1. 问题提出
随着中国经济的日益发展,国力的日趋强大,越来越多的外国留学生开始将中国作为留学的首选国家。根据教育部2017年统计,我国已经成为亚洲地区首要留学目的国,境内约有48万名外国留学生。自建国以来,我国的来华留学工作具有极其鲜明的政治色彩,来华留学工作一直秉承着服务于教育发展和国家大外交战略。因此在很长时间里,来华留学的工作重点是为国家在国际上培养知华、友华人士。但是随着国家教育改革的日益深入和外交政策的战略转变,来华留学工作只满足于过去的内容已跟不上时代发展。近年来,来华留学已逐渐成为各校促进教育改革,加快教育国际化的抓手。在此变革的阶段,很多长期以来积攒下来的问题也逐渐显现出来。公众对来华留学生生源和人才培养质量的质疑随着“中国花大价钱买留学生”等新闻的传播甚嚣尘上,这说明社会普遍对来华留学工作的好奇和不了解。但是目前我国尚未形成针对来华留学人员准入和人才培养质量的标准化评价体系,想要比较科学和系统地了解来华留学人员人才培养质量相对困难。因此针对来华留学生人才培养质量的研究就显得尤为必要,但是目前相关实证研究较少。所以本文将通过对北京市高校的在校外国留学生学习情况进行调查,分析来华留学生学习成绩影响因素。从而为来华留学政策的制定提供实证依据。
2. 数据描述性统计
本研究数据来源于2018年针对北京市外国来华留学生在校学习情况调查。该调查主要通过收集问卷的形式进行。表1对调查样本进行了基本的描述性统计分析。
从样本整体来看,如图1所示超过7成的受访者是男性,71.26%,而女性受访者只占28.74%。从年龄层次来看,多数样本的年龄集中在25~30之间,最大年龄为44岁,最小为21岁,平均年龄30.69岁,年龄中位数和众数分别为30岁和28岁。从学历层次来看主要以硕士和博士为主,占总体比例的90.7%,其中博士生54.65%,硕士生36.05%,此外还有4.65%的本科生,3.49%的交换生和1.16%的语言生。这说明本次调查中样本的学生受教育水平总体偏高,近9成受访者在中国接受了较高层次的高等教育,同时这也解释了样本年龄为何集中在25~30之间。如图2所示,从生源地来源上看47.5%的受访者来自亚洲,40%的受访者来自非洲,8.75%来自欧洲,美洲及其他大洲的占3.75%。根据表2,其中受访者主要来源国前五名分别是:巴基斯坦、几内亚、卢旺达、蒙古和法国,共占总数的53.75%。此外,约有四成受访者父母受过高等教育,其中受访人群中超过半数的父亲受过高等教育,而母亲受过高等教育的有32.18%。考虑到受访者多来自发展中国家,这也从另一个侧面表明受访者是来自相对较高教育水平的家庭。虽然国家目前21.86%的受访者承认在校期间存在打工行为。
3. 研究方法与模型
分层模型(HIERARCHICAL LINEAR MODELS, HLM)原理是将变量差异分解成情景差异和单位差异 [1] 。根据朗文字典对社会做出的定义:社会具有一定法律、组织等使人们能够生活在一起的结构,因此人是社会整体的一个构成部分。从“社会人”角度分析,人不是孤立的个体,在满足生物属性的基础之上,人同时还满足社会属性。每个人类个体都具有不同的背景,或属于某个家庭,或属于某个社区,某个组织,某种阶层。因此人类个体的行为不仅受其本身特性的影响,同时也会受其所处的环境及背景的影响。从统计学角度来看,这种属性可以被描述成低级层次个体嵌套于高级层次个体的层级结构属性。
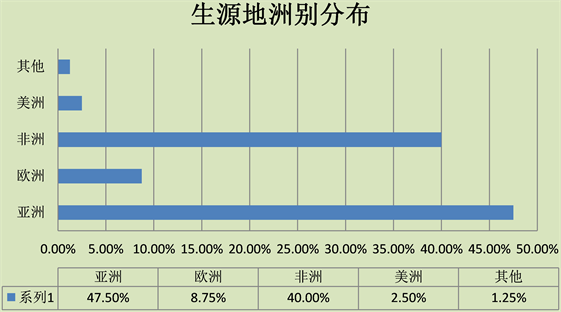
Figure 2. Distribution areas of student source
图2. 生源地洲别分布

Table 2. Country statistics of student sources
表2. 生源国别统计
比如:学生成绩水平嵌套于学校,选民的选举偏好嵌套于社区等 [2] 。本研究只将全部样本分为单位个体和国家两层。预测变量为是否学习成绩,由于因变量是连续变量,因此本文将采用连续变量模型。
