1. 引言
1.1. 研究背景以及意义
大脑是人类神经系统中最复杂、最先进的器官,在中枢神经系统中发挥着至关重要的作用和功能。脑瘤,也称为颅内肿瘤或脑癌,是新形成的生长物,可以起源于颅内腔内的各种组织,例如脑组织、脑膜、神经和血管。脑瘤是常见的神经系统疾病,对患者的生命构成重大威胁。磁共振成像(MRI)目前被广泛认为是检测和诊断颅内病变最有效的成像诊断方法。
在脑瘤的诊断和治疗中,医学图像分割技术发挥着至关重要的作用。因此,开发自动化、高效、准确的脑瘤分割算法对于改善脑瘤的诊断和治疗效果至关重要。手术切除是治疗脑瘤的最佳方法之一,因此,在术前准确分割出需要切除的整个脑瘤区域至关重要。传统的分割方法是人工手动分割,这一方法需要大量的人力、物力和时间资源,并且分割结果受到医生个人经验和主观因素的影响,从而导致一些误差和不确定性。
基于深度学习的图像分割算法可以自动学习和提取图像特征,从而减少人为干预,提高脑瘤分割的准确性和精度。基于深度学习的算法具有良好的学习能力,可以从大量的医学图像数据中学习更准确、可靠的特征,从而提高脑瘤的分割准确性和自动化水平。这种方法可以有效完成脑瘤分割任务,缩短医生的诊断时间,减轻医生的工作负担,同时也降低医疗成本。因此,基于深度学习的脑瘤分割研究已成为医学图像处理领域的热点和挑战之一。因此,基于深度学习的脑瘤分割研究具有重要的理论和实践意义,并将在未来医学诊断和治疗中发挥越来越重要的作用。
1.2. 国内外研究现状
1.2.1. 深度学习在医学图像分割中的应用
近年来,基于深度学习的计算机视觉图像处理已成为研究的热点之一,特别是主要基于卷积神经网络(CNN)以自动从大量的医学图像中学习特征,并且可以实现端到端的训练和预测。其中,由多层卷积叠加构成的全卷积神经网络在医学图像处理的领域更是备受关注。全卷积神经网络在提取图像特征信息上取得了不小的进展。卷积运算中卷积核参数的共享方式,不仅能大幅度降低参数量,还能保证学习到的参数具有稳定性,而卷积本身能学习到图像数据的结构不变性。因此,全卷积网络结构是当前应用最广泛的结构之一,例如,由Olaf等人首次提出的U-Net [1] 结构解决了深层特征抽象和浅层特征提取不足的问题,实现了更明显和具体的特征提取,从而提高了分割精度。此后,许多研究人员在U-Net结构的基础上增加不同类型的卷积模块,从而提出新的基于卷积计算的网络结构 [2] [3] ,例如,例如提出图像块分割后,对每个块进行卷积运算后重新拼接的重组块卷积算法 [3] 。虽然全卷积结构在医学图像分割方面取得了巨大的成功,但由于卷积计算的特殊性,它是以滑动图像块的方式对像素块进行计算,导致特征学习受限于局部信息,难以学习到全局特征。
1.2.2. Swin-Transformer结构
当输入图像分辨率较高,像素点较多时,使用全局自注意力的Transformer将导致计算量急剧增加,因此Transformer常用于提取较低维度的底层特征图,例如TransBTS模型 [4] 。然而,高维特征图中包含的全局信息同样重要,因此研究学者从多个角度提出各种方法来减少Transformer计算时的数据量。例如Swin-Transformer结构,Swin-Transformer [5] 是由香港中文大学、微软亚洲研究院等机构的研究人员共同提出的一种基于Transformer算法的一个新的架构。用于解决当Transformer计算量大的问题。Swin-Transformer模型通过将特征图用不同的方法分块,再将这些块进行Transformer的计算,从而达到降低参数量的效果。解决了在原始特征图上进行Transformer计算参数量大的问题;在此之后,这些swin_Transformer模块被直接添加到网络中,直接替换网络中的卷积模块数据进行特征提取 [6] 。这些新的神经网络已经被广泛的应用于医学图像分割 [7] [8] [9] [10] [11] 。
1.2.3. 多模态图像融合
