1. 新冠疫情可视化及预测研究的发展现状
研究背景和国内外发展现状
截至到目前,新冠疫情新增确诊人数在国内起伏较小,社会安定,但把视野放到全世界上,其他国家还在水深火热之中。在大数据技术发展快速的今天,海量的数据在网络上不断生成,只有正确利用这些现有数据才能让民众更好了解新冠疫情 [1] [2]。国内针对疫情大数据平台的研究早在2020年初,新冠肺炎在全国大规模爆发之际便应运而生。以江苏省为例,江苏省测绘工程院等单位以官方发布的新冠肺炎疫情相关数据为基础,综合运用时空大数据分析和跨平台可视化等技术,设计并实现了基于微服务架构的江苏省疫情大数据平台 [3]。此外,国外对疫情大数据可视化平台的架构与实现也在同时进行着。以欧洲为例,将9月14日欧洲的新冠肺炎疫情状况信息数据导入到Hive与大数据架Hadoop中进行数据分析,借助Tableau组件(数据可视化软件)将其可视化,展现出9月14日的新冠疫情状况,导出了不同指标的一系列图表 [4]。
在疫情预测方面,在新型冠状病毒爆发开始,全世界的学者就着手进行确诊人数分析和增长趋势预测,发表数目较多的学术论文。王旭艳团队采用时间序列分析,使用求和自回归移动平均模型(ARIMA)对新冠疫情数据进行重新建模并预测,结果与现实拟合度高 [5]。盛华雄等人将疫情传播分为两个阶段,即控制阶段采用差分递推方法和差分递推方法分析预测,自由传播阶段运用Logistic模型比较分析,论证了提早采用防疫措施的好处 [6]。而曹盛力等人的团队通过修正的SEIR模型对湖北省疫情进行评估和预测,结果表明了修正的SEIR传染病动力学模型可用于对COVID-19传播态势的分析预测 [7]。任晓龙等人采用Logistic回归方法对美国新冠肺炎确诊人数建立预测模型,通过实际数值进行拟合预测分析,结果发现在新冠肺炎疫情发作的前中期,Logistic模型拟合预测的情况与实际数据基本吻合,具有较高的预测精度,可用于新冠肺炎感染确诊人数的初期预测 [8]。基于这样的研究背景,以及考虑到神经网络技术可以对通过机器学习对时间序列曲线进行近似拟合,采用神经网络技术来实现对肺炎疫情趋势的大致预测。
2. 新冠肺炎疫情预测及可视化系统的研究内容
2.1. 对包含国内外疫情信息的网页进行数据爬取和数据清洗
疫情信息蕴藏在国家卫健委所统计的数据里,这些数据包括国内数据和海外数据,国内数据包含了全国各省市的每日新增确诊数,累计确诊数,新增无症状感染者病例数,死亡病例数,治愈病例数,高风险,中风险,低风险地区数,而国外数据包含国外各个国家的新增病例数,新增死亡数等信息,但数据内容并不全面,这是因为一些地区或一些国家的疫情数据信息并没有对外公布。每日腾讯疫情,丁香园以及网易新闻等第三方网页都会对这些以及公布了的疫情数据进行展示,对这些数据源网页进行爬虫是实现疫情数据可视化必要的准备工作。此外,还要对获取的数据进行预处理,保证数据质量的关键步骤是数据清洗。
最后,在进行数据可视化工作前,为了方便进行数据管理,提高数据重复利用时程序的效率,应将收集和清洗后得到的数据存入数据库中。
2.2. 疫情数据处理分析和可视化
数据可视化是借助图形化的方法,清晰有效的将数据中所蕴涵的信息展示出来。常见的数据可视化图形比如柱形图,饼图,折线图等能够直观地呈现出数据的特征以及历史数据的趋势。在本项目中,我们借助中国和全球的疫情地图,根据各地区确诊数等数据的大小对区域地图版图进行不同程度的染色,疫情确诊和死亡人数越多的地区所对应的地图模块的颜色就越深,这样可以使得疫情的基本状况能够一目了然。除此之外,一些疫情信息的细节可以通过交互式图表进行进一步的展示,例如各地区的具体确诊数,新增数,某日期的新增病例数等数据可以通过将鼠标悬浮在图表指定区域上进行查看,在可视化工具的选择上,使用Pyecharts生成的图表具有很好的可交互性,美观的页面设计和丰富多样的图表类型使其成为数据分析和可视化的强大工具,本项目采用Pyecharts完成了疫情数据可视化的工作。
