1. 绪论
1.1. 研究背景及意义
近些年,我国工业飞速发展,人们生活水平日益提高,使得他们对于日常出行的交通工具越来越重视。由于汽车的便捷性、价格逐渐能为消费者所承担,越来越多的人会购买汽车。这一现象可从我国快速增长的新车销量可窥。由新车市场所带来的二手车在汽车产业的重要性也逐渐提升。我国政府致力于规范二手车市场以及促进市场的合理交易,每年政府工作报告中都会提出关于促进二手车市场发展的相关政策。2018年,我国全面取消二手车限迁政策,促进二手车消费市场潜力释放 [1]。2021年两会期间,我国政府进一步提出取消对二手车交易的不合理限制。《关于推进二手车交易等级跨省通办便利二手车异地交易的通知》落地实施克服了二手车跨区域流通的困难,促进二手车交易秩序的规范化,极大地推动了我国二手车市场的发展,营造良好的交易环境 [2]。近五年来,我国二手车转移与新车注册登记数量比例由67%不断上升至111%,且二手车转移登记量远远超过新车注册的,这表明我国二手车市场的活跃程度日益增长。
在政府带头的多方共同努力下,我国二手车市场正处于发展阶段。根据中国汽车流通协会调查报告指出:2021年我国二手车累计年交易量为1758.51万辆,较去年同期增长22.62%,远超专家预计的二手车交易规模。2021年中国新车销量达2627.5万辆,二手车销量约为新车销量的1.5倍,达到发达国家二手车与新车流通量比例,这体现了我国二手车市场具有极大的发展空间和市场潜力 [3]。此外,中国汽车协会表示:“由于新车产能受限导致其销量处于萎缩状态,让二手车市场迎来量价齐升。估计2022年我国二手车交易量能超过2000万辆。” [4] 这些可观的数据都体现了我国二手车市场极好的发展前景。
但是,由于我国二手车市场起步较晚,仍存在一系列问题,主要如下:一,我国缺乏完整的评估体系和监督管理方法,消费者容易被不良商家欺骗购买车况坏且无保障的二手车。二,由于二手车自身的特殊性,可能出现高价烂车、交易流程不规范且售后服务不完善的问题。因此,本文基于我国二手车市场的发展前景和规模的预测,根据结论提出合理建议,能够促进二手车市场的发展以及带来经济效益,为我国汽车行业和经济发展提供新思路。
汽车是我国的支出产业之一,二手车销量是衡量中国二手车市场的一个重要指标,二手车市场的蓬勃发展对于我国的经济发展具有重要作用。但由于我国对二手车市场尚处于发展探索阶段,难以避免地是存在评价体系不透明、汽车质量参差不齐等问题,不利于二手车市场发展。如何定量分析影响二手车销量的因素与二手车销量的相关性,找出主要影响二手车销量的因素,并据此建立预测模型,准确预测二手车销量,了解未来二手车销量趋势,探索二手车销量隐含的信息,为二手车市场发展提供合理建议,防止盲目扩张出现产能过剩,促进二手车市场的稳步发展,与此同时也能够推动我国汽车行业成长与壮大。因此,本文的研究有一定程度上的理论价值和现实意义。
1.2. 国内外研究现状
近年来,二手车市场的发展前景广阔。本文基于国内外学者对二手车销量的研究文献,分别从指标选取和预测模型两方面进行综述。
至今,欧美国家二手车市场已达到成熟阶段,二手车市场的法律法规健全完善、新车市场与二手车车市场发展协调和二手车的售后服务完善等,促进了国外二手车市场繁荣发展,国外学者对于二手车销量评估体系和影响因素已经展开了较为系统的研究。
