇其他样本的平均值,称为簇内不相似度;b(i)表示样本i到相邻簇其他样本的平均值,称为簇间不相似度。
3.3.2. 轮廓系数求解
使用Matlab求解得出了不同玻璃类型风化前后的轮廓系数指标变化情况:
由表4分析可知,高钾玻璃风化后的最优分类数目减少,铅钡玻璃风化后的最优分类数目不变。对于轮廓系数评价指标,高钾玻璃风化后更远离+1,而铅钡玻璃风化后更接近于+1,说明铅钡玻璃风化后化学成分之间的关联关系加强,而高钾玻璃风化后化学成分之间的关联关系减弱。
Table 4. Analysis table of evaluation index of system clustering
表4. 系统聚类评价指标分析表
4. 玻璃文物的类别鉴定
玻璃文物易受埋藏环境的影响而风化。能从玻璃文物的表面明显看出是否风化,在部分风化的文物中,其表面也有未风化的区域 [1]。实验中已经测出玻璃文物的化学成分比例数据,能从玻璃表面观察到是否风化,但是玻璃的类型未知。由不同玻璃类别之间的化学成分关联关系的研究中,得出铅钡玻璃风化后化学成分关联关系加强,而高钾玻璃风化后化学成分关联关系减弱。所以为了减小有无风化对玻璃类型鉴定的影响,在建立玻璃的类别鉴定模型时,选用Fisher线性判别模型,将表面风化与玻璃类别用数字来表示:未风化计为0,风化计为1;高钾玻璃计为0,铅钡玻璃计为1。
使用经过预处理的实验数据,先建立玻璃类别的Fisher线性判别模型,利用回代分析分析模型的准确率。通过计算出高钾玻璃与铅钡玻璃各个化学成分的含量,选择出含量差别比较大的元素作为修改数据,对分类结果的合理性和敏感性进行分析。
4.1. Fisher判别模型的建立
Fisher判别的基本思想是投影,即将K组p维数据投影到某一个方向,使得组间距离最大,然后借助一元方差分析的思想构造一个线性判别函数,其系数确定原则是根据类间距离最大、类内距离最小的原则确定线性判别函数,再根据建立的线性判别方程结合合适的判别规则来判断待判样品的类别。经判别方程划分后,同类样品在空间上的分布集中,而不同类之间距离较远,差别明显。由于此时玻璃类别只有高钾玻璃与铅钡玻璃两种,所以仅考虑两总体的情况。
设有p维总体为
,它们都有二阶矩存在。此时在p维的情况下,x的线性组合为
,其中a为p维实向量。又有
的均值向量分别为
,它们也都是p维,都是公共的协方差矩阵
。
那么线性组合
的均值为:
,
方差为:
。
此时设置一个比值为:
其中:
。此时,根据Fisher判别的思想,要选择a使得比值达到最大。有以下定理可以确定a值与判别函数:
定理1 x为p维随机向量,设
,当选取
,
且为常数时,比值达到最大。特别地,当
时,线性函数:
把它叫做Fisher线性判别函数。
令:
定理2根据定理1,取
,则有:
。
此时,由定理3.2可得到如下的Fisher判别规则:
则定义判别函数为:
,
最后判别规则可改写为 [12]:
建立玻璃文物类别鉴定的Fisher判别分析模型首先需要确定评价指标,这是模型准确性的关键。根据题目所给条件,选定14种化学成分与表面风化共15个数据,即二氧化硅(S1),氧化钠(S2),氧化钾(S3),氧化钙(S4),氧化镁(S5),氧化铝(S6),氧化铁(S7),氧化铜(S8),氧化铅(S9),氧化钡(S10),五氧化二磷(S11),氧化锶(S12),氧化锡(S13),二氧化硫(S14),表面氧化(S15)共15个影响因子作为玻璃判别分析的评价指标。再将玻璃的两种类型作为Fisher模型的输出参数。
4.2. Fisher判别模型的求解
接下来,将实验数据的附件表单2 [1] 作为Fisher模型的学习样本进行训练,并且应用上文所介绍的原理,利用SPSS软件与Fisher判别函数求得线性系数向量见表5:
Table 5. Vector of linear coefficients
表5. 线性系数向量
求得玻璃类别鉴定的Fisher判别函数为:
此时高钾玻璃与铅钡玻璃的分类规律为:将
带入计算出
,
的数值比较大时就为高钾玻璃,
的数值比较大时就为铅钡玻璃。
4.3. Fisher判别模型的灵敏度分析
为了进行Fisher判别模型的灵敏度分析,首先利用实验数据的附件表单2 [1],分别通过Excel算出高钾玻璃、铅钡玻璃的化学成分均值。
Table 6. Average chemical composition of high potassium glass and lead-barium glass
表6. 高钾玻璃与铅钡玻璃化学成分均值
由表6知,在高钾玻璃与铅钡玻璃中化学成分含量差别较大的成分是:二氧化硅、氧化钾、氧化铅、氧化钡、二氧化硫。换言之,两种玻璃中其它元素含量类似,而这五种元素的含量决定了玻璃的类型。当改变这四种元素的含量时,也就会改变玻璃的类型。
此时我们随机选择了十组高钾玻璃的数据,将其二氧化硅、氧化钾、氧化铅、氧化钡、二氧化硫的数据修改为铅钡玻璃的平均值,如果玻璃类型的Fisher判别模型的灵敏性较好,那么应该此时预测这十组修改过后的数据,得到的结果应该都是铅钡玻璃。
Table 7. The prediction result after the modification of the value
表7. 修改数值后预测结果
观察表7的原类别与预测结果发现:修改数据之后,十组数据都从高钾玻璃预测得到铅钡玻璃,符合预期,模型判别的准确率为100%,说明此时的玻璃类型的Fisher判别模型的灵敏度是较好的。
5. 结论
本文通过对已有的实验数据进行分析后建立数学模型,基于实验数据探究了玻璃文物样品表面有无风化化学成分含量的统计规律、不同类别玻璃文物样品的化学成分之间的关联关系和给定的玻璃文物的类别鉴定。首先,通过玻璃表面有无风化化学成分的统计规律的描述性统计分析和卡方检验分析知,高钾玻璃在风化后主要化学成分含量呈下降趋势,铅钡类玻璃在风化后主要化学成分含量呈上升趋势;玻璃的表面风化与类型存在相关性且相关性较强。
然后,基于玻璃的表面风化与类型存在相关性且相关性较强这个结论,建立玻璃文物化学成分的无监督的系统聚类算法模型,研究表明,高钾风化、高钾无风化、铅钡风化和铅钡无风化的玻璃文物的化学成分的最优分类数目分别为2、3、4、4。再通过轮廓系数评价指标说明铅钡玻璃风化后化学成分关联关系加强,而高钾玻璃风化后化学成分关联关系减弱。
最后,依据玻璃文物的化学成分之间的关联关系研究的结论,建立了玻璃类别鉴定的Fisher判别模型,得到玻璃类别鉴定的Fisher判别公式,研究表明,玻璃类别鉴定的Fisher判别模型的判别准确率较高、灵敏度较好。本文对于古代玻璃的成分分析与类别鉴定具有一定的指导价值。