1. 调研背景及意义
2020年9月22日,习近平主席在第七十五届联合国大会一般性辩论上提出中国将提高国家自主贡献力度,采取更加有力的政策和措施,明确将碳达峰时间点提前至2030年前,并争取在2060年前实现碳中和。相比2015年提交的国家自主减排贡献(NDC)方案,新目标不仅提升了碳强度的峰值要求,还将非化石能源比重的目标由20%提高至25%,森林蓄积量目标由45亿立方米增加至60亿立方米。这些新的承诺体现了中国在全球气候治理中展现的更大担当,彰显了中国作为一个负责任大国的国际形象。
从区域层面来看,西北地区在双碳目标及碳排放管理中具有显著的区位特征和资源优势。其丰富的太阳能、风能等可再生能源资源为大规模绿色能源开发提供了得天独厚的条件。广阔的土地资源适宜建设大型光伏电站、风电场和储能设施,助力清洁能源输出。作为“一带一路”核心区域,西北地区在特高压输电和能源协同发展中扮演着关键角色,为实现“西电东送”和全国能源结构优化提供了重要支撑。此外,通过推动新能源技术创新与生态修复协同发展,西北地区不仅能够为全国碳中和路径提供科学支持,还将成为引领绿色发展的排头兵,为全球气候治理和可持续发展贡献中国智慧和中国方案。
现有研究主要针对内地及沿海地区能源和碳排放的研究,对西北地区的调查研究较为缺少,故为弥补西北地区能源和碳排放研究空白领域,展开本次研究。
2. 调研内容
2.1. 研究内容
调研西北地区双碳目标动力学研究及碳管理路径,主要围绕国家和政府机构的官方数据与学术科研开源数据展开 [1] 。通过收集国家能源局、生态环境部及西北地方政府发布的能源规划、碳排放统计、政策文件 [2] [3] 等权威数据,掌握西北区域能源结构、排放现状及政策实施效果。同时,依托高校及科研机构的开源数据集 [4] - [15] ,如能源经济模型、碳排放监测数据库与生态评估报告,深入分析技术路径、西北区域发展潜力及创新应用案例。这些数据来源权威、科学、公开透明,为全面评估西北地区的双碳实践与战略优势提供了坚实的基础。
在对陕西省、甘肃省、青海省、宁夏回族自治区、新疆维吾尔自治区进行初步搜集数据 [16] 的过程中,发现地方延迟数据更新,尤其新疆维吾尔自治区的能源类数据仅更新到2020年,因此在下文预测评估过程中,为保障统一性和时效性,从2021年对各项指标预测来保障一致性,而已有数据作为参数代入来保障一定时效性。后续将会根据国家统计局和各省统计局数据更新完善模型。
2.2. 研究思路
为研究不同西北区域产业发展、经济等因素对西北区域碳排放量的影响,需要对基础数据进行分类筛选处理,可从西北区域动力学角度出发,划分产业能耗、能源构成多个类别,以构建描述经济、人口、能源消费量和西北区域碳排放量的综合指标体系,考虑对原数据进行处理,使用多元统计分析方法,如灰色关联分析等,分析西北区域人口、经济等对西北区域碳排放量的影响因素与其贡献,对路径差异化进行设计选择,对西北区域数据进行探索分析,量化指标间关联关系模型,寻找其内在西北区域动力学机理,将双碳政策和技术进步等多重效应纳入模型中,通过对模型参数的调整来预测未来碳排放量,考虑到能源利用效率提升和非化石能源消费比重等因素的影响,来探究碳排放预测模型的参数,本研究的技术路线图如图1所示。