在20世纪初期,美国二手车市场是世界上最早出现的二手车交易市场,凭借优秀的历史、庞大的汽车产量、完善的法规和统一的市场定价,目前成为全球最成熟、最大的二手车交易市场。国外学者对于二手车销量的研究多采用机器学习的方法。Fu-Kwun Wang等人(2011) [5] 对中国台湾汽车销量与人均收入、汽车销量、CPI等影响因素进行建模分析。M Hulsmann等人(2011) [6] 运用时间序列分析和决策树两种方法,对德国和美国月度汽车销量数据进行预测,决策树的预测效果更好。Nitis Monburion等人(2018) [7] 运用随机森林回归、多元线性回归两种方法对德国电子商务网收集的二手车数据预测,随机森林回归误差更小。CK Puteri等人(2020) [8] 基于线性回归方法分析了印度尼西亚车龄、汽车行驶里程、颜色、变速器和汽车类型等多种影响因素,建立了二手车销量预测模型,准确率超过75%。
1) 预测方法
我国学者常用于预测的方法有回归分析法、BP神经网络模型等机器学习方法,时间序列分析法等。陈欢(2008) [9] 通过灰色理论并建立微分方程的预测模型,汽车销量预测拟合度高,能够提供相关决策保证。李任龙(2015) [10] 通过相关性分析确定对二手车市场影响最大的因素,运用灰色预测方法和回归分析方法预测二手车销量,提供战略帮助。宋福军(2016) [11] 对2000年至2015年中国汽车月度销量分别采用指数平滑法预测、ARIMA模型预测、BP神经网络模型,后者模型的预测结果最为理想。王书鹏等人(2019) [12] 基于2011年至2018年月度数据,运用BP神经网络机器学习方法,由于数据量偏少,导致预测精度一般。桂思思等人(2021) [13] 基于某一汽车品牌销量预测,采用整合移动平均自回归模型与线性回归模型相结合预测,为二手车研究提供了理论基础和建模参考。
2) 汽车销量影响因素
危高潮(2009) [14] 基于回归分析法得出与汽车销售量相关性较高的5个重要因素,分别是汽车产量、公路总里程、国民生产总值、石油消费量、居民收入。赵颖(2014) [15] 建立以钢材产量、人均国民生产总值、汽车平均市场价格、人均生活能源、私人汽车拥有量、燃料价格指数、营运载客汽车拥有量、公路里程共8个指标,通过主成分分析法预测我国汽车销量。杨庆斗(2020) [16] 分析9个可能影响汽车销量因素与汽车销量的相关性,均高度关联,分别建立了线性回归模型和BP神经网络模型,结果表明后者的预测精度更准确。
综上所述,国内外学者研究汽车市场及预测其销量大多采用回归分析、BP神经网络、随机森林等机器学习模型以及传统的时间序列分析。通过学者们的研究,易发现机器学习的方法用于预测销量的精度更加准确,但对数据量的要求更高;而选取因素主要有:人均国民生产总值、公路里程、钢材产量等与汽车销量息息相关的指标。
1.3. 研究框架
本文围绕我国二手车年度销量预测该问题展开研究,选取以灰色关联分析法为支撑,分析可能因素与销量的相关性,选择相关性高的数据进行预测,分别选用BP神经网络法和回归分析法预测,建立关于我国二手车销量的预测模型,根据结论提出建议,总体研究进程如下图所示。
第一部分为绪论,了解并分析二手车市场在我国的现状及发展前景,查阅二手车市场的相关文献,确定本文的研究思路和采用的方法。
第二部分为我国二手车市场现状,对二手车市场有大体了解。
第三部分为选用方法的理论描述,说明理论分析中的变量含义,方法的理论基础以及优缺点,便于后续的建模。
第四部分基于BP神经网络模型和回归分析法进行实证研究,预测我国二手车年度销量并分析结果。
第五部分根据前文建模得到结论,提出建议。
第六部分为总结与展望,反思与总结本文在研究过程的长处与不足,并查阅资料提出改进的方向。

2. 我国二手车市场现状