随机系数回归模型(Random-Coefficients Regression Model)
随机系数模型其实是由两种模型构成的:随机截距模型和随机斜率模型他们都属于有条件模型。(Raudenbush, 2007)随机截距模型的原理是:假设下层预测变量的截距会伴随上层特性的不同而产生差异。对于本研究而言就是加入地区特征变量以及残差并且假定残差的产生是随机的。同时每个区域回归的斜率是固定的 [3] 。其形式如下:
LEVEL1 MODEL
LEVEL2 MODEL
MIXED MODEL
与随机截距模型相似,随机斜率模型是对level-1模型中变量的斜率进行设定。因此在最终的组合模型中会产生交互项。其形式如下:
这两种模型的主要区别在于:随机截距模型假定各层对预测变量的影响是独立的,而随机斜率模型假定各层对预测变量存在相互影响。本研究的主要目的在于分离地区层面和微观个体层面的特征对排放行为的影响。因此只考虑使用随机截距模型。
4. 实证分析结果
本文使用HLM6.02版本软件进行来华留学生成绩影响因素的分层分析。
4.1. 带随机效应的单因素方差分析(One-Way ANOVA Model with Random Effects)
从零模型结果来看,来华留学生成绩影响因素的组内相关系数为:
,说明预测变量(来华留学生学习成绩)的变化约有11%的区别可以被国家间的差距所解释。
4.2. 随机截距回归模型估计结果
模型将自变量分解成层一个体特征变量(level1)和层二国别特征变量(level2)。模型具体设计是层一只包括受访来华留学生个体特征如:性别、父母接受高等教育情况、是否住校、打工时间、在校期间主动合作学习情况以及在校期间师生互动情况。层二模型针对层一模型的截距项设置变量与随机误差,国别特征主要包括人均GDP增速,其余的斜率都是固定的。模型具体结果如表3。
4.3. 最终模型随机效应估计(表4)
本文主要目的是研究国家特性对来华留学生在校成绩的影响,不考虑每层之间的交互效应,因此本模型支队截距项设定变量和随机项。因此本文所用随机截距模型进行分析,这样一来就可以将所有层间的交互作用以及所产生的变异误差全部归为国家差别的随机误差中,最终能够独立的分析国家层解释变量对来华留学生在校学习成绩的影响。其中为了方便对截距项进行解释,对数据进行了对中处理。
值得注意的是τ00 = 0.17147是level 2截距残差的方差估计,而对于无条件模型而言其τ00 = 0.51964 ,这说明当level 2加入了地区变量之后解释了原来截距方差的(0.51964 − 0.17147)/0.51964 » 0.670022。也就是说国家人均GDP增长变量可以解释原有方差的67%,换句话说各国的人均GDP增长差异解释了各国来华留学生之间的成绩差异的67%。这也说明了在level 2中加入国家变量确实能够使模型更合理。
1) 截距项的解释:对于一个来自人均GDP增速处于样本生源国平均水平(肯尼亚或塞拉利昂),在主动与同学合作学习和师生互动方面表现处于中等水平的,家里母亲没接受高等教育的学生的成绩为A-。
2) 对于国家变量而言,国家的人均GDP增长速度越快,该国家的来华留学生的学习成绩相对会变得比较低,对应的成绩下降程度是0.3分。也就是说在控制其他变量不变的前提下,当一国的人均GDP
Table 3. Final estimation of fixed effects (with robust standard error)
表3. 固定效应最终估计(稳健标准误差下的模型)
*、**、***分别代表参数估计值在10%、5%、1%水平上显著。
Table 4. Final estimation of variance components
表4. 方差成分的最终估计
*、**、***分别代表参数估计值在10%、5%、1%水平上显著。