多模态图像融合是指将不同类型的图像信息结合在一起,以获取更准确、可靠的结果。这种方法特别适用于医学图像处理,其中许多研究人员致力于使用深度学习技术来提取和融合多模态医学图像的特征。多模态图像融合方法可以分为前期像素级别融合和中期特征级别融合。前期像素级别融合方法将图像像素点与像素点结合起来,但效率低且容易产生模糊效果。而中期特征级别融合方法更加灵活,适用于处理不同的融合任务,可以帮助分割模型学习代表性的特征,并消除图像中的不确定性和歧义信息,以获取更准确的判别结果。基于深度学习技术图像融合可以融合由不同成像方式而来的不同模态图像信息。例如,利用通道交换的方法对RGB、Depth、Normal等不同的图像模态进行融合 [12] 。对于多模态的脑肿瘤图像来说,不同的成像模态可以为病理区域提供独特的特征,并且能够揭示隐藏在各种形式中的互补性信息 [13] 。例如,一些研究采用Transformer和U-net的下采样分支分别提取大脑图像的四个模态的特征信息,然后将这些特征信息拼接计算以获得最终的分割图像 [12] 。
2. 模型以及数据处理
2.1. 数据集和数据预处理
本文使用宾夕法尼亚大学生物医学图像计算与分析中心(CBICA)提供的公开脑肿瘤数据集BraTs2021 [14] [15] 来验证我们的方法。在BraTs2021数据集中,每个病人数据包含四个模态图像(T1、T1ce、FLAIR、T2)和一个肿瘤标签图像。肿瘤标签包括背景(标签0),坏死和非增强性肿瘤(标签1),肿瘤周围水肿(标签2),GD增强性肿瘤(标签4),分别用红色、绿色和黄色标记。标签由四名经验丰富的放射科专家医生按照统一的标准进行标注。一般选取增强区域(ET,标签4),肿瘤核心区域(TC,标签1和4),以及整个肿瘤区域(WT,标签1、2和4)作为研究对象,或者分别单独作为研究对象。在BraTs2021的训练集中,即有分割标签的训练集(BraTs2021共1251个数据)中,随机选取70%作为训练数据对网络进行训练;10%作为验证集,将训练好的模型用于数据集其余20%的数据进行预测。
文中使用的实验数据为三维图像,原始尺寸240 × 240 × 155,经过随机裁剪后变为128 × 128 × 128作为输入图像,这种裁剪的方式在一定程度上可以减少计算成本,增加训练数据量,并且易于输入模型。训练数据进行数据增强,进行随机翻转,增加随机噪声,数据增强可以提高模型的泛化能力。采用Adam优化器,初始学习率的设置为0.0002,其中初始速率通过每次迭代以0.9的幂衰减。模型正则化则采用L2范数,权重衰减率为10−5。Batch size为1,并且使用两个3090 GPU进行并行训练,即每个GPU每次只放入一张图像进行技术。训练将最后4个模型的训练结果进行平均得到最后的分割结果。
如图1所示,研究选取了BraTS2021数据集中随机的一个病人样本,该样本包含了四种模态图像,T1模态,T1ce模态,T2模态和Flair模态。图像从左到右分别是T1模态,T1ce模态,T2模态,Flair模态,从上到下分别是大脑不同模态的灰度图像和带分割标签的脑肿瘤图像。肿瘤标签图像标记了坏死和非增强性肿瘤标签(标签1,红色)、肿瘤周围水肿标签(标签2,绿色)以及GD增强性肿瘤标签(标签4,黄色)。T1和T1ce模态在检测脑肿瘤水肿方面有其优势,医生通常会结合T1和T1ce模态进行观察。T1ce可以突显血量较高的区域,并强化显示肿瘤部位,进一步展现肿瘤内部情况。T2模态信号强度与水含量相关,易于确定病灶位置和大小,水肿区域边界清晰可见,但容易与脑脊液混淆。为了解决这一问题,可以结合观察T2和Flair模态,以便更容易区分脑脊液和肿瘤,Flair模态有助于观察肿瘤边缘。同理,医生通常会结合T2模态和Flair模态进行观察,以便更准确地判断胶质瘤的实际范围。这种方法在2022年提出的CKD-TransBTS模型中被证实其有效性和必要性 [16] 。
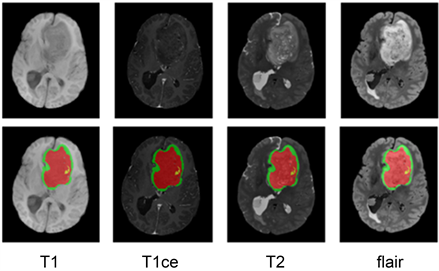
Figure 1. Four modal images of a patient in the BraTS2021 dataset
图1. BraTS2021数据集中一个病人的四个模态图像