2.3. 根据疫情数据建立神经网络模型进行训练并预测疫情趋势
此次席卷全球的新冠肺炎是一种典型的传染病,目前,现有的新冠疫情预测模型较多,其中包括回归模型、传播动力学模型和时间序列模型等。回归模型能够比较准确地反映出时间序列指定时刻的数值,但对于早于该时刻的情况则其预测能力有限;传播动力学模型在疫情爆发早期的数据支持下可较为准确地预测疫情走势,但因为早期数据的缺失性和非动态性,在科学预测方面仍然存在问题 [9];而对于时间序列模型,其数据收集和使用相对来说就比较简单,能够很好地预测短时间内的传染病波动,但对于突然暴发的新冠疫情的预测就捉襟见肘了,因此新兴的神经网络组合模型得到了应用。并且由时间序列的原理可推论得到,随着时间的变化,新冠肺炎疫情的发展也在变化 [4],而累计确诊病例数和日累计死亡病例数等数据对疫情统计和预测都有着举足轻重的重要参考价值。于是,可以建立基于时间序列的反向传播神经网络模型,借助MATLAB软件进行训练和测试,对中国新冠肺炎日新增确诊病例数进行预测分析,以期进一步掌握新冠肺炎疫情发展变化的规律,为政府防控新冠疫情提供参考 [10]。
3. 新冠肺炎疫情预测及可视化系统研究的意义
新冠肺炎(COVID-19)发展至2022年,因为其恐怖的流行性和传播性,被世界卫生组织定义为全球危险最高级的流行病。
在万物互联的今天,新冠肺炎疫情预测及可视化系统采样于国家卫健委、医疗系统的实时数据信息,利用数据收集理论形成原始数据,最后依靠前后端开发技术实现疫情动态信息显示。疫情动态系统能够第一时间为民众带来最可靠的疫情资讯,让人民群众正确深入地了解新冠病毒。信息可视化平台符合民众迫切想了解疫情的心理,能一目了然地反映出疫情的现状和走势,还能在不失真的情况下满足人们 [11]。
利用疫情大数据可视化平台建立疫情预测模型,掌握疫情的发展趋势,能够尽可能地帮助政府调整政策,控制疫情规模,防止其扩散传播,甚至可能在不远的将来彻底消灭新冠肺炎,让全球人民早日从瘟疫的阴影中解脱。
4. 新冠肺炎疫情预测及可视化系统设计
4.1. 通过Python网络爬虫收集疫情数据信息
网络爬虫技术是指通过编写一段程序或脚本,自动获取互联网网页内容和信息的技术,爬虫可以根据网页的统一资源定位符(Uniform Resource Locator, URL)自动获取网页的内容,返回得到网页的源代码,然后依据事先编写好的解析网页源代码的格式和内容的方法,通过解析网页内容便可获得想要获取的数据信息。其基本流程为请求网页,获取相应内容,解析内容,存储解析的数据。因为频繁的网络爬虫会给目标资源的服务器带来负担,因此很多网站也会设置相应的反爬虫机制来阻止用户的请求。
本项目通过Python网络爬虫获取数据集,数据源网页主要有腾讯疫情和网易疫情。腾讯疫情平台的数据主要是用于获取全国的各省市具体情况(一个月内)以及全球疫苗的接种情况。但是要做出全球的疫情情况,尤其是动态变化的过程,数据之间的联系情况,用腾讯平台的数据显然不太足够,而网易平台虽然对国内的数据并不是十分齐全,但是对于全球每一个国家从2020年开始的疫情数据是十分充足的,那么对于全球的疫情数据,我们主要是通过网易新闻平台进行爬取,作为对腾讯疫情数据的补充。