由于同样的预算可以买到性价比更高的二手车,因此大众对于二手车的接受程度也越来越高。由于自驾出行带来的便捷,越来越多的人够买汽车的意愿更加强烈。但是,在购买过程会发现同样的预算可以在二手车市场有更多的选择,能买到高配置的车型,性能和安全也有所保障。2018年全国两会期间,我国政府报告提出,“将新能源汽车车辆购置税优惠政策再延长三年,全面取消二手车限迁政策。” [15] 随着政府相关政策的落地带来更多的红利,二手车消费市场潜力得到释放,我国二手车交易量已连续18年持续增长,二手车市场发展前景广阔。
2019年全国交易量1492.3万辆,但由于疫情的影响,2020年二手车交易量为1434万辆,首次出现下滑趋势。根据中国汽车流通协会的调查报告,上一年我国二手车累计年交易量为1758.51万辆,这表明我国二手车市场保持良好发展趋势。二手车销量在我国汽车销量比重越来越高,对于发展二手车市场具有重要意义,能在一定程度上促进新车市场的发展,又能带动汽车相关行业的发展(图1)。

Figure 1. The sales volume of used-cars in China
图1. 我国二手车销量
虽然二手车市场越来越规范,但由于它在我国发展时间较短,市场机制不够成熟,仍存在以下问题:一是由于二手车的车况经过多方接手,容易致使二手车市场鱼目混珠,可能存在商家为了获利期满消费者的现象。在交易过程,商家无法掌握部分车辆的完整信息,二手车甚至还存在违章事故未处理等。由于消费者对于二手车的行情了解浅薄,就会容易上当被“坑”,买到低质量的二手车;二是评估体系不健全,由于各地评估标准不一、评估过程不够严谨,没有专业的评估设备和体系,商家为了获取更多的利润,会故意造成低价收高价售的状况。三是二手车售后服务问题,相比于新车,二手车的保修服务等可能会有所欠缺,若是商家不负责,买家为了更好的体验,可能会放弃二手车这个选择。
3. 理论基础
3.1. 变量解释
为了简化模型理论基础,做出如下符号规定:
3.2. 灰色关联分析
灰色关联分析法是衡量两因素关联程度的方法之一,它能够体现一个系统因素间发展态势中的相关和不同程度。原理是分析相对序列和比较序列的几何形状相似程度,通过它们的关联程度判断序列的联系是否密切。若曲线间越贴近,则表明序列间的灰色关联度越高,即因素间变化趋势的一致性更高。该方法对于分析的样本数量和规律没有严格要求,计算过程简单易懂,是分析因素间关联程度的常用方法之一。
第一步,在确定指标后,收集数据,从而确定评价体系,记参考序列的评价矩阵为D;若评价问题有m个对象,每一个对象对应n个指标构成,评价矩阵如下所示:
公式1
根据评价目的及指标情况,假设参考数列为
。
第二步,由于指标的单位含义不同,为了消除量纲,先对数据进行标准处理,得到标准化评价矩阵G,其中
为处理后的参考数列。
第三步,分别计算每个被评价对象的指标序列与原有参考数列对应元素间的绝对差值,如下:
公式2
第四步,确定最小的差值
第五步,根据公式计算出比较数列与参考数列在各个时刻(即曲线中的各点)的关联系数
:
公式3
第六步,计算灰色关联度
求比较数列与参考数列间关联程度的平均值,得到关联程度
:
公式4
3.3. 神经元模型
假设有
共n个输入层,其中
对应的权值为
,则将输入层分别与对应权值相乘求和:
记为
,则通过映射函数f映射,得到输出层
(图2)。

Figure 2. Illustration of the neuron model
图2. 神经元模型图示
神经元是BP神经网络的处理单元。BP神经网络由多个神经元构成,就其中单独的一个神经元而言,它接受来自其他n个神经元的输入信号,并根据两两神经元的权重传递信号,并对神经元接受的总输入值与阈值进行对比,通过激活函数的映射,输出结果。
激活函数是BP神经网络的重要组成部分之一,它能将神经元的输入过程映射到输出层。对于训练BP神经网络模型以及处理非线性函数,激活函数有无可替代的地位。