增长速度上升1个百分点的时候,该国来华留学生在校成绩会下降0.3分。一种比较可能的解释为,若一国的人均GDP增速较快,则说明该国国民能感知到的经济状况变好,家庭生活质量较以往有所提高。而生活条件的提高,通常代表着物质条件的提高,因此随着学生家庭物质条件的增长,通常其学习刻苦程度会相应下降。
3) 就主动合作学习情况而言,模型结果符合大众认知的预期,越主动和同学合作学习的学生其成绩越好。平均在主动合作学习方面得分表现每提高1分,该来华留学生的总成绩提高约为0.3分。这表明越主动学习,越积极向同学请教学生的成绩与其所付出的努力成正比。
4) 母亲接受过高等教育的来华留学生比母亲没有接受过高等教育的学生成绩要低2.2分。虽然分数看上去所差不多,但是首先要知道按照成绩制度,大约每3分就可以拉开一个成绩等级。也就是说,在同样条件下的两个人,母亲受到过高等教育的来华留学生比母亲没有接受过高等教育的学生成绩平均要低将近一档。但是,这一结果似乎不太符合大众预期,通常父母受教育水平越高其后代的受教育水平应该越高,但是考虑到受访样本是来华留学生,并且主要生源地多为发展中国家就可以理解了。来自这些国家和地区的留学生,其国内的受教育程度普遍相对比较低,而来自母亲接受过高等教育的家庭,意味着该生大概率来自该国相对精英阶层的家庭,因此家庭条件相对较好,来自家庭条件比较好的学生其学习刻苦的动力普遍比来自相对贫困家庭的学生要低。
5) 师生互动情况较多的来华留学生比师生互动情况较少的来华留学生成绩要高。根据结果,师生互动情况程度每多1分,该生成绩则提高约0.33分。这个结论初看上去似乎违反了认知常识,通常师生互动越频繁的学生,学习自主性越强,学习越刻苦,成绩应该更好。但是在本模型中,师生互动情况对成绩却有显著的负面影响。其实对这一结论产生质疑的原因是忽略了受访者的身份。本文所研究的对象是在京来华留学生,他们最主要的特点就是具有外国人身份,母语多数非汉语或英语。因此,所有师生互动频繁的学生他们具有的最显著特点就是他们可以和学校教职员工进行相对较流畅的沟通,因此这些学生的汉语能力相对较好。而从实际教学经验来看,对于来华留学生而言,本科生普遍汉语能力要比硕博研究生高。除了入学语言考试标准严格之外,日常分班及教学实际情况也给予本科来华留学生更多的汉语学习和实践机会,因此多数本科来华留学生汉语能力显著高于其他学历层次学生。但另一方面,由于多数本科来华留学生学习汉语时间短,而本科期间多数课程为公共基础课(如:高等数学、大学物理、化学等),这些课程对于中国学生而言都比较难学,更不用说使用非母语学习的来华留学生了,因此本科来华留学生普遍成绩较低。而硕博研究生课程则多数以专业课为主,同时硕博研究生有一定的专业基础,因此硕博来华留学生的成绩相对较高。因此这也就合理解释了师生互动频繁的学生成绩反而低的原因。
5. 结论与讨论
本文分析了26个国家的北京高校来华留学生学习成绩与影响因素。通过分层模型(HLM)的分析认为对于具有层次结构的数据应当使用分层模型来分析,不然将会造成估计结果的有偏。总体来说,高校来华留学生学习成绩的国别特性和个人特性对成绩所造成的影响是能够被分解的。本文通过对学生个人成绩影响模型中国别因素变量的分离解释了不同国家间学生成绩差异的11%。通过随机截距模型的分析,在个人层面上,主动合作学习、师生互动程度、母亲教育水平对来华留学生成绩有显著影响。在国家层面上,各国人均GDP增速也对学生成绩有显著影响。
因此本文得出如下两个结论:1) 从提高学校来华人才培养质量的角度出发,应适当加大对来华留学人员的资助力度,以吸引学有余力且具有相当研究潜能的贫困国家和地区学生能够来华接受高等教育,提高来华生源质量。2) 从高等教育服务国家大外交战略角度来看,目前我国来华留学生的汉语教育需要加快改革的步伐。为了完成培养知华、友华和爱华的国际人才这一外交目标,同时也为了在国际高等教育这一市场中凸显我国的教育主权,高校应当有责任培养大量的懂中文的国际人才。而目前我国来华留学生的汉语水平离我国的战略目标还有一定距离,来华留学生的汉语水平需要进一步提高,因此我国需要完善一系列配套方案从而加快来华留学生汉语教育改革。