现在的网站数据爬取,除非一些特殊情况,我们只能通过对页面元素进行分析,对dom元素进行各种操作获取之外,很多的平台都会暴露出数据获取的接口,一般返回的是json格式的数据,只需要在浏览器的开发者视角,观察网络的发送获取情况,就可以发现暴露出来的数据接口。Python库中的requests库可以对这些接口进行处理,我们对json数据的格式进行分析,就可以获取到我们所需要的信息,然后就可以完成由网站到json到数组到数据库的操作。但是现在大多数网站都有反爬机制,最常用的操作就是,构建header,伪装一个User-Agent对象,将浏览者伪装成一个用户浏览器,网站发现是爬虫对象就会设置请求失败,但是构建成User-Agent就可以成功相应。
在腾讯疫情首页,进入开发者模式观察网络控制台接受的数据内容,在页面上随意点击一个省份查看其疫情状态,这里以广东省为例,可以看到网络控制台出现了名为list?adCode=440000&limit=30的json文件(如图1)。
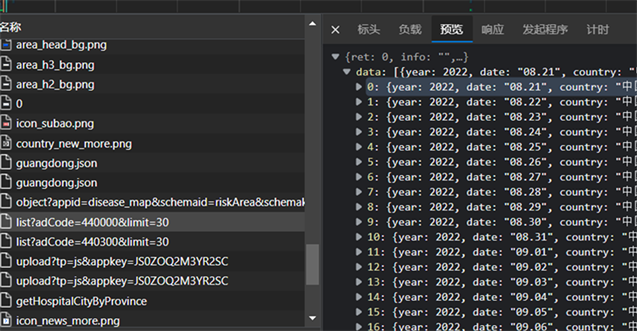
Figure 1. Tencent’s json file containing epidemic data of Guangdong Province
图1. 腾讯疫情包含广东省疫情数据的json文件
这里的adCode为中国行政区划代码,广东省的行政区划代码为440000,limit=30则限制了该文件记录了该省份30天内的疫情数据,包含了确诊数,新增确诊,死亡数,治愈数等数据。那么若要爬取全国的疫情数据,则可以此文件的网页链接为样本,依次输入各省份的行政区划代码替换440000组成新的网页链接,通过request获取到json文件的文本内容,然后借助json的语法或正则表达式获取想要得到的数据内容即可。下图为通过RE解析对腾讯疫情全国各省份数据爬虫的部分代码实现(图2)。
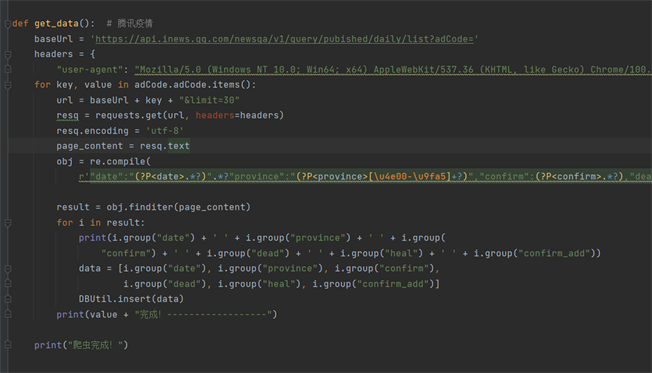
Figure 2. One month epidemic data of all provinces in China obtained by Tencent epidemic website crawler
图2. 腾讯疫情网页爬虫获取全国各省一个月疫情数据
爬虫程序需要实时去更新,因为网站的数据结构在不断的变化,本项目的需求是要做到实时更新的,所以项目的爬虫软件也要更新目标网站不断作出调整,做到实时更新。
4.2. 将数据清洗后存入数据库中实现持久化
数据持久化是指将内存中的数据保存到可永久保存的设备中,最常用的做法就是将数据写入到数据库中,数据库即存储数据的仓库,是电子化的文件柜。现在的数据库系统主要分为关系型数据库和非关系型数据库,关系型数据库的存储格式可以直观地反映实体之间的关系,而且关系型数据库在数据的查询方面功能十分强大,支持结构化查询语言,即SQL语句,查询速度较快,常见的关系型数据库有Mysql和SqlServer等,本项目即采用Mysql数据库来存储疫情数据。
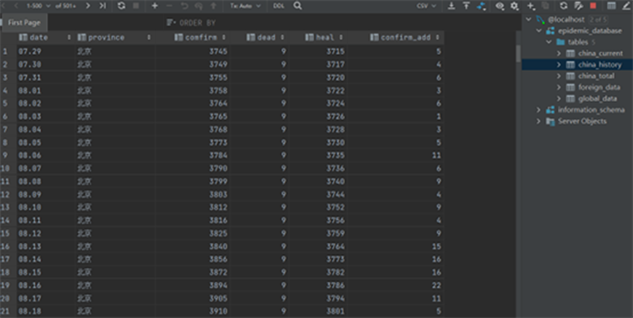
Figure 3. China_history table structure
图3. China_history表结构
在爬虫获得所需要的疫情数据后,我们开始建立关系型数据库,并依据这些数据内容的格式在数据库中创建特定存储结构的数据表。为方便管理,对不同爬虫模块获取的数据实行分表存储,比如,对腾讯疫情爬虫获得的全国各省一个月内的数据建立表china_history存储,对网易疫情爬虫所得的全球疫情数据(包含中国)建立表foreign_data存储,对腾讯疫情爬虫所得的全球疫情数据(不包含中国)建立表global_data存储。数据库的部分设计如图3所示。
