1. 引言
乳腺癌是发生于乳腺上皮或导管上皮的恶性肿瘤,病因尚不完全清楚,其在全球女性癌症中的发病率为24.2%,位居首位,其中52.9%发生在发展中国家。研究表明,雌激素受体α亚型 [1] (Estrogen receptor alpha, ERα)在乳腺发育过程中至关重要。现阶段,抗激素治疗方法经常被用来帮助ERa表达的患者,它可以调节雌激素的受体活性从而达到控制体内雌激素水平的目的。ERα被认为是治疗乳腺癌的重要靶标,能够拮抗ERα活性的化合物可能是治疗乳腺癌的候选药物。
在药物研发中,通常采用建立化合物活性预测模型的方法来筛选潜在活性化合物。现收集一系列作用于ERa靶标的化合物及其生物活性数据,然后以一系列分子结构描述符作为自变量,化合物的生物活性值作为因变量,构建化合物的定量结构–活性关系(Quantitative Structure-Activity Relationship, QSAR)模型,然后使用该模型预测具有更好生物活性的新化合物分子,或者指导已有活性化合物的结构优化。
一个化合物想要成为候选药物,需具备的性质合称为ADMET (Absorption 吸收、Distribution分布、Metabolism代谢、Excretion排泄、Toxicity毒性)性质。为方便建模,本文仅考虑化合物的5种ADMET性质,分别是:1) 小肠上皮细胞渗透性(Caco-2);2) 细胞色素P450酶(Cytochrome P450, CYP) 3A4亚型(CYP3A4);3) 化合物心脏安全性评价(human Ether-a-go-go Related Gene, hERG);4) 人体口服生物利用度(Human Oral Bioavailability, HOB);5) 微核试验(Micronucleus, MN)。
本文基于2021年华为杯中国研究生数学建模竞赛D题提供的数据集,数据集内含1974个化合物数据、1974个化合物的729个分子描述符信息、1974个化合物的5种ADMET性质,构建化合物生物活性的定量预测模型和ADMET性质的分类预测模型,从而为同时优化ERα拮抗剂的生物活性和ADMET性质提供预测服务。
2. ERα生物活性数据的选择
要求变量对生物活性影响的重要性对729个分子描述符进行变量选择,可以认为是特征选择问题。因此本文选用基于样本相关系数的检验对729个分子描述符对生物活性影响的重要性进行打分,为防止分子描述符之间存在耦合关系,使用皮尔森相关性检验对按照重要度排序的分子描述符进行线性相关检验,最终选取前20个最具影响的分子描述符,其流程图如图1所示:
2.1. 皮尔森相关性分析
皮尔森相关系数(皮尔森Correlation Coefficient)常用来衡量两个数据集合是否在一条线上面,它用来衡量定距变量间的线性关系。本文假设729个分子描述符之间相互独立且对生物活性影响为线性,故皮尔森相关系数适用。
皮尔森相关系数可以定义为:
式中:
表示两个变量之间的差值,
表示样本大小。
皮尔森相关系数衡量的是线性相关关系,若
,说明两者无线性相关关系;
越大,相关性越强,
越接近于0,相关度越弱。统计学中对相关性强弱有着如下约定,如表1所示:
将皮尔森相关系数的阈值设为0.6,再基于前面筛选下的变量,计算两两变量间的皮尔森相关系数,然后判断两者的相关系数是否大于所设阈值。若大于,则说明两变量相关性高,对两变量之间贡献值排名靠后的那一变量采取删除操作。若小于,则说明两变量间并不强相关,则将两变量都暂时予以保留。之后重复上述操作,直至遍历结束。完成后,根据分子描述符含义解释,对强耦合变量进行手动剔除,最后保留对生物活性最具影响的前20个分子描述符见表2,以及它们之间的皮尔森相关系数热力图见图2:

Table 2. Final selection of molecular descriptors
表2. 最终选择的分子描述符