要实现能源消费量的预测,需要对西北区域历史的人口数据、GDP数据、能源消费量数据和碳排放量数据等进行分类处理,分析历史数据的趋势和关联性,了解人口、经济和能源消费量之间的关系,以及能源消费量与碳排放量之间的关系。分别建立能源消费量预测模型、碳排放量预测模型,通过使用统计方法如线性回归、指数增长模型等来预测未来的人口和经济的变化,设置2035年和2050年作为中国式现代化的两个时间节点,建立人口与能源消费量之间的关系模型。可以使用每人能源消费量指标来预测未来的能源消费量。得到符合建模输入标准的数据。将数据集划分为训练集与测试集,可采用修正的LSTM算法来对西北区域碳排放量进行有效预测。使用历史数据中的一部分作为训练数据,利用建立的模型进行预测,并与实际数据进行比较验证模型的准确性和可靠性。
2.3. 模型假设
模型假设:1) 2035年的GDP比基期(2020年)翻一番;2060年比基期翻两番;2) 假设2060年生态碳汇的碳消纳量为基期碳排放量的10%;3) 2060年工程碳汇或碳交易的碳消纳量为基期碳排放量的10%。
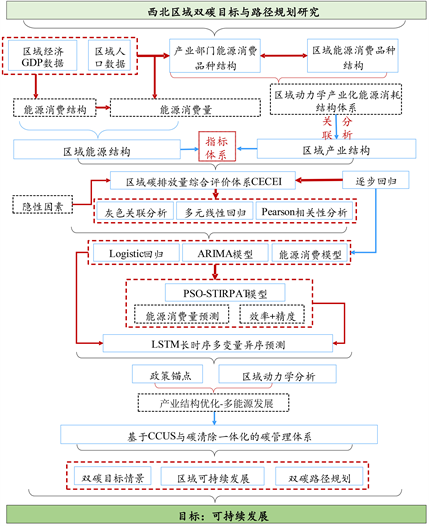
Figure 1. Full-text research and research technology roadmap
图1. 全文调研与研究技术路线图
本研究相关定义与符号如表1所示。

Table 1. Definitions and symbolic descriptions
表1. 定义与符号说明
3. 调研分析
3.1. 西北区域碳排放综合评价指标架构建立
1、指标确立
确定评价碳排放量以及经济、人口、能源消费量的主要维度,这些维度通常包括经济维度、社会维度和环境维度,通过主要维度构建西北区域碳排放综合评价的结构体系,通过西北区域碳排放等相关数据,对西北区域内碳排放综合评价指标的结构体系架构进行分产业部门划分,各产业部门分别由不同的能源消耗构成,然后细分为发电、供热、其他加工转换、损失、其他消费六个子类。
在结构体系搭建完成后需为每个结构维度选择核心指标,这些指标应能够全面反映该维度的状况。例如,对于经济维度,核心指标可以包括GDP (国内生产总值)。对于人口维度,核心指标可以包括总人口等,对于环境维度,核心指标包括总碳排放量、总能源消费量等,对于产业部门构成,包括第一产业、第二产业、第三产业的能耗量和生活能耗量,对于能耗构成,包括化石能源能耗、非化石能源能耗,对于能耗品种,包括能源主要利用目的。
核心指标下仍存在可细分子类,因此制定衍生指标,部分衍生指标是基于核心指标和其他相关数据计算而来的指标,用于更详细地描述特定方面。经济和人口存在潜在相关性,因此需要考虑人均GDP、人均GDP变化等指标;同时碳排放量也与人口存在潜在相关性,需要考虑人均碳排放量、人均碳排放基准变化率;从总碳排放量派生出碳排放强度,即单位GDP或单位人口的碳排放量,以便比较不同西北区域之间的环境效率。
基于上述分析,可以得到如下西北区域碳排放综合评价指标架构的结构体系与指标体系架构图,如图2所示。
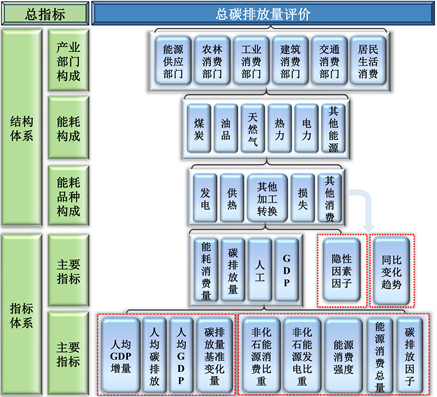
Figure 2. Framework of carbon emission assessment system in Northwest China