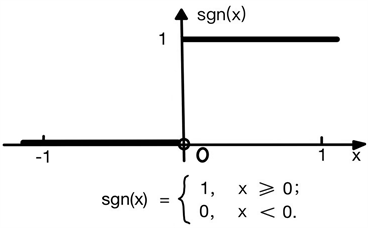
激活函数有阶跃函数和Sigmoid函数。阶跃函数能使得输出层结果离散,将输入值分别映射为数字0或1,分别代表神经元抑制和兴奋状态。
公式5
因为Sigmoid函数处处连续且可导,并且导数均比0大,它能将输入层的连续实值压缩在0和1之间(图3)。
公式6
 (a)
(a) 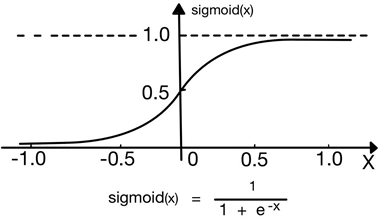 (b)
(b)
Figure 3. Sgn function & Sgimoid function
图3. Sgn函数及Sigmoid函数
3.4. BP神经网络理论
BP神经网络是Rumelhart和McCelland等学者研究提出的,由输入层、隐含层和输出层构成,分别有n、q、m个节点。通过激活函数处理以及反向传递不断调整对应的权值和阈值,当网络的输出误差平方达到设定的要求停止。
BP神经网络包括三层,分别是输入层、隐含层和输出层。公式推导如下。从输入层到隐藏层:
公式7
公式8
从隐藏层到输出层:
公式9
公式10
则输出
为l维向量。
BP神经网络模型能在原有的信息量少、数据量有限、不确定性的问题下进行学习训练,不被非线性模型限制。但在模型的使用过程,也需要注意如下问题。
1) 节点数
神经网络模型的节点数选择没有统一的标准,只能通过经验得出的公式来确定计算公式如下,通常采用第一种:
公式11
公式12
公式13
其中n和l分别为输入层、输出层节点数,a为0到10之间的调节常数。
2) 学习速率
为了确保模型在训练过程的稳定,模型的学习速率一般设置在0.01至0.8之间。
因此,BP神经网络模型能够解决复杂的非线性问题,在数据量有限的条件下,全局逼近网络,在预测方面得到广泛应用。
4. 基于BP神经网络的二手车销量预测
4.1. 指标选取
二手车是市场的重要商品之一,其销量会受到多方面影响。根据王旭文研究,遵循实际要求,主要将影响因素分为以下三类:一为经济发展水平,例如:人均GDP、居民人均可支配收入;二为汽车市场的影响,例如:私人汽车拥有量、新车销量、公路里程、钢材产量、橡胶轮胎外胎产量、汽车驾驶员人数。
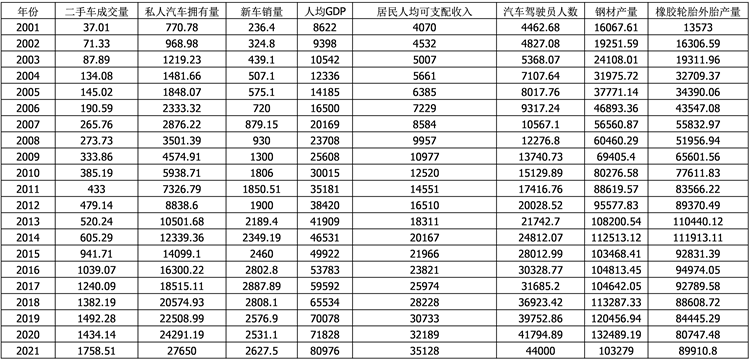
数据选取国家统计局官网(http://www.stats.gov.cn/)以及中国汽车流通协会官网(http://www.cada.cn/),但由于篇幅过大,原始数据在附录展示。
4.2. 灰色关联分析
运用MATLAB R2013对收集的原始数据进行灰色关联度分析,计算对二手车销量影响作用的大小,结果如下表1所示。
该表显示,本文选取的相关因素与二手车市场的关联度均大于0.5,总体两辆之间相关性高。
私人汽车拥有量与二手车市场的关联度最高,与实际一致,因为二手车的车源大部分来源于私人汽车,因此,私人汽车拥有量是至关重要的指标。汽车驾驶员人数关联度位次之,该人数的增加表示更多人要开车,买车的购买意愿会逐渐增多。紧接着是居民人均可支配收入和人均国民生产总值,这表明国家经济发展状况也会对二手车销量造成一定影响。二手车的前身是来自使用后的新汽车,因此新车销量的关联型较高。
本文选取关联度大于0.6的指标,分别是以下7个指标:私人汽车拥有量、新车销量、人均GDP、居民人均可支配收入、汽车驾驶员人数、钢材产量和橡胶轮胎外胎产量。
4.3. BP神经网络
本文将以我国二手车年度销量为研究对象,利用2001年至2021年共21年数据。由于样本数据量较少,训练集仅有21组学习样本,因此两层的BP神经网络已满足要求。
4.3.1. BP神经网络参数设置
1) 归一化处理
