1. 引言
盈利能力能够体现企业利用现有资源获利能力,其强弱能体现一个企业经营管理情况及未来发展前景,是一个企业赖以生存的基础。通过对盈利能力分析能够了解目前企业的运行状况、发展状况以及暴露出来的一系列问题。所以,盈利能力分析对于企业及其所在行业发展都有着重要的现实意义。近几年,虽然房地产行业发展有所波动,但仍然是关系国计民生的重要行业,随着中国城镇化以及人口流动加剧,对住宅的需求将逐步加大,因此对房地产企业的发展现状有一个更好地了解,才能对行业发展有更好地把握。京沪深三地在中国属于发达地区,房地产企业众多,发展迅速,把握这三地的房地产企业发展可以对整个行业的发展有一个整体的认识。
关于企业盈利能力的研究,国外开始的较早。Venkatraman和Ramanujam (1987) [1] 认为企业盈利能力是一个包含三种绩效模式的多维度结构:财务绩效;商业绩效,包括与增长和份额相关的部分,以及与公司来来地位相关的部分;组织效能,包括与质量相关的部分,以及与社会责任相关的部分。Robert Kaplan和David Norton (1992) [2] 提出的平衡记分卡提供了一个关注管理过程的框架,其最大特点就在于不仅仅是各种财务指标和非财务指标的综合体,而且通过因果关系将盈利能力评价的四个方面紧密地联系起来。Akhmedjonov和Balciizgi (2015) [3] 研究了资本规模对土耳其银行盈利能力的影响,在研究过程中用到了最小二乘等分析方法,结果表明二者存在明显的影响关系。
国内学者侧重于利用各种方法建立盈利能力评价体系,比如利用因子分析法、回归分析法提取指标的主要信息。种镇国、莫中杰(2010) [4] 利用因子分析法对房地产上市公司2009年反映盈利能力的财务与非财务指标进行了实证分析并较为准确地分析出了房地产行业的盈利水平。王曼舒、刘晓芳(2013) [5] 通过对14家上市银行在2008~2010年间的季度数据进行面板分析,通过回归模型得出了净息差对企业的盈利能力影响较小的结论,并指出银行要提高盈利能力除了做到降低成本外,还要优化收益结构,只有这样,才能提高发展质量。也有利用层次分析法从多方面综合评价盈利能力的大小。王吉恒、王天舒(2013) [6] 以万科三年的财务数据为例,通过层次分析法建立企业盈利能力评价体系,为盈利能力指标赋予权值,进行了实证分析。
目前,利用盈利能力分类模型进行分析的较少,同时在研究范围方面,多以某一家上市公司的财务数据为例进行分析或者对于某地区的部分企业进行分析,很少有学者将京沪深三地的房地产上市公司放在一起做实证研究。为此,本文在已有研究的基础上,采用随机森林对京沪深三地57家房地产上市公司的盈利能力进行实证分析。首先,对57家房地产上市公司盈利能力进行一个等级划分;然后,用随机森林训练一个盈利能力分类模型;最后,由盈利能力分析结果,为房地产行业发展提供政策建议。
2. 理论阐述
随机森林 [7] 指的是利用多棵决策树对样本训练集进行训练并预测的一种分类器,在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数决定。在预测的时候,输入一个样本,每个决策树都会给出一个预测结果,根据所有决策树的预测结果的众数来确定样本最终的类别值。在生成随机森林的过程中,每一棵决策树都是通过一个独立抽取的样本建立的,决策树之间的相关性会影响最终误差,因此要尽量保证决策树之间不相关。
随机森林构建的具体步骤如下 [8] :
1) 输入参数:原始训练集样本的个数
,变量的数目
,节点分类变量
;
2) 用自助抽样法有放回地随机抽取
个自助样本集,根据自助样本集,构建
棵决策树,每次未被抽到的样本组成了
个袋外数据,即简称OOB;
3) 在训练的过程中,自助样本集逐渐生成一棵棵决策树,在每个节点处,随机选取
个特征值中的
个(
小于
),随后从
个特征中选取一个特征进行分支,此过程要保证结点不纯度最小,直至每个节点不纯度达到最小;
4) 生成多个决策树分类器,输入需要预测的元组,每个决策树都给出了一个分类结果,根据所有决策树的分类结果得出最终的类别。
随机森林的优点如下 [9] :
可以处理高维度的数据,并且不用进行指标的选择;模型训练完毕之后,也可以得出数据每个指标的重要程度;模型的训练速度很快,并且可以进行并行化操作;最小化了决策树之间的相关性,所以模型的分类精度较高,与决策树相比,可以产生高精度的分类器;在训练过程中可以很好地估计缺失值,因此缺失值对分类模型的准确率不会产生很大影响。
随机森林的缺点如下 [10] :