图2. 西北区域碳排放评价体系架构
2、指标分析
针对结构体系与指标体系细分指标子类,可形成三级指标体系:主要维度(一级指标)、核心指标(二级指标)、衍生指标(三级指标),具体分类如下表2所示。
Table 2. Classification of three-level index system for comprehensive evaluation of carbon emissions in Northwest China
表2. 西北区域碳排放综合评价三级指标体系分类
3、建模分析
1) 综合评价指标
首先,根据上表确定的三级指标,确定与经济、人口、能源消费量和碳排放量相关的指标,构建用于衡量西北区域碳排放状况的综合评价指标方程:
其中,CECEI (Carbon Emission Comprehensive Evaluation Index)为西北区域碳排放综合评价指数值,CECEI值越高,说明西北区域碳排放能力越强;
为第i个指标层相对权重;
、
、
、
分别为对应的西北区域经济、人口、能源、碳排放指标,第i个指标层第j个评价指标的相对权重;
为第i个指标层第j指标的评价值;
为西北区域碳排放隐性因素,主要为政府政策隐性系数。先利用各细化指标具体量化值乘以其对应权重算出指标层指数,再根据得出的指标层指数乘以其对应权重得出准则层指数,最后进行归一化处理得到碳排放指数CECEI,通过CECEI值高低对西北区域数据中碳排放现状进行具体评价。
2) 灰色关联分析
针对区域内碳排放差异形成因素,结合不同部分子指标,建立碳排放灰色关联度模型,验证不同影响因素对不同区域碳排放作用的差异性。
式中,
为灰色相关系数,
为目标列,
为输入列,
为分辨系数,一般为0.5。
3) 皮尔逊相关性分析
Pearson相关系数,又称积差相关系数,是表达两变量线性相关程度及方向的统计指标。样本的相关系数用符号
表示,总体相关系数用希腊字母
表示。计算公式为:
其中:
,表示X的离均差平方和;
,表示Y的离均差平方和;
,表示X与Y的离均差平方和。
对西北区域碳排放量的影响因素进行求解可以得到如图3所示的结果。
4) 多元回归分析
对区域碳排放影响因素建立多元线性回归模型,确定模型的函数形式,包括截距项和交互项。使用选定的多元回归模型来拟合数据。通常,最小二乘法是拟合模型的常用方法,它旨在最小化观测值和模型预测值之间的残差平方和。
其中,
为回归系数,在多重线性回归中,被称之为偏回归系数,表示每个自变量都对y部分产生了影响,反映的是x对y的影响力,是当x每改变一个观测单位时所引起y的改变量。这里e是样本的预测值与测量值的差别,
是总体中预测值与真实值的差别。y预测值的变异性是解释变量x能够预测和解释的。
通过对数据进行归一化处理,将区域碳排放量影响因素进行以上关联性分析,将考虑以产业结构、能源结构、总指标等多种情况下的因素关联,分别计算输出结果。
5) 计算结果
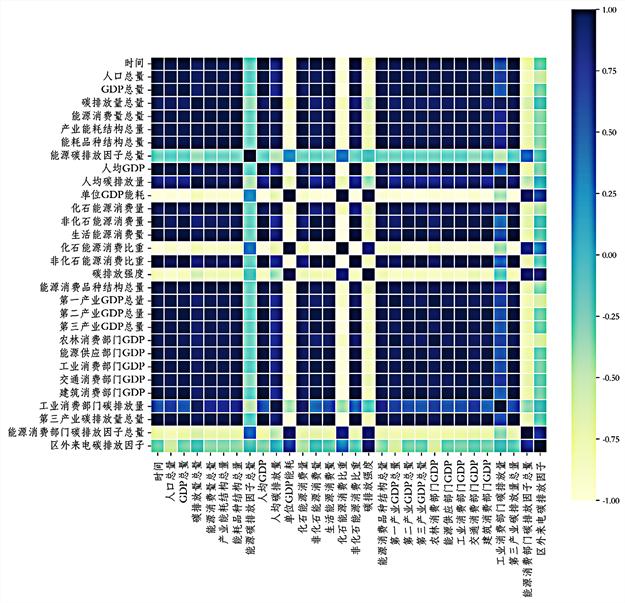
Figure 3. Thermal map of influencing factors of carbon emission in Northwest China
图3. 西北区域碳排放量影响因素热力图