在进行数据清洗工作时,由于爬虫网络具有较高的稳定性,所得到的数据内容已经经过计算机网络差错检测,并且疫情网页的数据一般情况下不会发送变化,因此可认为没有数据差错,脏数据的出现。但是在实际执行的过程中发现,网易疫情对于全球各国没有疫情数据的地区返回的数据类型是None,这种类型在执行数据库插入操作的过程时会发生报错,因此需要进行数据筛选,这里定义一个函数,若数据值是None则返回-1,代表数据内容缺失,若不是则返回原数,如图4所示,实现对数据的清洗。
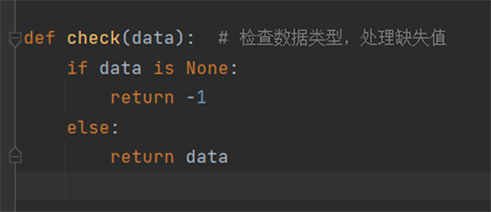
Figure 4. Define the check function to check missing values
图4. 定义check函数检查缺失值
4.3. 使用爬取数据创建可视化图表
数据可视化是指借助于图形化手段,清晰有效地传达数据内容所蕴含信息。通过图表使冗长的数据表达更加形象化,可以把问题的重点有效传递给观者。常见的数据可视化图表类型有柱形图,折线图,饼状图,点图和面积图等。选择不同类型的图表可以表现出数据在特定方面的数据特征,因此要根据想要传达的数据信息使用特定的图表类型,才能发挥出数据可视化的最好效果。
为了准确地将数据进行可视化处理,我们在python平台调用了强大的第三方库pyecharts。在python语言的支持下,百度开源的数据可视化技术Echarts很轻松的移植入python开发环境中,凭借着良好的交互性和精巧的图表设计,得到了很多开发设计人员的认可,当数据分析遇到了数据可视化时,pyecharts就能完美完成本次项目的可视化目标。
通过数据整理后,本次项目完成了中国疫情现有确诊柱形图、中国历史新增确诊折线图、中国实时疫情确诊人数图,中国疫情预测曲线(采用神经网络模型),中国累积确诊玫瑰饼图、新冠疫情发展趋势图和世界疫情累积确诊图。
在pyecharts中,所有方法均支持链式调用。链式调用是设计程序的模式,其优势是代码量大大减少,逻辑集中清晰明了,且易于查看和修改(可参考图5)。并且在pyecharts中,一切皆Options,即使用Options配置项来设计图表样式。
根据图表种类的不同引入不同的图表样式库。以图7为例,在链式调用中可定义可视化图表的宽度和高度,theme定义了图表的主题项,add_xaxis和add_yaxis分别定义了图表横纵坐标的意义,获取数据则调用DBUtil类中的方法,通过调用sql语句查询表的方法获取表内的数据,所得省份作为x轴坐标,现有确诊作为y轴坐标,再通过set_global_opts定义全局变量,设置图表的题目,字体大小和区域缩放等配置项。
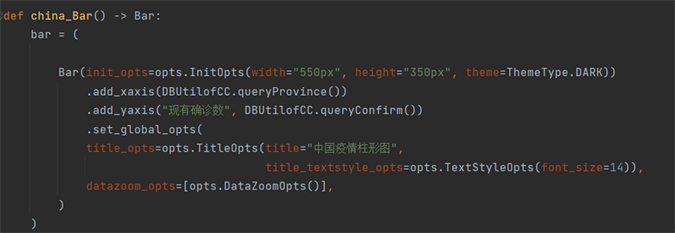
Figure 5. Key code segments of the current confirmed column chart of China’s epidemic situation
图5. 中国疫情现有确诊柱形图关键代码段
在pyecharts中没有具体的标题栏设计,所以本项目在ViewProducer类中定义了header方法,实例化了pyecharts的table对象并将rows设为空,如此就能够将标题栏以单行表的形式返回。
由于上述图表方法运行后均生成在不同的html中,所以为了实现将多表组合,本项目还运用了Page组件,并且选用DraggablePageLayout方法,即拖拽的方式。将page的layout属性设置为拖拽方法并实例化后,可获得多张可拖拽图表的html文件(图6),并会自动生成能够保存图表样式的按钮Save Config,当点击按钮后页面会自动保存图片样式并生成json文件(图7),只需将json文件重新加载即可获得拖拽后的html页面,并且该页面格式会固定无法更改(图8)。