对于噪声较大的数据进行分类时,随机森林可能会产生过拟合现象从而影响分类的结果;对于低维度数据,可能不能产生很好的分类。
3. 京沪深房地产上市公司盈利能力实证分析
3.1. 指标选取及数据获取
根据科学性、全面性、可得性和同向性的指标选取原则 [6] ,选取的指标包括:每股收益、毛利率、营业利润率、成本费用率、净资产收益率、总资产利润率、总资产净利率。
本文所用到的所有房地产公司盈利能力指标数据均来自中信证券股票交易软件中2017年的财务指标数据。
3.2. 盈利能力分级
在对盈利能力进行分级的时候,以往的方法忽略了异常值的影响,当存在特别大或者特别小的指标值时,会使分级结果不合理,故本文利用分位数进行分级,这样分级使每个级别的公司数量比较均衡,避免了偏大和偏小的异常值的影响。首先对于各个指标进行分级,每个指标被分为三类,指标分级之后,再根据7个指标对房地产公司盈利能力进行分级。对于每个指标,提取4分位数,以每股收益为例:
每股收益:1/4分位数0.14,3/4分位数0.38;将每股收益小于0.14的称为每股收益为弱,在0.14-0.38的为中,在0.38以上的为强。同时,对于每个等级赋予一个分数,强:5分,中:3分,弱:1分。依次类推,其余6个指标都予以相同的处理,分界点如表1所示。

Table 1. Quartile of the indicator
表1. 指标的4分位数
将7个指标进行等级划分之后,计算得到每个公司的盈利能力得分,如表2所示。
根据每个公司的得分,将盈利等级分为三类:强、中、弱。最高得分
,最低得分
,计算盈利能力等级分界点 [11] :
,
将小于等于16的盈利等级定为弱,在17~25之间的定为中,大于25的定为强,各等级的公司数量如表3所示。
Table 3. Number of companies with various profit levels
表3. 各个盈利等级的公司数量
据此,我们分地区统计不同盈利等级的公司数量,见表4。
Table 4. Number of companies with different profit levels in each region
表4. 各地区不同盈利等级的公司数量
从等级划分结果可以看出:在北京的18个房地产上市公司中,盈利能力被判定为强的只有3个,仅占北京地区房地产上市公司总数的16.7%,而盈利能力为弱的上市公司为7个,占总数的38.9%。可见与深圳上海相比,北京的房地产上市公司盈利状况最差。三地中房地产上市公司盈利状况最好的地区为上海,盈利能力被判定为强的占到了36%,而被判定为弱的仅占到了18%。而深圳地区房地产公司的盈利情况介于北京和上海之间,盈利能力被判定为强的与弱的都各占到了29%。
近年来,为了满足北京地区的人口增长,北京地区的房地产过度开发,价格持续攀升,而随之带来的是投资减少、发展空间小、增长缓慢等一系列问题,导致北京地区的房地产上市公司盈利状况不佳,但是也有部分表现良好的公司。
上海地区的房地产就有很大的投资前景,上海地区作为全球性的大都市经济、政治、文化协同发展,各个方面的发展都比较全面。2016年,上海GDP总量达2.75万亿,全国城市排名第一。此外,第三产业的增加值占比70%以上,产业结构合理。因此,上海地区不仅经济经济发展迅速,发展质量也有所保证。稳定并持续发展的经济环境更加有利于房地产行业的快速稳定发展,因此上海地区的房地产上市公司的盈利能力也尤为突出。
深圳地区房地产上市公司盈利能力表现良好,近几年深圳经济发展迅速,房地产行业也在发展中稳步前行,2017年较2016年相比深圳地区商品房投资以及销售额有所下降,但仍然在行业中处于领先地位。
3.3. 随机森林盈利能力分类模型
在确定了公司盈利等级以后,利用样本数据建立随机森林盈利能力分类模型,用于判断公司盈利等级。我们将原始数据分为训练集与测试集两部分,在京沪深三地57个房地产上市公司中以其中40个作为训练集,训练随机森林盈利能力分类模型,其余17个为测试集,用于测试随机森林盈利能力分类模型的精度。
在盈利能力分类模型的训练过程中,有两个参数要首先确定好:节点分类指标个数、随机森林中决策树的个数。以上两个参数是构建随机森林盈利能力分类模型中的两个重要参数,也是决定随机森林盈利能力分类模型预测能力的两个重要参数。
首先,确定利用训练集训练随机森林盈利能力分类模型时决策树节点分类指标个数。分类指标一共有7个,从1个指标开始,逐个测试,找出误差最小的指标个数。利用R软件进行操作,决策树用系统默认值,得到预选指标个数与误差值关系,如表5所示。从表5可以看出,节点指标数为2时,误差最小,因此取节点分类指标个数为2。