本文采用的软件是MATLAB R2013a,将21个数据按照9:1分为训练集和测试集,分别将7个指标构成的训练输入层和二手车销量训练输出层存放在P_train和T_train中,而测试输入层和测试输出层存放在P_test和T_test中。
为了消除量纲影响,保证训练效果更加准确,对所有的数据集归一化处理,在此处,运用MATLAB R2013a中自mapminmax函数将原始数据归一化处理,映射为(0, 1)之间的数,取消各维数据间的数量别差别,凸显指标的本质含义,也能防止出现大数吃小数的现象。
2) 建立BP神经网络模型
结合上述分析和多次参数的调试,建立模型。本模型包含输入层、隐含层、输出层。由于本文选取了7个指标,故输入层节点数为7个,输出层为我国二手车年度销量,输出层节点数为1。隐含层节点数根据经验公式(公式11)确定为4。经过调试,训练次数和学习速率分别为100次和0.01为最佳,具体参数如下。
4.3.2. 模型结果
BP神经网络模型对训练集进行学习,并将测试集带入测试,得到结果如下:由图4可知,本网络允许的迭代次数最大为100,实际仅迭代了5次,泛化能力检查在神经网络训练过程中始终为0,表明没有出现误差不降反升的情况。表明输出误差已在初始设定的范围内,停止训练。BP数据网络中最大误差为0.0643,设定的目标误差为0.00001,实际误差为2.19*10−7,表明该网络构建效果好,具有参考性。

Figure 4. The result of BP neural network
图4. BP神经网络训练结果
1) 真实值与预测值的描点图
如图5,真实值与预测值几乎接近一致,仍有个别数据误差较大,原因是测试数据较少导致,模型整体拟合预测效果较好。

Figure 5. Plot of true value and predicted value
图5. 真实值与预测值描点图
如图6所示,该网络训练过程中梯度为0.00049546,达到设定值,停止训练。训练迭代到5次的时候,动量因子为10−8。
2) 确定系数
R2是统计和数据分析中能够体现模型拟合优度的量,最大值为1,计算得出越接近1,拟合效果越好。本模型的确定系数如图7所示,训练集、验证集和测试集、训练集的相关系数R分别为1、0.99451、0.9969、0.99592,可知所有训练数据R2几乎接近接近1。误差均匀分布在zero线附近,这表明模型的拟合程度高,证明该模型能够很好地反应选取指标和二手车销量评估的关系。

Fiugre 7. Certain coefficient
图7. 确定系数
通过前面的网络训练,预测2019年至2021年我国二手车的年度销量,计算相对误差,如下表2所示。

Table 2. The prediction of used-car’s sales volume based on BP neural network
表2. 基于BP神经网络的二手车销量预测表
根据上表的相对误差数据,可得出BP神经网络模型的平均相对误差为2.4473%,这表明模型预测精度较高。在实证过程中发现,BP神经网络每次训练的结果不一样,查阅相关资料可知原因分别是输入样本是随机排列,导致输出值不一样;隐含层权值是随机赋予的。
4.4. 多元线性回归法
利用软件SPSS26,将2001年至2018年我国二手车销量数据进行多元线性拟合,结果如下:表格中显著性为0,远小于0.05。表明支持原假设,即线性回归方程显著(表3)。
a. 因变量:二手车成交量;b. 预测变量:(常量),橡胶轮胎外胎产量,私人汽车拥有量,新车销量,钢材产量,汽车驾驶员人数,人均GDP,居民人均可支配收入。
根据回归方程系数表(见附录)可得方程:
用方程预测2019年至2021年的我国二手车销量,预测结果如下表所示。相对误差十分大,BP神经网络法的误差小很多(表4)。
Table 4. The prediction of used-car’s sales volume based on multiple linear regression
表4. 基于多元线性回归的二手车销量预测表
5. 建议
针对我国二手车市场的现状,需要国家政府、相关部门和二手车车商等多方面共同合理,促进我国二手车市场的完善和壮大,保证消费者的合法权益,具体可以从以下措施去推进。
1) 建立二手车车况信息库
由于二手车自身的特点,车况存在不同程度的影响。因此,防止车商为了促进销量而篡改二手车车况,如:过户次数、变速箱、表显里程等指标。通过汽车监管部门、车商等多渠道合力,增加汽车信息的透明度,构建二手车数据库,使得二手数据真实可靠,促进二手车交易公平合理,保证消费者的合法权益,推动二手车市场发展。
2) 培训二手车评估师
相比于其他行业的从业工作者,对于二手车评估师的培训以及考核存在欠缺。为了保证现有评估过程更加公正,应该加强对二手车评估师专业知识的培训,使得二手车价格评估更加科学,能一定程度改善二手车市场鱼目混珠的情况。
3) 完善的售后服务
消费者之所以最终放弃购买二手车,是因为二手车的售后服务,相比于新车可能存在诸多麻烦。因此,可以借鉴西方国家的二手车售后服务经验,使消费者能够安心买二手车,权益也能够得到保障,敢于买二手车。
4) 充分利用电商平台
近些年来,我国电商平台发展快速且成熟。二手车市场可以利用电子商务平台自身存在的优势,减少一些可省的费用,如铺租、汽车保养等。此外,这也能够让消费者足不出户,货比三家,对二手车车况等有了解,推动二手车市场的发展。
6. 总结及展望
6.1. 总结
近几年,我国二手车销量飞跃增长,这也体现了越来越多的消费者购买二手车的意愿且二手车市场在我国的极好的发展前景,因此促进二手车市场发展以及协调好与新车市场的关系,进而推动我国重要支柱产业之一汽车蓬勃发展。伴随着人们消费观念的改变以及国家的政策法规引导,二手车市场在我国快速发展,发展势头猛。但至今为止,二手车在我国仍处于起步阶段,需要各方面配合努力。
本文总结阐述了我国二手车市场的现状,2021年,我国二手车年交易量为1758.51万辆,较去年同期增长35.34%,远超预计交易规模。在我国二手车年度销量预测问题中,采用了私人汽车拥有量等10个指标。根据灰色关联分析显示选用的指标与二手车销量有很高的关联度,选取关联度高于0.7的6个指标,作为BP神经网络的输入层,得到每年我国二手车销量的预测结果。神经网络模型三个数据集确定系数均超过99%,接近1,表明模型拟合效果很好。测试数据集与真实数据的相对误差为2.3595%、4.3524%、0.7199%,证明BP神经网络模型预测是合理的。
6.2. 不足和展望
本文基于BP神经网络模型对我国二手车年销售量预测效果较好,但是,二手车价值评估蕴含的信息量、影响因素都比较多,研究肯定还有不足之处,需要在以下几个方面继续加强:
1) 本文采用的数据是2001年至2021年我国二手车年销售量共21个数据样本,数据量较少,若获得更多的数据量,这才能使效果更加精准,结果更加可靠。
2) 本文仅采取了BP神经网络方法进行预测,应该多引入其他机器学习的方法进行预测,再比较效果,使得评估体系更加精准。
3) 本文根据文献采取7个影响二手车年销售量的指标,指标之间存在的相关性较高的问题,可以尝试加入一些其他因素改善模型的预测质量。
4) 该BP神经网络模型预测我国二手车年销售量精度高,但若要预测未来几年的二手车年销售量,需要预测7个指标的数据,并代入模型预测。
附录
原始数据
回归方程系数表