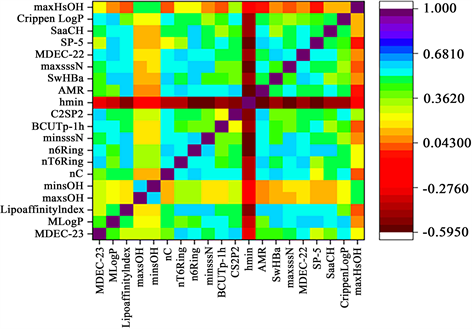
Figure 2. Correlation of selected molecular descriptors relative to biological activity
图2. 选择的分子描述符相对生物活性的相关性
2.2. 基于遗传算法优化的BP神经网络预测模型
2.2.1. 线性预测与非线性预测模型
现结合问题1选择不超过20个分子描述符构建的化合物对抑制ERα生物活性的预测模型,50个化合物进行IC50值和对应的pIC50值预测。
一个化合物想要成为候选药物,一般需要具备良好的生物活性,常用做法是针对与疾病相关的某个靶标(此处为ERα),收集一系列作用于该靶标的化合物及其生物活性数据,然后以一系列分子结构描述符作为自变量,化合物的生物活性值作为因变量,构建化合物的定量结构–活性关系(Quantitative Structure-Activity Relationship, QSAR)模型,然后使用该模型预测具有更好生物活性的新化合物分子,或者指导已有活性化合物的结构优化。而由于分子描述符众多,且涉及到的方面较复杂,因此考虑同时采用线性和非线性的预测模型来建立以分子描述符构建的化合物对生物活性的预测模型,根据最终表现来评估模型,其思路如图3所示:
2.2.2. BP神经网络模型
BP神经网络属于前向神经网络,强调网络采用误差反向传播的学习算法。其包括一个输入层、若干隐含层和一个输出层组成。其核心思想是通过样本训练集,不断修正神经网络的权值和阈值,逐步逼近期望输出值。其输入层与输出层关系如图4:

Figure 4. Neural network I/O layer diagram
图4. 神经网络输入输出层关系图
根据本题数据,建立的BP神经网络模型初始输入为20个变量,输出层为预测值,含有5个隐藏层,神经元个数分别为50,100,50,100,50,其中输入层值为X,即20个变量。
目前主要有三种常用的激励函数:Sigmoid、Thah和ReLU激励函数。ReLU使得SGD的收敛速度比Sigmoid和Thah快很多,使过程计算量减少,此外还解决了梯度消失问题。出于此种考虑,本文最后采用ReLU (Rectified Linear Uni)激励函数作为本神经网络的激励函数。
选用Python编写程序进行神经网络训练。设置最大迭代次数为1000次,期望误差与学习速率均设置为软件自适应寻优,该网络训练完成后,只需将各项主要变量值输入网络即可得到预测数据。
2.2.3. BP神经网络模型求解
建立BP神经网络模型后,经过求解得出50个化合物进行IC50和对应的IC50值。本文将数据分为两个部分,75%用于训练,25%用于模型测试,测试结果及训练LOSS如图5所示,拟合结果如图6所示:
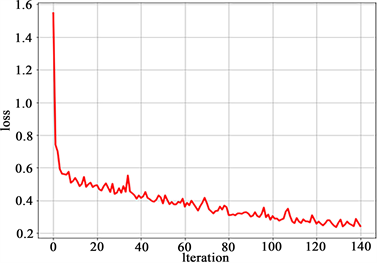
Figure 5. Neural network LOSS diagram
图5. 神经网络LOSS图
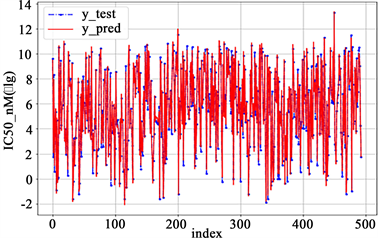 (a)
(a)  (b)
(b)
Figure 6. Curves of true and fitted values (left IC50_nM (take l g) right pIC50)
图6. 真实值和拟合值曲线(左 IC50_nM (取l g)右pIC50)
通常用神经网络结果的均方误差(MSE)和真实值R来判断神经网络模型的预测精度。均方误差(MSE)是预测值和真实值之差的平方和的平均值,MSE值越小,该模型的预测精度就越高。真实值R反映了预测模型的拟合程度,R越接近1效果越好。分析图6可得误差分析结果可得BP神经网络的均方差等于0.03212,其判定系数R为0.9605,是想要的预测结果。
3. 基于支持向量机(SVM)的ADMET性质分类预测模型