Table 5. The relationship between the number of classification indicators and the error
表5. 分类指标个数与误差的关系
然后,需要确定第二个重要参数:随机森林中决策树个数。使用R软件的绘图函数绘制决策树个数与分类误差的关系图,如图1所示。图1中列出了三个等级“强”(good)、“中”(mid)、“弱”(bad)各自在预测的时候,决策树数量与误差的关系,同时有总的“预测结果”(total)。可以看出,决策树在300棵以前,误差非常不稳定,在300棵以后所有预测误差均趋于稳定,而且误差基本降到最低。
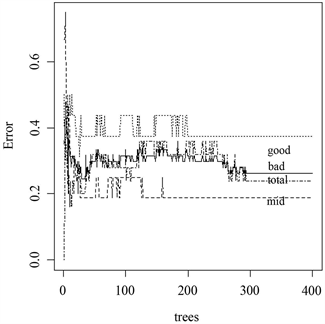
Figure 1. The relationship between the number of decision trees and the error
图1. 决策树数量与误差的关系
基于以上分析,取节点分类指标数为2、决策树数为300棵构建随机森林盈利能力分类模型。然后,利用测试集的17个京沪深房地产上市公司盈利能力指标数据进行分类准确率测试,最终测试结果如表6所示。
从测试结果可以看出,盈利能力为强与中的公司被很好预测出来,没有误差,盈利能力为弱的四个中有一个被错误地预测为弱,17个测试样本预测准确率94%,说明所构建模型准确率较高,能可靠预测京沪深房产上市公司的盈利能力。
3.4. 重要性分析
由于分类指标有7个,目前并不知道那个指标对于盈利能力等级划分重要。所以,利用R软件中的随机森林包确定影响盈利能力的重要指标,重要性度量见表7。
表7中,精度平均减少值与节点不纯度平均减少值都是测量分类指标重要性的重要指标,两个值越大,代表分类指标越重要,即对于京沪深房地产上市公司盈利能力等级划分的影响也就越大。根据各个指标的精度平均减少值与节点不纯度平均减少值,对盈利能力影响大小从高到低依次为:净资产收益率、营业利润率、成本费用率、总资产净利率、总资产利润率、毛利率、每股收益。
Table 7. Indicator importance measure
表7. 指标重要性度量
净资产收益率、营业利润率与成本费用率这三个指标对于京沪深三地房地产上市公司处于什么样的盈利等级有着重要影响,对于房地产上市公司盈利能力的划分占据主导地位。同时,提高利润总额、净利润,降低营业成本对于提高房地产上市公司的盈利能力至关重要。因此,在实际操作中就要求企业完善管理运营机制,提高生产效率,采用科学合理的营销方案,使每一单位成本所带来的收益最大化,从而提高企业盈利能力。
4. 政策建议
基于本文的结论,并结合目前房地产上市公司的盈利能力现状,对房地产行业发展提出如下建议:
1) 坚持宏观调控方向
目前,在国家宏观政策调控的大背景下,房地产行业发展下行,房地产投资放缓,但是房地产作为刚性需求,政策因素稍有变动,房价仍然面临高速增长的趋势。所以,国家政府有关部门对于房地产行业的调控政策必须坚持实行,同时还要保证经济的持续平稳发展,从而有效抑制房地产投资过热,控制房价,杜绝炒房。
2) 加快实施房地产税收制度改革
房地产的税收制度改革对于房地产市场的调节非常重要。首先,要以降低政府干预为原则,以市场化为导向,在此基础上建立起完善的税收制度。推进房产税的实施,从而使房地产市场达到一种供需平衡的状态,通过税收的调节控制房价,使房地产市场能够健康发展。
3) 上市公司进驻三四线城市,开发有潜力的地产
目前,京沪深三地房地产上市公司开发房地产以一线城市以及发达的二线城市为主,这些发达地区的房产已经被过度开发,发展空间小,要注重三四线城市的房地产建设,这些地区多数处于高速发展阶段,发展基数小,要将这些地区的房地产潜力开发出来,不但能在很大程度上提高公司的盈利能力,促进公司发展,而且最大化房产公司的盈利潜力,从而很大程度上促进整个行业的发展。
致谢
本论文的完成离不开各位老师、同学和朋友的关心与帮助。在此要感谢各位老师针对论文所提出的宝贵意见,还要感谢同门的师兄师妹们,在科研过程中给我以许多鼓励和帮助。回想整个论文的写作过程,虽有不易,却让我除却浮躁,经历了思考和启示,也更加深切地体会了所学专业的精髓和意义,因此倍感珍惜。
基金项目
山东科技大学研究生导师指导能力提升计划立项项目(KDYC17018),山东科技大学专业学位研究生教学案例库建设项目(SKDYAL17010)。
参考文献