2.2. 网络结构的整体框架
图2是本文提出的网络结构的整体框架,这个框架具有一个U形结构,由一个encoder分支,一个跨越桥梁分支,一个decoder分支组成。
在encoder部分,将一个病人的脑肿瘤MRI图像作为输入,将4个模态的MRI图像作为4个分支输入,首先对其分类,T1,T1ce拼接作为第一个组合类别,T2,Flair拼接作为第一个组合类别。这两个类别作为输入,两个分类分别经过Baseconv block后,再经过三次modal_fusion block down。modal_fusion block down是利用卷积算法提取不同模态中的细节特征,再利用通道交换的方法进一步融合模态。经过三次这样的模块输出三个不同尺度,具有较好的不同模态融合特征的特征图。
在跨越桥梁部分。将encoder输出的三个特征图分别经过Swin_Transformer模块,其中与传统的Swin_Transformer模块不同,shifted window的取法做出改变,利用扩大视野的方法,使得这个模块提取到更佳的图像全局特征。跨越桥梁的输出与输入做残差连接,降低学习到的特征过于抽象,对模型分割精度的影响

Figure 2. The framework of the proposed network structure
图2. 提出模型的整体框架
在decoder部分。利用残差连接的方式,融合全局特征和局部特征,作为decoder的拼接特征图。由最底层的低维度特征图,通过反卷积的方法,恢复图像大小。升维的特征图与跨越桥梁的输出进行拼接。再经过反卷积,向上恢复维度。这样的拼接做两次,特征图向上恢复维度做三次,即conv bolock up模块。最后利用一层卷积核SoftMax函数输出分割概率矩阵,在网络中采用的模块包括Baseconv block,modal_fusion block down,Swin_Transformer,cat + conv bolock up模块。其中modal_fusion block down,和的结构Swin_Transformer如图3所示。
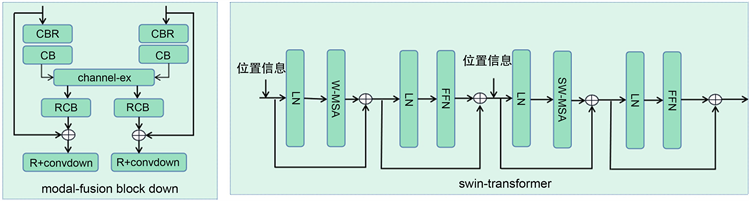
Figure 3. The internal structure of each module in the proposed network
图3. 各个模块的内部结构细节
2.3. 网络结构细节
2.3.1. Encoder
在Encoder部分,对模态进行分组,将分组后的数据,设计通道交换的特征提取路径,来提取同一分组数据下相似的特征和不同分组数据的融合特征。模型的输入为
,即4种模态的MRI图像。将4个模态分为两组,T1模态,T1ce模态为一组,T2模态,Flair模态为一组,进行特征提取,即输入数据分别为T1模态,T1ce模态分组
,T2模态,Flair模态分组
。
,
两组数据分别经过Baseconvblock进行特征提取。Baseconvblock是由组合3 × 3 × 3卷积,Batch Norm,ReLu激活函数,两个相同组合构成。得到同一分组下,分组一提取的特征
和分组二提取的特征
,其中
,
表示第i个分组的第j层特征,
,
,其中输入modal_fusion block down的初始特征
。随后再经过3次modal_fusion block down模块,即模态融合模块,其具体结构如图3左图框架所示,图中C表示3 × 3 × 3卷积,B表示Batch Norm,R表示ReLu激活函数。在第一层modal_fusion block down模块中,特征
和
分别经过CBR进行通道扩张,由4扩展为8,得到的特征经过CB后进行通道交换。
每个模态组合的每个通道有一个可学习的参数,这个参数的大小说明了这个通道学习到的特征的重要性。即这个通道特征越重要性越大参数越大。当这个学习到的参数小于设定的阈值
,训练时设置
。参数小于设定的阈值说明这个通道的特征的重要性不大。则将这个通道用其他模态的对应通道取代。如公式1所示,
表示第i组模态
,第j层特征,