现需要根据729个分子描述符,针对提供的1974个化合物的ADMET数据,分别构建化合物Caco-2、CYP3A4、hERG、HOB、MN的分类预测模型,50个化合物进行相应的预测。基于此,本文建立K近邻分类、决策树分类、随机森林分类三种分类预测模型进行分类预测,并在运行中进行评分,从而保证结果的准确性。
K近邻 [2] (K-Nearest Neighbour, KNN)是一种基本分类方法,通过测量不同特征值之间的距离进行分类。K近邻的思路是:如果一个样本在特征控件中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中k通常是不大于20的整数。
决策树 [3] (Decision Tree)是一种基本的分类与回归方法,当决策树用于分类时称为分类树,用于回归时称为回归树。分类树是一种描述对实例进行分类的树形结构。在使用分类树进行分类时,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点。这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分到叶结点的类中。随着划分过程不断进行,决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
随机森林 [4] 就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。每棵决策树都是一个分类器,那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的Bagging思想。
最后采用k近邻分类、决策树分类和随机森林分类对Caco-2、CYP3A4、hERG、HOB、MN进行的分类结果如表3所示。
Table 3. Classification results of three models for Caco-2, CYP3A4, hERG, HOB, MN
表3. 三种模型对Caco-2、CYP3A4、hERG、HOB、MN分类结果
注:① 表示k近邻分类;② 表示决策树分类;③ 表示随机森林分类。
结果如表3所示,三种模型的结果非常接近,其中不同结果的按照模型的正确率作为主要条件来综合评估。
4. 模型建立及寻优求解
4.1. 优化多目标问题
现优化目标为,需要找出一些分子描述符在某定值或者取值范围内,既能够使化合物对抑制ERα具有更好的生物活性,同时具有更好的ADMET性质(给定的五个ADMET性质中,至少三个性质较好)。本题属于回归问题,可以理解为既要保证好的生物活性,同时至少要具有三个好的ADMET性质,即遴选出合格的分子描述符,在Caco-2、CYP3A4、hERG、HOB、MN五个指标至少有三个为1的前提下,生物活性尽可能好,由于生物活性主要看pIC50值,pIC50值越大说明生物活性越高,因此把这个值看做寻优目标,其求解过程如图7:
现遴选出20个相对目标较为重要的变量,同时同线性模型与非线性模型两个角度出发来构建模型,选择弹性网络回归(ElasticNet)与BP神经网络来对比解题。
4.2. 模型建立
考虑到建模目标发生改变,普通线性回归模型可能因为没有加入惩罚项问题而产生较差拟合效果,而弹性网络回归则解决了这一问题,原因在于线性回归损失函数基于最小二乘法的:
在无法权衡到底是L1还是L2正则化对参数更新更为有利的时候,便需要在ElasticNet中加入L1和L2正则化项:
考虑到数据是具有非线性的,于是仍使用表现良好的BP神经网络同时求解该题。
4.3. 模型求解与评价