Table 3. Top five correlation analysis results of carbon emission evaluation total index in Northwest China
表3. 西北区域碳排放量评价总指标排名前五关联分析结果
Table 4. Analysis results of the top five correlation rankings of industrial energy consumption structure
表4. 产业能耗结构关联排名前五分析结果
Table 5. Analysis results of the top five correlation rankings of energy consumption variety structure
表5. 能源消费品种结构关联排名前五分析结果
通过表3~5的结果分析可知,总体来看,2010~2020年间,随着经济的持续增长,碳排放量呈逐年增长态势;从碳排放的产业结构看,第二产业是主要的碳排放来源;从影响因素看,人口和经济增长是碳排放增长的主要驱动因素;非化石能源消费比重有所提高,对碳排放增长起到一定抑制作用;能源消费品种结构中其他新能源总量影响较明显,产业能耗结构中工业消费部门热力消费量较多,单位GDP碳排放量和单位GDP能耗总体呈下降趋势,表明能效提升对碳排放增长也具有抑制作用,可知该区域实现碳达峰与碳中和的主要挑战为产业结构优化与提升非化石能源利用程度与能源利用效率。
3.2. 基于PSO-STIRPAT的能源消费量预测模型
考虑能源消费量受人口数量、经济等的影响,首先预测人口数量,采用Logistic回归分析,Logistic回归分析是一种广义的线性回归分析模型,自变量既可以是连续的,也可以是分类的。通过Logistic回归分析,可以得到自变量的权重,从而预测某种事件发生的可能性。基于人口增长预测的调研,人口增长率一般情况下呈对数形式增长,基于Logistic回归模型建立人口预测模型,按照时序关系进行参数自回归,测试结果如图6所示,预测结果如下图7所示,由测试结果可知,该模型置信度较高,可针对“十四五”至“二十一五”进行人口数量预测。
为预测到2060年的能源消费量,采用
模型:
其中,
是时间序列
的当期值,即代表能源消费量值,
是
前一期的值,以此类推。
是自回归系数,p是自回归阶数,
是移动平均系数,q是移动平均的阶数。p、q采用自相关系数(ACF)、偏自相关系数(PACF)来确定,d为差分的次数。模型建立的基本步骤为:
本文选取2010年~2020年间西北区域的能源消费量,设
为西北区域平均能源消费量序列。本文选取2010~2018年西北区域的能源消费量数据作为训练数据,2018~2020年的数据作为验证数据,创建ARIMA模型,具体步骤如图4所示,并进行向前预测,进行数据序列图的绘制,如图5所示。
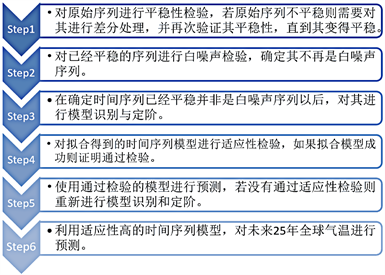
Figure 4. Step diagram of time series model
图4. 时间序列模型步骤图
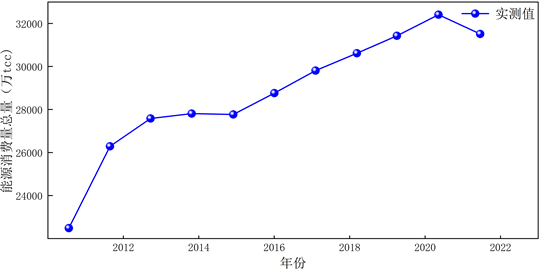