,第k个通道。通道交换细如图4所示。通道交换消除了特征学习期间的冗余数据,同时进行不同组合模态之间的通道交换,完成不同模态组合的特征融合。
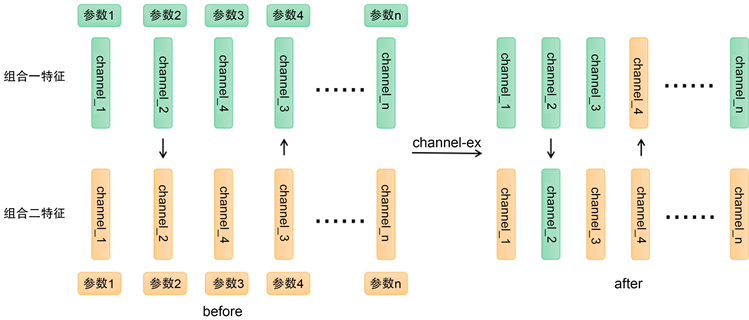
Figure 4. Diagram of the practical teaching system of automation major
图4. 通道交换细节
(1)
将通道交换后的两组融合特征分别经过RCB。得到的特征与输入的特征
和
进行残差相加后,经过一个ReLu激活函数,再通过步长为2的3 × 3 × 3卷积,缩小图像。输出下一层输入特征
和
,
。重复以上计算三次,获得三种不同分辨率大小的特征,使得每一层的特征维度为
,通道数为
,
。第一层输出特征
和
,
,第二层输出特征
和
,
,第三层输出特征
和
,
。
2.3.2. 跨越桥梁
在Encoder和Decoder桥梁部分采用swin-Transformer来提取数据全局特征。swin-Transformer结构如图5右图框架所示。首先对数据进行window patch取块,对每个块加入位置信息,经过一层Layer Norm,再对每个patch进行Multi_Attention计算,输出与输入进行残差相加后,经过一层Layer Norm和一层FFD (FeedForward),残差相加后输出。输出数据进行s_window patch取块,进行相同的计算。
对于本文来说,即对Encoder部分输出的第一层特征
和
,将特征,按照通道方向进行拼接作为swin-Transformer的输入数据。第二层,第三层相同。swin-Transformer计算细节如图5左图所示。图5左图为Transformer中Multi_Attention计算图解。

Figure 5. swin_Transforme details
图5. swin_Transformer细节
实质上swin-Transformer的计算是用输入数据以不同的形式取patch,对每一个patch进行Transformer计算。其中两次取patch,分别是Window patch和s_window patch,其取法如图6。如图6左图,Window patch是用不重叠的方式将特征块分成多个patch。传统swin-Transformer中取s_window patch (shifted window)的方法,是以重叠的方式滑动window,从而得到多个patch,得到的每一个patch都是由连续的像素点构成。与传统方法不同,本文提出的s_window patch (space lattice window)是以不重叠的方式将图像分成多个块,取出每个块中相同位置的像素点拼成一个patch。即是以点阵的形式取patch后进行Transformer计算。这种方法与传统方法相比,保留了图像的全局特征,增大了特征学习的视野,即每一个patch都是一个低分辨率的原始图像。
三层不同swin-Transformer分别输出三个不同大小的模态融合的全局特征
,通道数为
,
。将输入swin-Transformer的特征和输出的特征进行残差相加。得到三层既包含局部的模态融合后的特征,又包含全局的特征。这三层特征用于Decoder反卷积时的长连接。
2.3.3. Decoder
在Decoder部分,cat + conv block up模块细节如图7所示。Encoder和Decoder桥梁输出的最底层即第三层特征经过conv block up模块后,与桥梁输出第二层特征按通道维度进行拼接,再经过conv block up模块。同理,输出特征与桥梁输出第一层特征按通道维度进行拼接,再经过conv block up模块。得到的特征与整个模型输入的原始特征进行相加后,经过SoftMax激活函数得到分割概率矩阵。根据概率得到最后分割结果。

Figure 7. Details of cat + conv block up module in Decoder
图7. Decoder中cat + conv block up模块细节