4.4. 训练神经网络模型实现对疫情曲线的预测
某地区每日的疫情数据所组成的数据集是一种典型的时间序列,对时间序列进行分析和预测常用的神经网络模型有循环神经网络(Recurrent Neural Network, RNN)模型和长短期记忆网络(LSTM, Long Short-Term Memory)模型等,LSTM模型就是RNN模型的一种衍生品,具有“门”结构,通过门的逻辑控制数据的更改或舍弃,克服了以往RNN模型的权重影响太大,造成过拟合和梯度消失的问题,能够提高网络的预测精度,实现网络的收敛。本项目采用LSTM模型对疫情数据集进行训练和预测。
4.4.1. LSTM神经网络模型结构与原理
LSTM拥有三个门,依次分别是信息遗忘门、输入记忆门、输出记忆门,以此来决定每隔一时刻的信息记忆和遗忘。输入门是确定会有一个什么时候新产生的讯息会进入到细胞当中,遗忘门是控制每一时刻的讯息输入是否都会自动被遗忘,输出门是确定在每一时刻是否会有新讯息输出。细胞状态是LSTM的核心内容,用贯穿细胞的水平线表示。像传送带一样,细胞状态贯穿整个细胞并且没有多余的分支,以此保证信息不变地通过整个循环神经网络模型。细胞状态如图9所示:
LSTM网络中最重要的组成部分是门单位。门能够选择性地过滤信息。门的结构如图10所示:
sigmoid层输出0-1的值,能够控制进入sigmoid层的信息量。数值为0不能通过,数字为1则能通过。每个LSTM单元中含有3个控制细胞状态的门单元,即遗忘门,input门和output门。
遗忘门:即一个sigmoid单元,它负责处理信息并决定细胞状态需要遗忘即丢弃哪些信息。具体工作原理是:其通过查看h_{t-1}和x_t的信息来输出一个值位于0-1之间的向量,该向量的0-1值表示细胞状态C_{t-1}中的哪些信息丢弃或保留多少。0表示都不保留,1表示都保留。遗忘门的结构如图11所示:
输入门:然后是决定给细胞状态更新哪些新的信息。这一步又分为两个步骤,首先,利用h_{t-1}和x_t通过一个称为输入门的单元的操作来决定更新哪些信息。然后利用h_{t-1}和x_t通过一个tanh层得到新的候选细胞信息{C_t}~,这些信息可能会被更新到细胞信息中。这两个步骤如图12所示:
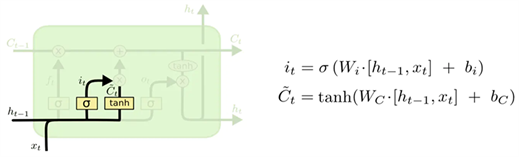
Figure 12. LSTM cell update action chart (1)
图12. LSTM细胞更新动作图(1)
然后将更新细胞信息C_{t-1}。更新的规则就是通过遗忘门选择遗忘旧细胞信息中需要遗忘的部分信息,通过输入门选择添加候选细胞信息{C_t}~中需要添加的部分信息得到新的细胞信息C_{t}。更新操作如图13所示:
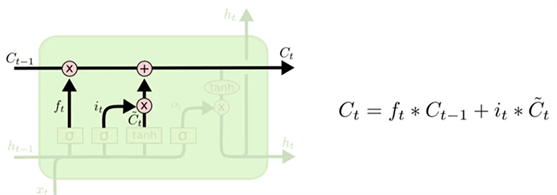
Figure 13. LSTM cell update action chart (2)
图13. LSTM细胞更新动作图(2)
输出门:更新完了细胞状态信息后,还需要根据输入的h_{t-1}和x_t来判断输出细胞状态的哪些状态特征,可以通过将输入的h_{t-1}和x_t经过一个称之为输出门的sigmoid层得到一个判断条件,然后将细胞状态经过tanh层得到值位于一个−1~1之间的向量,该向量与输出门所得到的判断条件相乘就得到了最终该LSTM单元的输出。该步骤如图14所示:
4.4.2. 处理疫情数据集
通过之前的网络爬虫和数据持久化过程,项目的数据库中已经存放了最新的疫情数据,其中历史数据有中国各省和中国全境的一个月内的数据,这里以中国全境的历史数据为例,进行数据处理方便LSTM模型进行训练。过程包括数据格式转换和数据归一化等操作。代码部分如图15所示。