Figure 5. Time series data of total energy consumption
图5. 能源消费量总量时间序列数据
该模型中的一个随机时间序列可以通过一个自回归移动平均过程生成,即该序列可以由其自身的过去或滞后值以及随机扰动项来解释。如果该序列是平稳的,即它的行为并不会随着时间的推移而变化,那么就可以通过该序列过去的行为来预测未来,这也正是随机时间序列分析模型的优势所在。由于GDP随时间平稳变化的规律特点,结合模型的机理约束性建立了时序的GDP预测模型。该模型测试结果如图6所示,预测结果如图7所示,由测试结果可知,该模型可针对“十四五”至“二十一五”进行GDP总量预测。
碳排放研究中常使用IPAT及衍生的ImPACT和STIRPAT模型、LMDI因素分解法、环境库次涅茨曲线以及其他研究方法。其中,IPAT模型表达形式简单,且人口、经济水平和技术的弹性系数均是1,不能体现出不同驱动因素的区别。STIRPAT模型通过对数变换和回归分析对其中的参数进行估计,之后基于情景设置能源消费量,能够体现多参数之间的相互作用:
式中:I表示二氧化碳排放量;P表示人口规模;A表示人均GDP;U代表城镇化率;IS代表产业结构;EI代表能源强度;ES代表能源结构;a为模型系数;b、c、d、g、h分别为变量的弹性系数。
同时针对模型参数寻优采用PSO粒子群搜索方法,兼顾了搜索效率及搜索精确度,基于人口预测模型与GDP预测模型双输入方式建立PSO-STIRPAT方法,以预测“十四五”至“二十一五”期间的能源消费量。
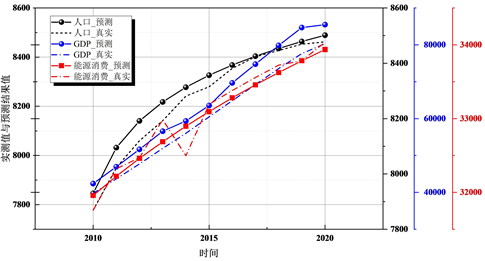
Figure 6. Prediction results of training set based on Logistic/ARIMA/PSO-STIRPAT model
图6. 基于Logistic/ARIMA/PSO-STIRPAT模型的训练集预测结果
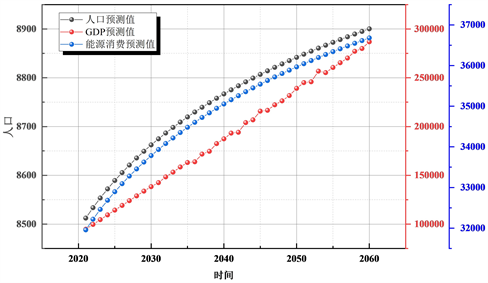
Figure 7. Prediction results of verification set based on Logistic/ARIMA/PSO-STIRPAT model
图7. 基于Logistic/ARIMA/PSO-STIRPAT模型的验证集预测结果
预测结果如图6、图7所示,由图6测试结果可知,该模型性能较好,在保证准确度的同时提高了搜索效率。图7预测西北地区在2060年能源消费将达到38,000万吨。
3.3. 基于LSTM多变量异序网络的西北区域碳排放量预测模型
1、基本数据提取
非化石能源发电占比(表示能源脱碳的指标)数据提取:能源提供部门负责当地供电,承担着当地用电的能源转化,其中产电的来源由表格数据可知有煤炭、油品、天然气及其他能源,因此:非化石能源发电占比 = (能源供给部门其他能源消耗量) ÷ (能源供给部门煤炭 + 油品 + 天然气 + 其他能源消耗量),可得2010~2020年非化石能源发电占比数据。
间接碳排放口径(如图8所示):由能源供给部门产出的电力与热力供给间接形成了碳排放,其中各能源消费部门热力全部由当地供能部门提供,基于各部门热力碳排放不同的碳排放因子可计算热力造成的间接碳排放口径;电力间接碳排放由当地能源供给部门、外地调用电力、新能源供电提供,由于外地调用电力与当地消费部门的电力碳排放因子不同,需要各自计算间接碳排放量 [17] 。