3. 实验与结果分析
3.1. 与基线模型比较
除模型中采用各个标签0和1,2,4融合标签WT的softmax Diceloss之和作为损失函数对网络进行训练,如公式(2)所示,其中Dice0,DiceWT,表示输出标签0,和融合标签WT与精标准之间的Dice值。每个模型我们都进行了400次epoch的迭代。
(2)
我们将提出的模型与TransBTS [5] ,2016年提出的U-net结构 [1] 进行比较。
表1展示了三个模型在BraTs2021数据集下的分割结果,我们提出的channel_ex模型在整个肿瘤区域(WT)获得Dice score为91.05。可以看出我们提出的模型与TransBTS、2016年提出的U-net [12] 结构对比获得了有竞争性的结果。即三个模型中我们的模型具有最佳性能。并且我们做了模块的消融研究,当模型中不含有swin_Transformer模块,只含有通道交换模块即表1中Our model_chex的模型,其WT的分割精度小于带有swin_Transformer模块的模型,证明了swin_Transformer模块在模型中对WT区域分割精度提高的有效性。

Table 1. Comparison of segmentation results of each model on BraTS 2021 data
表1. 各模型在BraTS 2021数据上分割结果比较表
图8显示了在BraTs2021数据集上与其他基线模型相比较的定性结果,红色区域表示标签1,即WT标签部分。上到下分别是三个病人同一层的脑部图像,从左到右分别是TransBTS,U-net结构,本文提出的模型2的二分类分割结果,GT为精标准。绿色方框区域表示我们的结果比基线模型的细节刻画优越的区域。

Figure 8. Details of cat + conv block up module in Decoder
图8. 在BraTS2021数据集上不同模型的分割结果的可视化比较
从可视化结果的绿色方框区域结果可以看出,我们的模型学习到比其他模型更为完整的分割信息。
我们将四个模态分为两类,对每一类提取特征信息的同时不同类之间进行通道交换,以融合模态中的特征信息。模型中的Swin_Transformer结构能够学习到更为全局,且刻画更加细节的特征,从而获得精度更高的分割结果。
3.2. 模型消融研究
公对于模型中通道交换方法和swin_Transformer方法分别进行了消融研究,研究结果如表2所示。每个消融实验的研究我们都进行了400次epoch的迭代。我们对模型中的三层swin_Transformer中每一层的窗口(window)大小进行了研究。三层的基础窗口边长数为8,研究不同层的窗口大小对实验结果的影响。
Table 2. swin_Transformer window ablation study
表2. swin_Transformer window消融研究
4. 结论与展望
根据医生手动标注的经验,脑肿瘤的四个模态被划分为两类,同类模态之间具有更准确的分割特征。为了更好地提取同一分类图像的特征信息,需要通过去除学习到的冗余信息,利用通道交换的方式去除不必要的通道,并将另一类重要的通道交换进去,使得每个通道学习到的特征都非常重要,并且可以同时融合不同的模态信息。在模型的长连接部分,使用点阵window的swin-Transformer模型对图像提取全局信息。该模型在第一章介绍的公开的数据集BraTs2021上进行了验证。通过将该方法与其他两个基线网络TransBTS和U-net进行比较。结果表明,该方法比其他方法更能获得更精确的分割结果。同时对这个模型的进行了消融研究,实验表明,通道交换和点阵window的swin-Transformer,在模型中对提高分割精度具有重要作用。并且对通道交换的以及swin-Transformer window大小进行了消融研究,获得最佳模型方案。
由于训练数据集是模态完整的脑肿瘤图像,在未来期望随机丢掉部分模态,测试模型对缺失模态是否具有泛化能力。