本文利用Python科学计算库自带的网格搜索(GridSearch CV)函数来求解ElasticNet回归模型,它存在的意义就是自动调参,在小数据集下,只要把参数输进去,就能很快给出最优化的结果和参数。它其实是一种贪心算法:拿当前对模型影响最大的参数调优,直到最优化;再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。这个方法的缺点就是可能会调到局部最优而不是全局最优,但是省时间省力,GridSearch CV用于系统地遍历多种参数组合,通过交叉验证确定最佳效果参数。在此基础上,最终通过计算,发现模型在学习率为0.01的情况下效果最好。
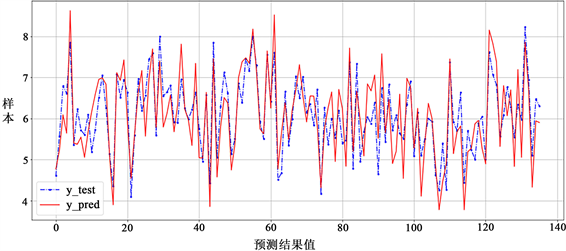
Figure 8. ElasticNet model fit vs true
图8. ElasticNet模型拟合值与真实值
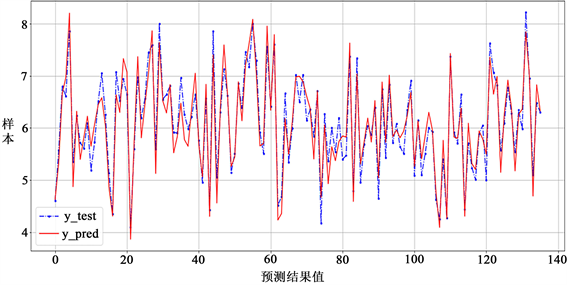
Figure 9. Fitted value and true value of BP neural network model
图9. BP神经网络模型拟合值与真实值
图8和图9分别为ElasticNet模型和BP神经网络模型的拟合值与真实值,蓝色点划线为从样本变量中预留的25%的数据,红色为模型的拟合值,从图中可以看出两种模型均取得了较好的成绩,通过表4对比两种模型的均方误差、平均绝对误差以及判定系数r2值,发现两种模型的均方误差均较小,符合要求,ElasticNet回归模型平均绝对误差远大于BP神经网络模型,且BP神经网络判定系数高于ElasticNet回归模型,说明BP神经网络模型拟合度更好。因此,相比于ElasticNet回归模型BP神经网络模型表现更好。

Figure 10. BP neural network model loss function
图10. BP神经网络模型损失函数
Table 4. Two model evaluation forms
表4. 两种模型评估表
如表5中所示,给出两种模型寻找的20个分子描述符在表6中的取值获得的生物活性以及ADMET性质,并且可以认为当化合物的分子描述符在这两种结果的取值范围内时,不仅能够使化合物对抑制ERα具有更好的生物活性,还能同时至少具有三个好的ADMET性质,满足要求。
Table 5. Calculation results for both models (select molecular descriptors)
表5. 两种模型计算结果(选择分子描述符)
Table 6. Two model evaluation forms
表6. 两种模型评估表
5. 总结与分析
1) 本文首先根据样本相关系数的检验对729个分子描述符对生物活性影响的重要性进行打分,并使用皮尔森相关性检验对按照重要度排序的分子描述符进行线性相关检验,最终得到了前20个最具影响的分子描述符。
2) 筛选出20个对生物活性影响最重要的分子描述符,数据最大为1974 × 20,数据量相对中等,故采用具有非线性映射能力的BP神经网络来建立生物活性预测模型针对主要变量与生物活性之间复杂的关系,选用BP神经网络机器学习算法,同时数据集与测试集分开,所得到的结果最大相对误差很小,所建立的预测模型精度表现优秀。
3) 第三步选用K近邻分类、决策树分类、随机森林分类三种分类预测模型进行分类预测,从而保证结果的准确性。结果显示,三种模型的结果非常接近,其中不同的结果均以模型的正确率作为主要条件来综合评估。
4) 最后同时从线性模型与非线性模型两个角度出发来构建模型,经过对比分析,最终选择弹性网络回归与问题二中表现良好的BP神经网络来对比解题。结果显示,两种模型均取得了较好的成绩,通过对比两种模型的均方误差、平均绝对误差以及判定系数值,发现BP神经网络模型表现更好,计算得出两种模型寻找的20个主要分子描述符及获得的生物活性和ADMET性质,并且认为当化合物的分子描述符在这两种结果的取值范围内时,获得较好的分子活性和至少3个好的ADMET性质。