图8. 间接碳排放
2、算法优选及模型建立
考虑到西北碳排放的预测模型与人口和GDP相关联的同时,寻找参数之间的内在联系,挖掘多参数之间的内部非线性关系、输出时间序列下的多参数结果,本问题采用基于LSTM的长时序多变量预测模型(图9)。该模型异序输入输出时间序列,考虑到政策变化以五年计划为准,模型步长设置为五,输入参数为人口、GDP、能源消费量、非化石能源消费比重等,五年数据为一个输入输出序列,例如2011~2015为输入序列,2016~2020为输出序列。预测结果如图10所示。
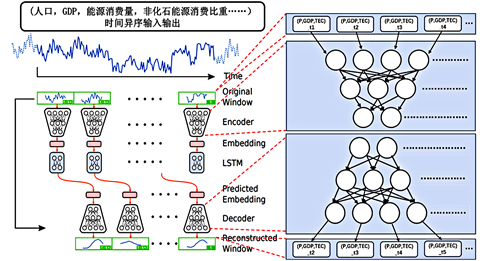
Figure 9. Structure of LSTM time out-of-order network model
图9. LSTM时间异序网络模型结构
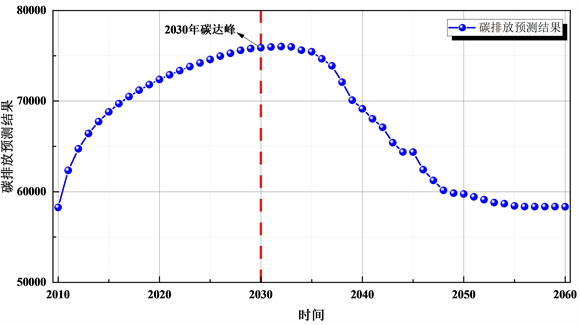
Figure 10. Prediction results of carbon emissions
图10. 碳排放预测结果
预测发现,西北地区并没有按照双碳目标计划如期完成碳达峰,而是会延期2~3年,并达到76,000万吨的峰值。
4. 建议
为了帮助西北地区如期实现双碳目标,在双碳目标实现路径规划中,需要注重以下几点:首先,制定科学合理的GDP、人口和能源消费目标值,明确提高能源利用效率和提升非化石能源消费比重的具体措施,通过能效提升、产业升级、能源脱碳和能源电气化等多维度路径实现减排目标,如图11所示;其次,新能源开发应注重多元化布局和互补策略,如图12所示,避免单一依赖某一类能源,尤其是在新能源技术尚未完全成熟的情况下,需要加强技术研发和储能技术支持,确保能源系统的稳定性和可靠性。
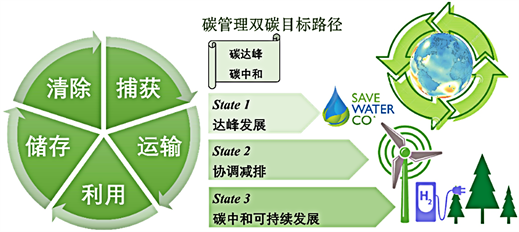
Figure 11. Path planning of carbon management and double carbon target
图11. 碳管理双碳目标路径规划
图12. 多能源利用
5. 模型评价
5.1. 模型优点
对数据进行了剔除、补齐和无量纲化处理,可以有效解决数据缺失、离散给建立模型带来的问题。
在对区域碳排放量进行预测时,评估了多种预测模型,对比后选择LSTM时间序列进行预测,并进行了适应性检验,从而达到高精度的预测结果。
模型建立基于理性分析和合理推导,对于所使用的重要原则给出了精确的定义和证明,对求解的过程进行了全面的分析和讨论,使得模型具有较多的理论支持。
5.2. 模型缺点
由于基于区域所建立的模型存在理想化状态,且存在经验模型及模型假设,适用性有局限性。
在探究不同双碳情景对区域可持续发展的影响时,未考虑全面隐性因素对区域碳排放及碳达峰、碳中和实现路径的影响,后续研究可开展相关的研究。
致谢
本研究在2022年度新疆维吾尔自治区“天池英才”创新领军人才计划(CZ000914)、2023年度石河子大学高层次人才科研启动项目(RCZK202323)及2024年度石河子大学国际科技合作推进计划项目(GJHZ202408)资助下完成。