首先通过DBUtil工具类定义的查询操作得到中国全境一个月内的每日新增确诊数数据,返回的格式为一个整型列表,然后以其为参数借助pandas库的DataFrame构造方法和values变量返回一个Numpy数组dataset实现格式的转换,然后利用Numpy的max和min函数获取该数据集的最大值和最小值,两者相减得到极差scalar,最后通过匿名函数将数据集中的每个数据除以scalar实现数据归一化。
另外,定义一个处理数据集的函数,我们对模型进行训练时要有两个数据集,一个是输入数据集,另一个是目标数据集。在这里我们将该疫情历史数据进行划分,以前三个数据作为后一个数据的输入,以此类推,得到两个长为len-3的数据集(len为历史数据长度),其中输入数据集的每个元素由三个数据组成。
4.4.3. 利用疫情数据集进行LSTM模型的训练
训练过程如图16所示:
我们进行了10,000轮次的循环训练,每100轮输出loss的值反映训练进度,可以看到在进行了10,000轮训练后,损失函数的值已经非常小。最后我们把训练好的模型参数保存下来,用于后面的测试。
4.4.4. 利用训练后的LSTM模型进行测试
我们利用训练好模型进行测试时,前70%的数据集为训练集,后30%的数据集为测试集,根据训练好的模型参数,我们定义预测函数实现对中国历史新增病例数的预测,并将输入数据和输出数据借助可视化工具展现在图表上,输出的疫情预测曲线图如图17所示。模型的output与训练样本的output高度匹配,但是测试集依然有不小的误差,这是由于数据集的数据太少,当我们增加训练数据集的数据量,模型训练的效果会更加符合真实情况。
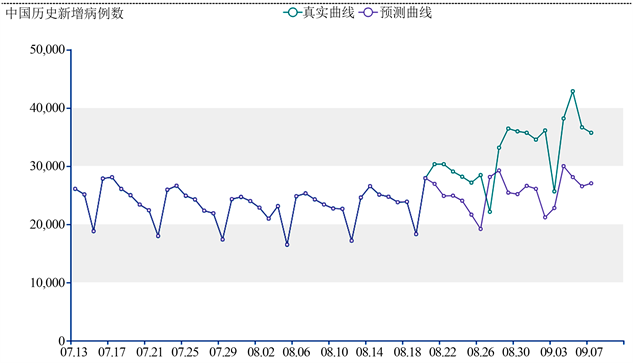
Figure 17. Forecast of historical increase in China
图17. 中国历史新增预测图
5. 结论
本文分析了新冠肺炎疫情预测及可视化系统的国内外研究背景和研究现状,在可行的基础上确定了本项目的研究内容,包括网络爬虫获取疫情数据,数据持久化,数据可视化,建立神经网络模型进行数据预测等,并结合当前疫情状况分析出该项目的研究意义:旨在借助数据可视化技术将蕴藏在海量数据中的疫情信息直观地表现出来,为疫情防控工作提高便利,以期早日消灭疫情。最后在系统设计方面给出具体方案,包括网络爬虫模块的网络控制台搜索数据源网页,正则表达式解析数据内容等,数据持久化模块的数据库设计,数据清洗等,可视化模块的基本图表生成,配置文件存储等,疫情预测模块的LSTM原理分析,神经网络训练,测试,生成预测曲线等。通过上述方案的实施,我们完成了该系统的设计。
本项研究还有以下待改进的地方:
1) 收集所得的数据内容不够完整,部分网页爬虫所得的全球疫情数据有一些地区是未公布的,这些缺失值未得到有效处理,可以扩大数据源网页的搜索范围进行补充。
2) 收集所得的数据内容不够全面,除了新增确诊数,死亡数,治愈数,累计确诊数等,一些其他数据比如高风险地区数,死亡率,治愈率,接种疫苗数等也可以加入到收集的数据集中。
3) 数据可视化的图表类型不够丰富,数据可视化工作实现了柱形图,折线图,玫瑰图,疫情地图等基本图表的展示,其他类型的图表有待补充。
4) 预测模型效果不够理想,疫情预测模块的测试工作里我们发现疫情预测曲线虽与真实曲线大致相似,但依然有些误差,可以通过扩大训练数据集来提高预测效果。
致谢
感谢北京信息科技大学大学生创新创业训练计划项目的资金支持,感谢张翠平老师的指导。
基金项目
基金资助由北京信息科技大学大学生创新创业训练计划项目–计算机学院(5112210832)支持。